Quests
クエストActive Quest List / Archiving...

Be a Role Model, Not an Idol.
On having a sense of mission and responsibility.

Let's Build Robots! Annual Review After Graduating from AI Undergrad
Happy New Year 🎆

Building a Blog from Scratch: Do I Still Have the Passion?
Fulfilling a decade-old dream: building an SAO-themed blog and documenting the MDsveX writing syntax
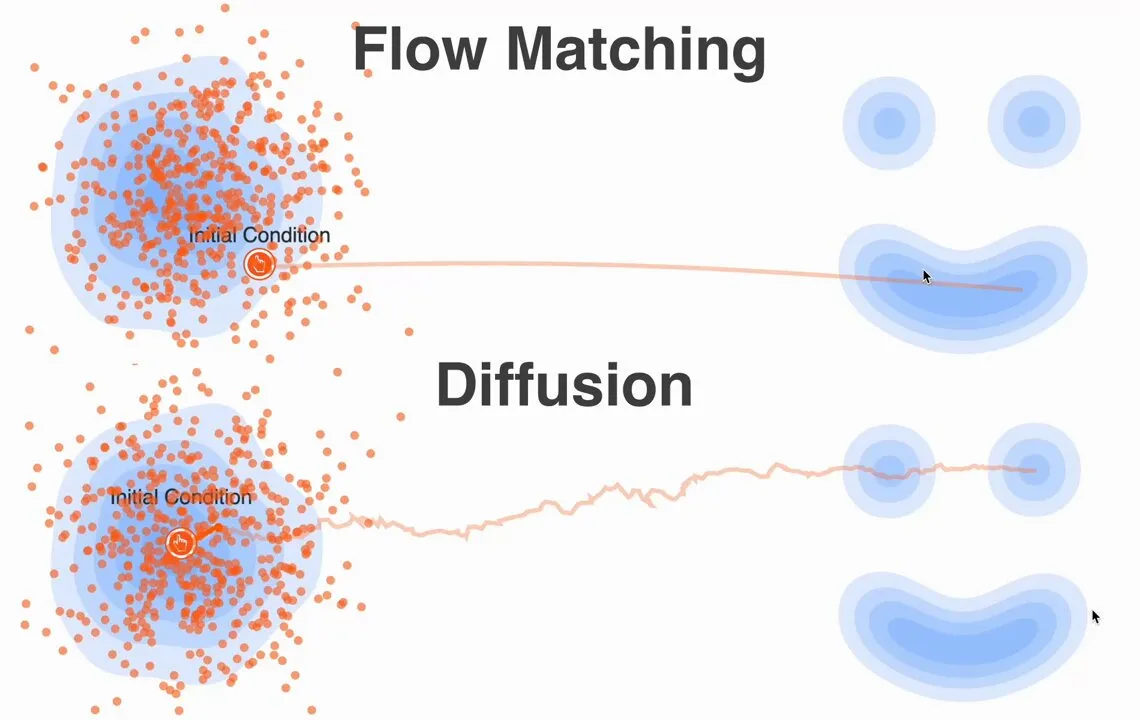
Ditching the SDEs: A Simpler Path with Flow Matching
Flow Matching gives us a fresh—and simpler—lens on generative modeling. Instead of reasoning about probability densities and score functions, we reason about vector fields and flows.

Visual Language Models, with PaliGemma as a Case Study
Thanks to Umar Jamil’s excellent video tutorial. Vision-language models can be grouped into four categories; this post uses PaliGemma to unpack VLM architecture and implementation details.
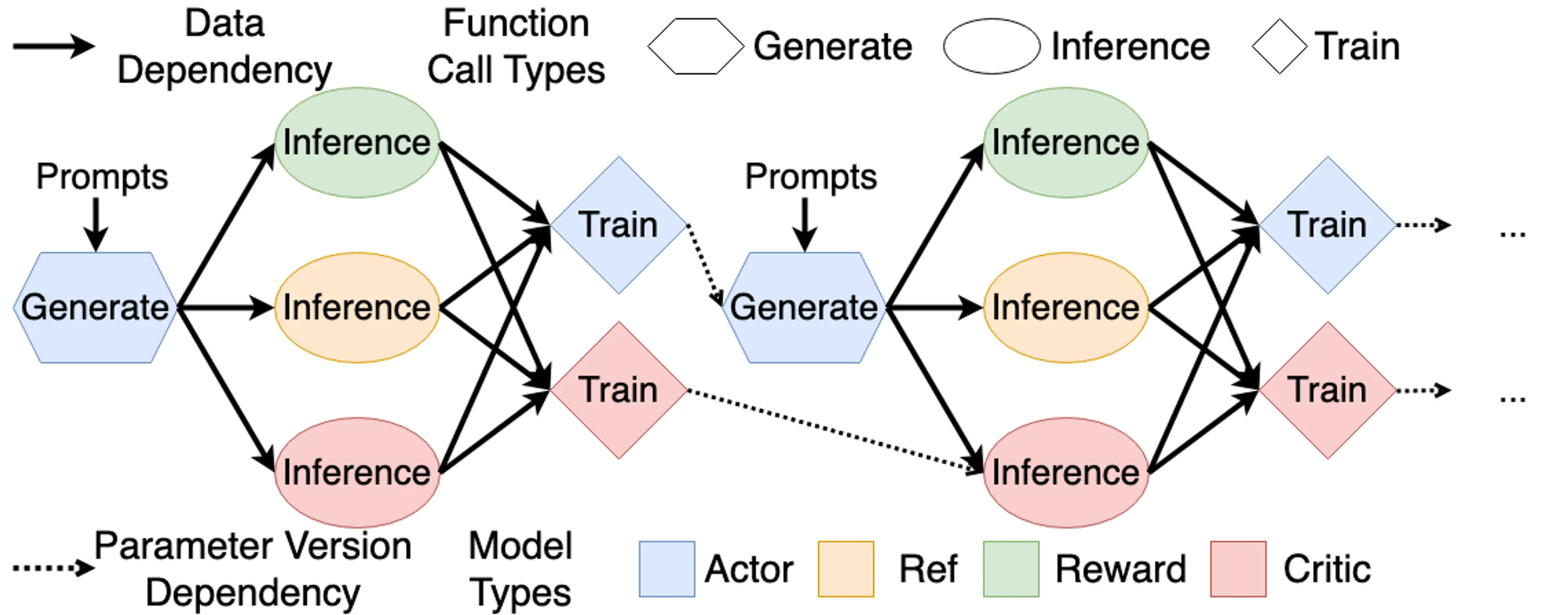
From RL to RLHF
This article is primarily based on Umar Jamil's course for learning and recording purposes. Our goal is to align LLM behavior with our desired outputs, and RLHF is one of the most famous techniques for this.

Implementing Simple LLM Inference in Rust
I stumbled upon the 'Large Model and AI System Training Camp' hosted by Tsinghua University on Bilibili and signed up immediately. I planned to use the Spring Festival holiday to consolidate my theoretical knowledge of LLM Inference through practice. Coincidentally, the school VPN was down, preventing me from doing research, so it was the perfect time to organize my study notes.

2024 Year in Review
2024 marked my first encounter with deep learning and my entry into the field of large models. Perhaps looking back someday, this year will stand out as one of many pivotal choices.

The Intuition and Mathematics of Diffusion
Deeply understand the intuitive principles and mathematical derivations of diffusion models, from the forward process to the reverse process, mastering the core ideas and implementation details of DDPM.
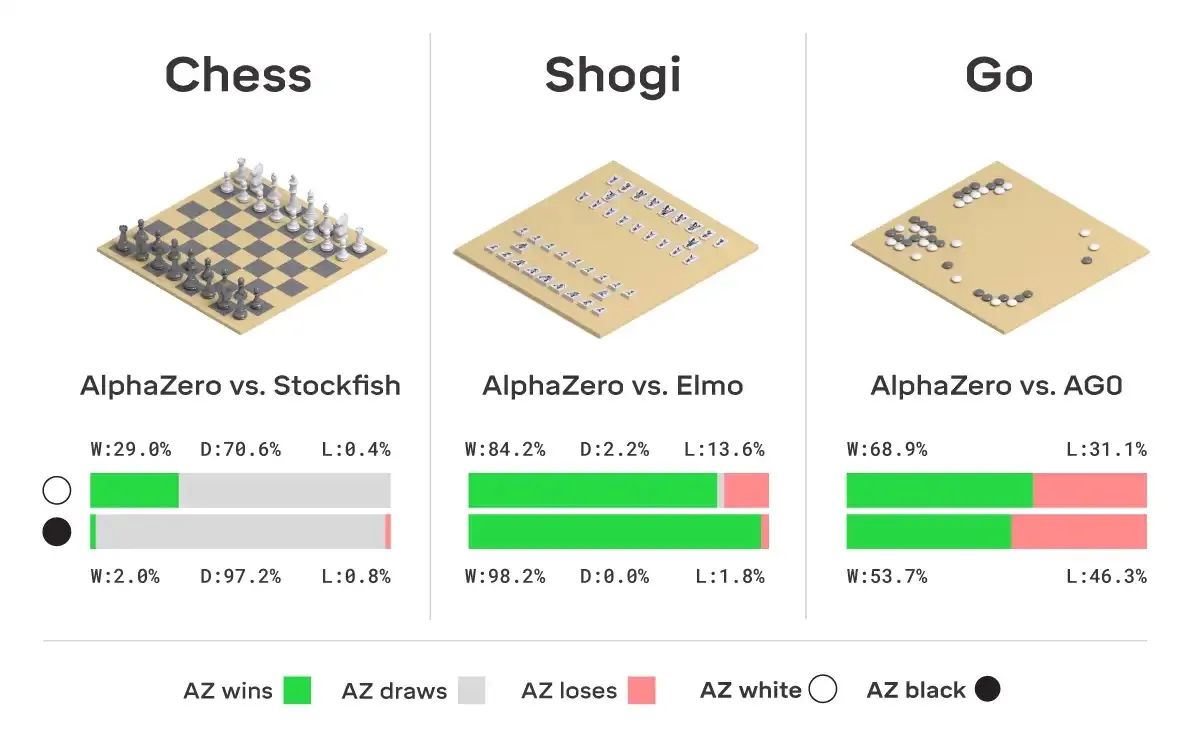
Let's build AlphaZero
Starting from the design principles of AlphaGo and diving deep into the core mechanisms of MCTS and Self-Play, we reveal step-by-step how to build an AI Gomoku system that can surpass human capabilities.

PPO Speedrun
Quickly understand the core ideas and implementation details of the PPO (Proximal Policy Optimization) algorithm, and master this important method in modern reinforcement learning.

Introduction to Knowledge Distillation
Learn the basic principles of Knowledge Distillation and how to transfer knowledge from large models (teachers) to small models (students) for model compression and acceleration.
The Journey of Cracking the Follow Invite Code
Documenting the full process of cracking a Follow invite code, learning about LSB steganography and the use of the StegOnline tool.
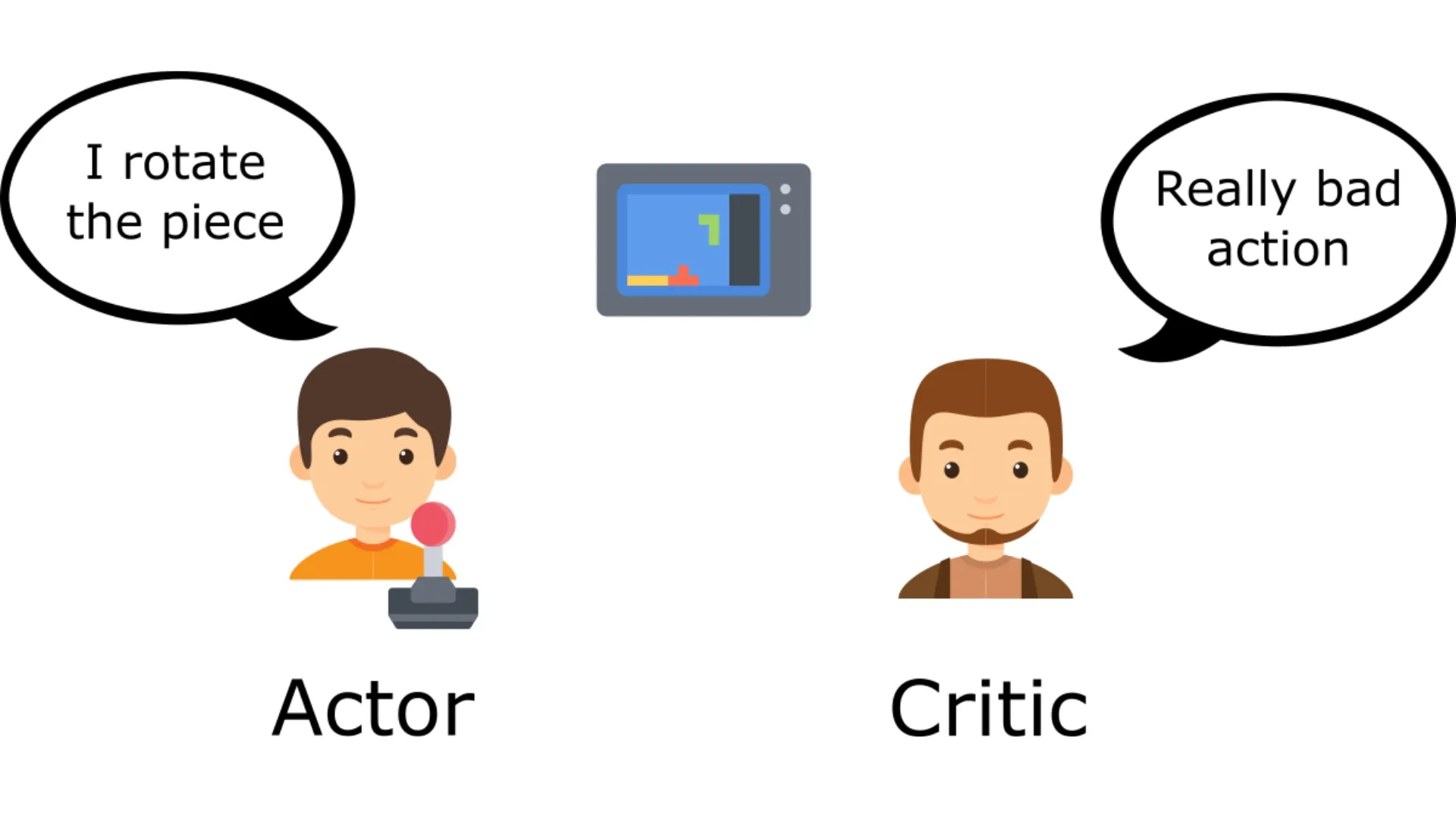
A First Look at Actor-Critic Methods
Exploring the Actor-Critic method, which combines the strengths of policy gradients (Actor) and value functions (Critic) for more efficient reinforcement learning.

From DQN to Policy Gradient
Exploring the evolution from value-based methods (DQN) to policy-based methods (Policy Gradient), and understanding the differences and connections between the two.
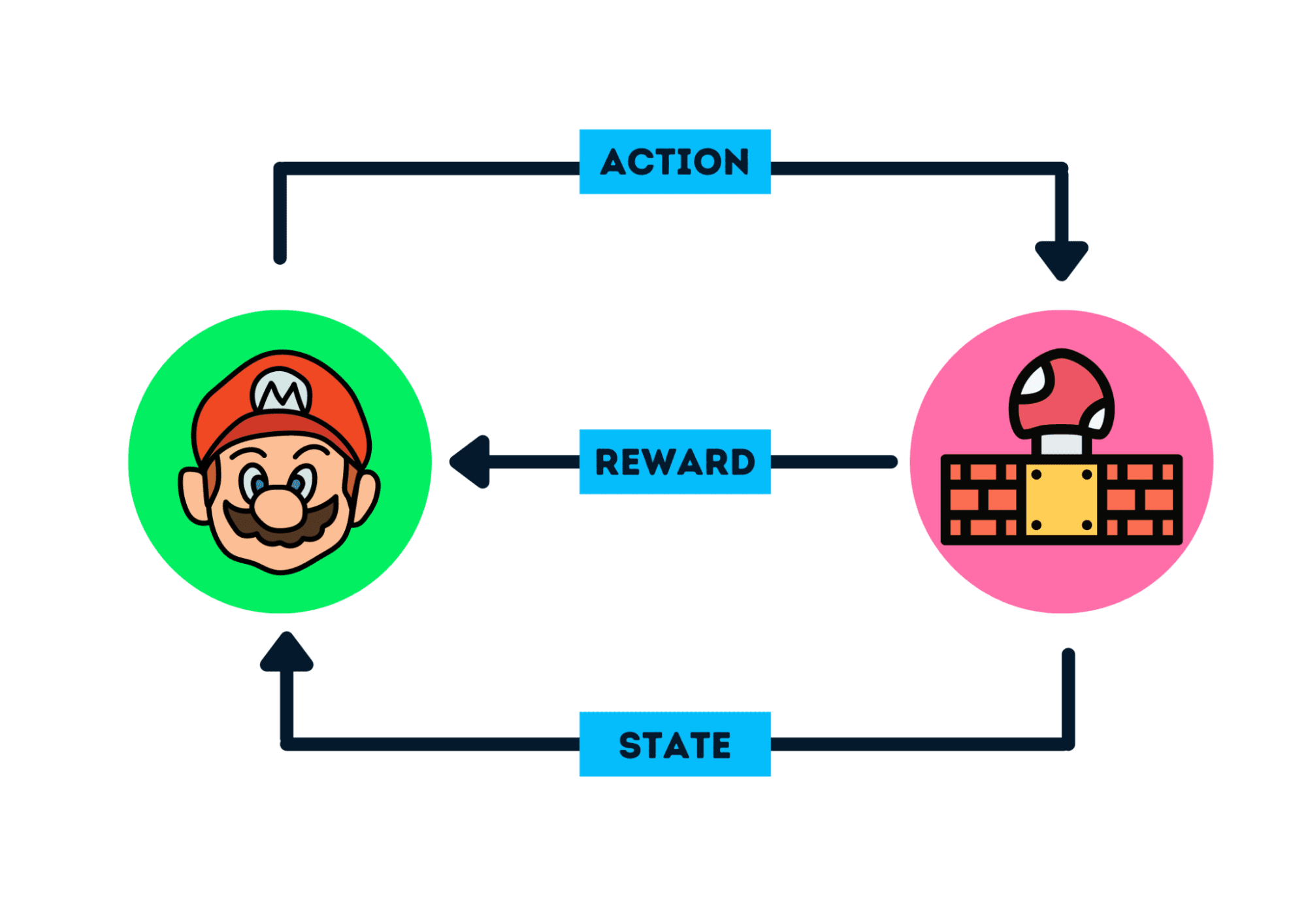
Reinforcement Learning Basics and Q-Learning
Learning the fundamental concepts of Reinforcement Learning from scratch, and deeply understanding the Q-Learning algorithm and its application in discrete action spaces.
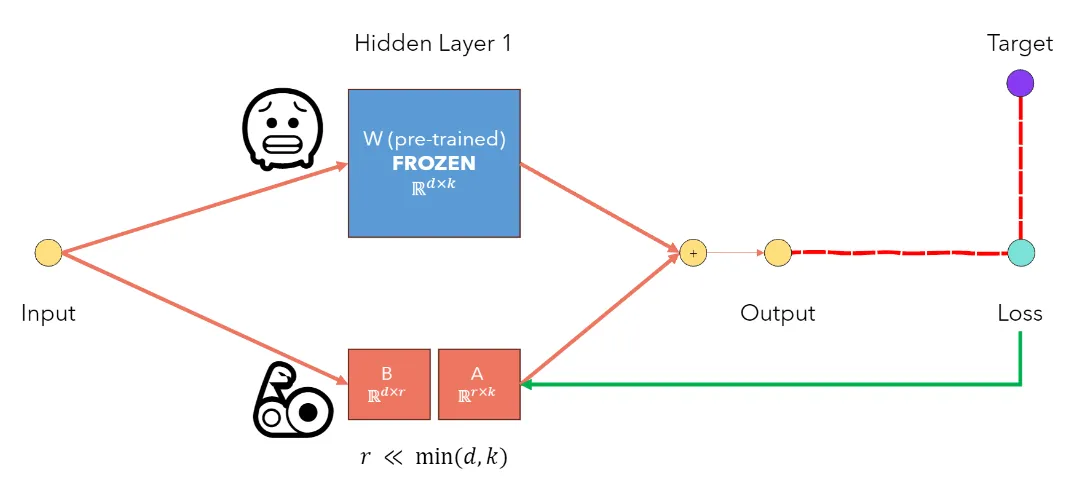
LoRA in PyTorch
Learn how to implement LoRA (Low-Rank Adaptation) in PyTorch, a parameter-efficient fine-tuning method.

Vector Add in Triton
Starting from simple vector addition, learn how to write Triton kernels and explore performance tuning techniques.

Softmax in OpenAI Triton
Learn how to write efficient GPU kernels using OpenAI Triton, implementing the Softmax operation and understanding Triton's programming model.
Introduction to Policy Gradient
Learning the fundamental principles and implementation of policy gradient methods, and understanding how to train reinforcement learning agents by directly optimizing the policy.
Configuring Ubuntu 20.04 on WSL2
Documenting the complete process of configuring WSL2 and Ubuntu 20.04 on Windows 11, including disk migration, network configuration, and deep learning environment setup.
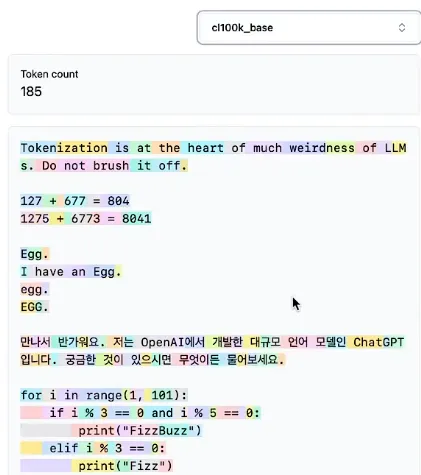
History of LLM Evolution (6): Unveiling the Mystery of Tokenizers
Deeply understand how tokenizers work, learning about the BPE algorithm, the tokenization strategies of the GPT series, and implementation details of SentencePiece.

History of LLM Evolution (5): Building the Path of Self-Attention — The Future of Language Models from Transformer to GPT
Building the Transformer architecture from scratch, deeply understanding core components like self-attention, multi-head attention, residual connections, and layer normalization.
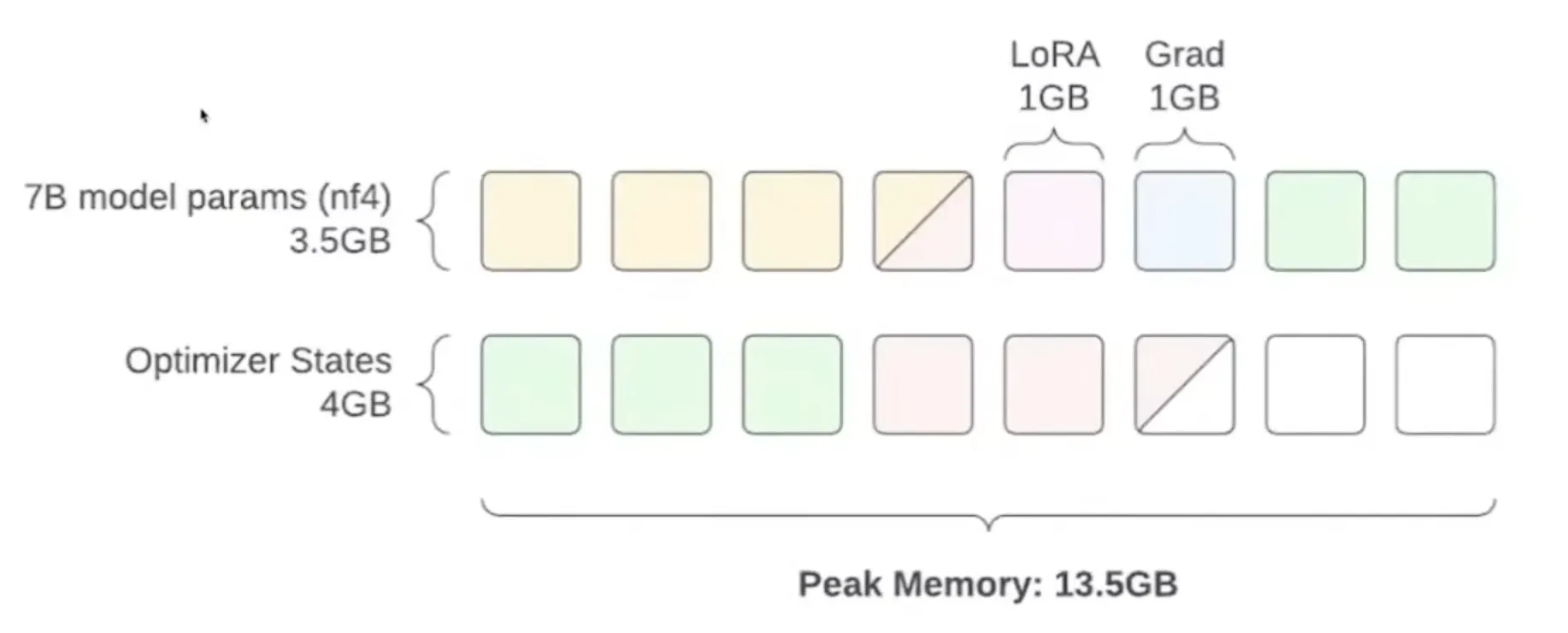
The Way of Fine-Tuning
Learn how to fine-tune large language models under limited VRAM conditions, mastering key techniques like half-precision, quantization, LoRA, and QLoRA.
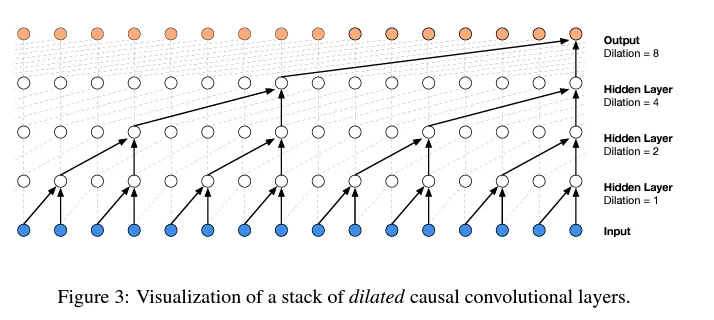
History of LLM Evolution (4): WaveNet — Convolutional Innovation in Sequence Models
Learn the progressive fusion concept of WaveNet and implement a hierarchical tree structure to build deeper language models.
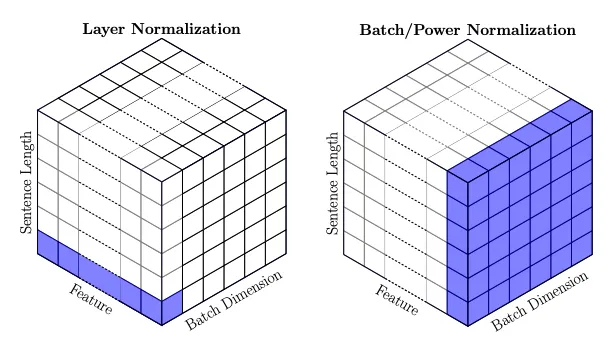
History of LLM Evolution (3): Batch Normalization — Statistical Harmony of Activations and Gradients
Deeply understand the activation and gradient issues in neural network training, and learn how batch normalization solves the training challenges of deep networks.

The State of GPT
A structured overview of Andrej Karpathy's Microsoft Build 2023 talk, deeply understanding GPT's training process, development status, the current LLM ecosystem, and future outlook.
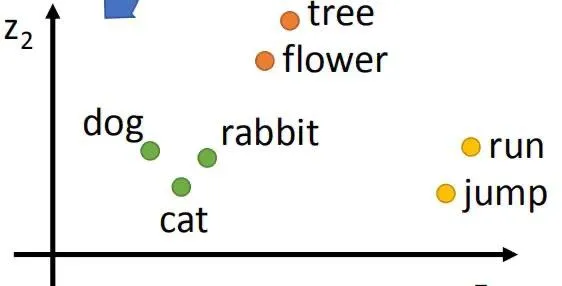
History of LLM Evolution (2): Embeddings — MLPs and Deep Language Connections
Exploring Bengio's classic paper to understand how neural networks learn distributed representations of words and how to build a Neural Probabilistic Language Model (NPLM).

History of LLM Evolution (1): The Simplicity of Bigram
Starting with the simplest Bigram model to explore the foundations of language modeling. Learn how to predict the next character through counting and probability distributions, and how to achieve the same effect using a neural network framework.

Building a Minimal Autograd Framework from Scratch
Learning from Andrej Karpathy's micrograd project, we build an automatic differentiation framework from scratch to deeply understand the core principles of backpropagation and the chain rule.

Turning 21
21st birthday summary, reviewing the growth and gains of the past year.