Quests
クエストActive Quest List / Archiving...

去做机器人!AI本科毕业后的年度总结
新年快乐🎆

从头写一个博客:我的 Passion 还在吗?
圆十年前的一个梦,SAO 主题博客的制作和博文语法记录
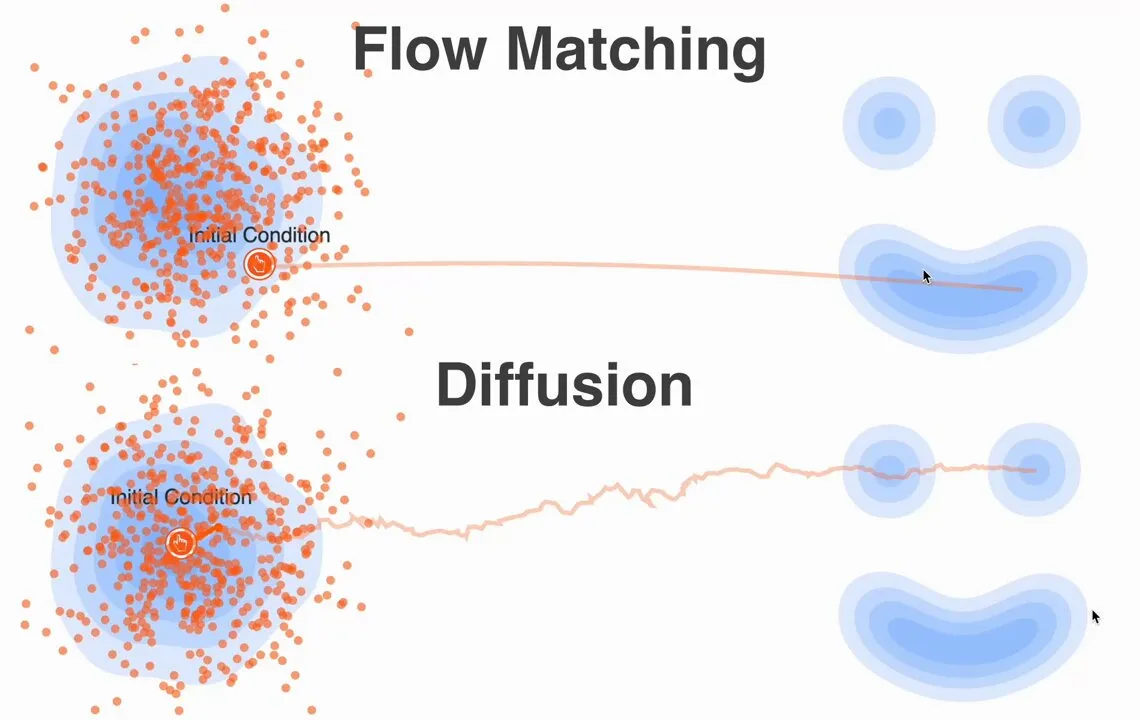
Ditching the SDEs: A Simpler Path with Flow Matching
Flow Matching 给了我们一个全新的、更简单的视角来看待 generative modeling。我们不再考虑概率密度和分数,而是考虑向量场和流。

以 Paligemma 为例的视觉语言模型
感谢 Umar Jamil 在视频教程的中的精彩讲解。视觉语言模型可以分为四类,本文以 Paligemma 为例深入解析 VLM 的架构和实现。
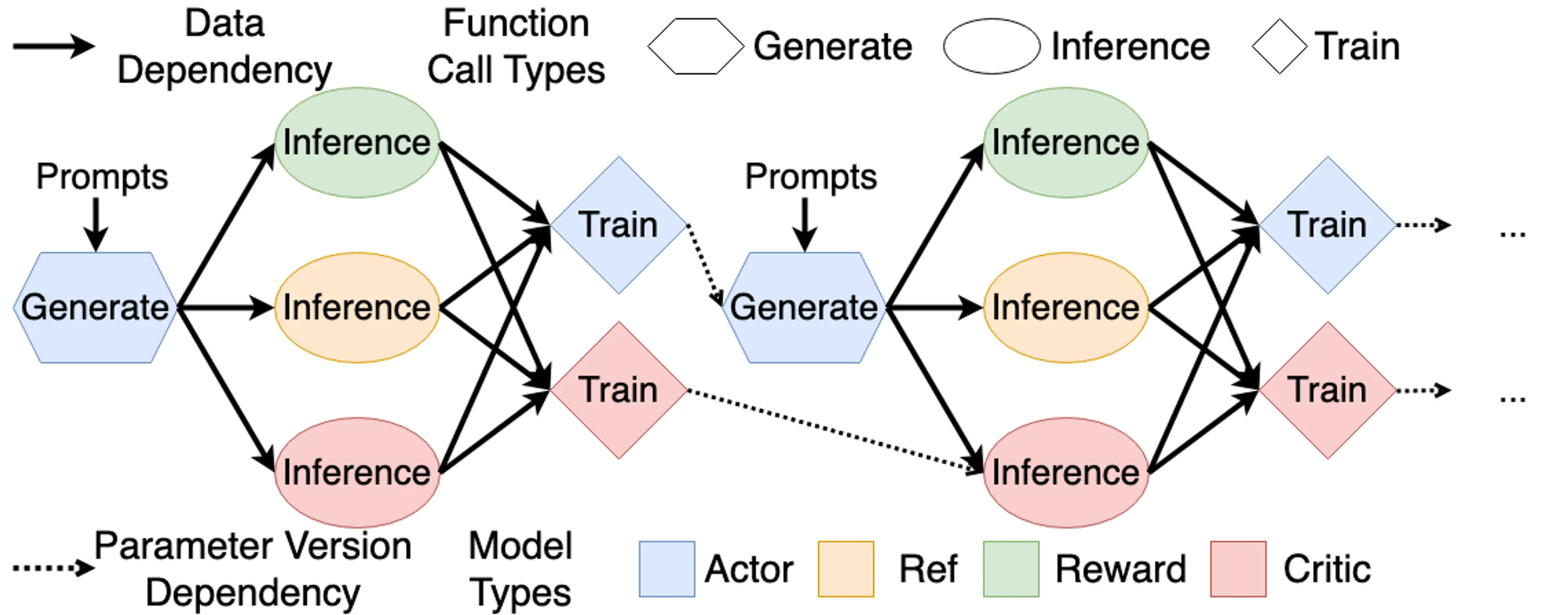
从 RL 来,到 RLHF 去
本文主要基于 Umar Jamil 的课程进行学习和记录。我们的目标是让 LLM 的行为与我们的期望的输出相一致,RLHF 则是最著名的技术之一。

用 Rust 实现简单 LLM 推理
在 B 站偶然刷到清华大学主办的大模型与人工智能系统训练营,果断报名参加。计划利用春节返乡时间通过实践巩固 LLM Inference 的理论知识,恰逢学校 VPN 故障无法科研,正好整理学习笔记。

2024 年度总结
2024 是我接触深度学习的第一年,也是进入大模型领域的第一年,也许未来某天回头看,今年会是做出众多重要选择的一年。

Diffusion 的直觉和数学
深入理解扩散模型的直觉原理和数学推导,从正向过程到逆向过程,掌握 DDPM 的核心思想和实现细节。
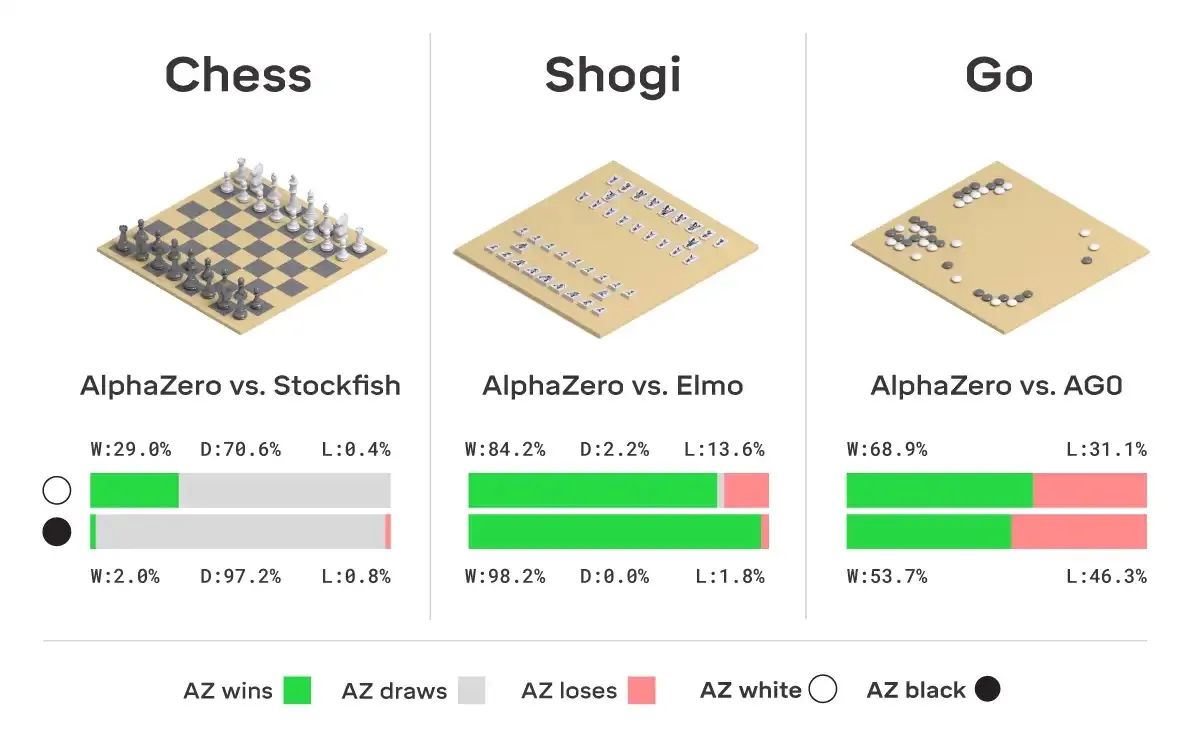
Let's build AlphaZero
从 AlphaGo 的设计原理出发,通过深入理解 MCTS 和 Self-Play 这两个核心机制,逐步揭示如何构建一个能超越人类的 AI 五子棋系统。

"速通" PPO
快速理解 PPO(Proximal Policy Optimization)算法的核心思想和实现细节,掌握现代强化学习的重要方法。

知识蒸馏入门学习
学习知识蒸馏的基本原理,了解如何将大模型(教师)的知识传递给小模型(学生),实现模型压缩和加速。
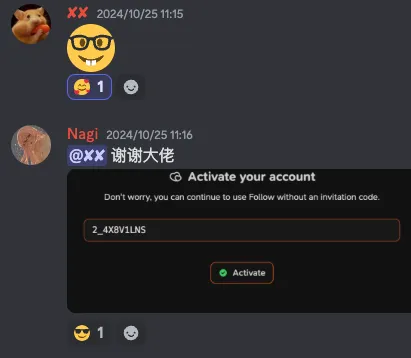
破解 Follow 邀请码的历程
记录破解 Follow 邀请码的完整过程,学习 LSB 隐写术和 StegOnline 工具的使用。
Actor Critic 方法初探
学习 Actor-Critic 方法,结合策略梯度(Actor)和价值函数(Critic)的优势,实现更高效的强化学习。

从 DQN 到 Policy Gradient
探索从基于值的方法(DQN)到基于策略的方法(Policy Gradient)的演进,理解两种方法的区别和联系。
强化学习基础与 Q-Learning
从零开始学习强化学习的基础概念,深入理解 Q-Learning 算法及其在离散动作空间中的应用。
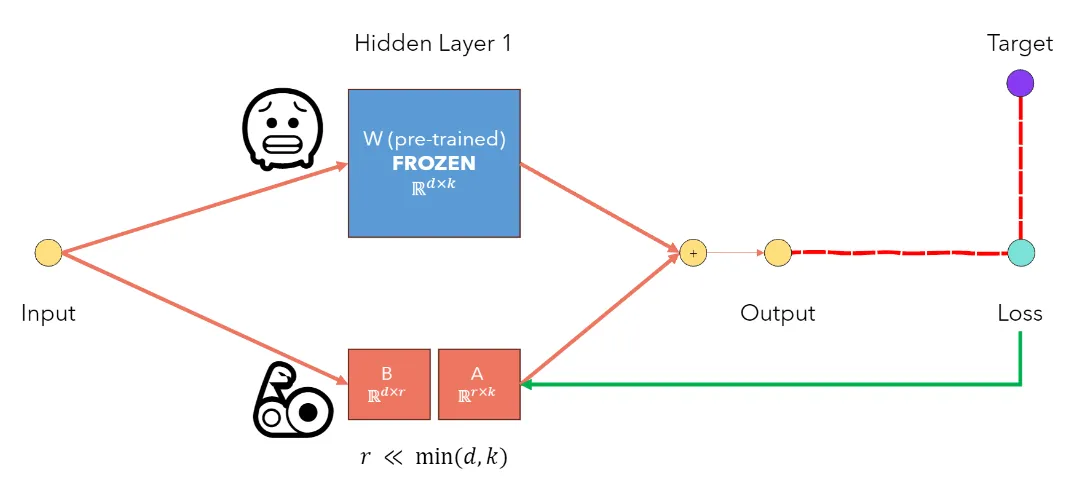
LoRA in PyTorch
学习如何在 PyTorch 中实现 LoRA(Low-Rank Adaptation),一种参数高效的微调方法。

Vector Add in Triton
从最简单的向量加法开始,学习 Triton 内核的编写和性能调优技巧。

Softmax in OpenAI Triton
学习如何使用 OpenAI Triton 编写高效的 GPU 内核,实现 Softmax 操作并理解 Triton 的编程模型。
Policy Gradient 入门学习
学习策略梯度方法的基本原理和实现,了解如何通过直接优化策略来训练强化学习智能体。
WSL2 配置 Ubuntu20.04
记录在 Windows 11 上配置 WSL2 和 Ubuntu 20.04 的完整过程,包括迁移硬盘、配置网络和深度学习环境。
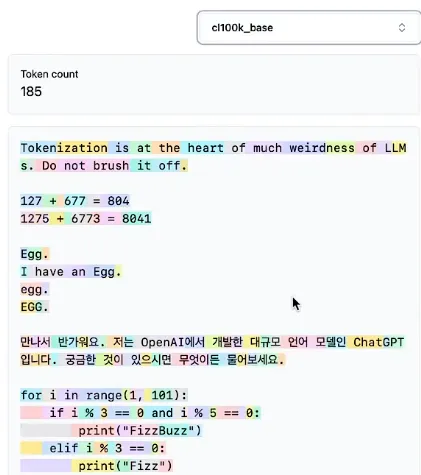
LLM 演进史 (六):揭开 Tokenizer 的神秘面纱
深入理解 Tokenizer 的工作原理,学习 BPE 算法、GPT 系列的分词策略以及 SentencePiece 的实现细节。

LLM 演进史 (五):构筑自注意力之路——从 Transformer 到 GPT 的语言模型未来
从零开始构建 Transformer 架构,深入理解自注意力机制、多头注意力、残差连接和层归一化等核心组件。
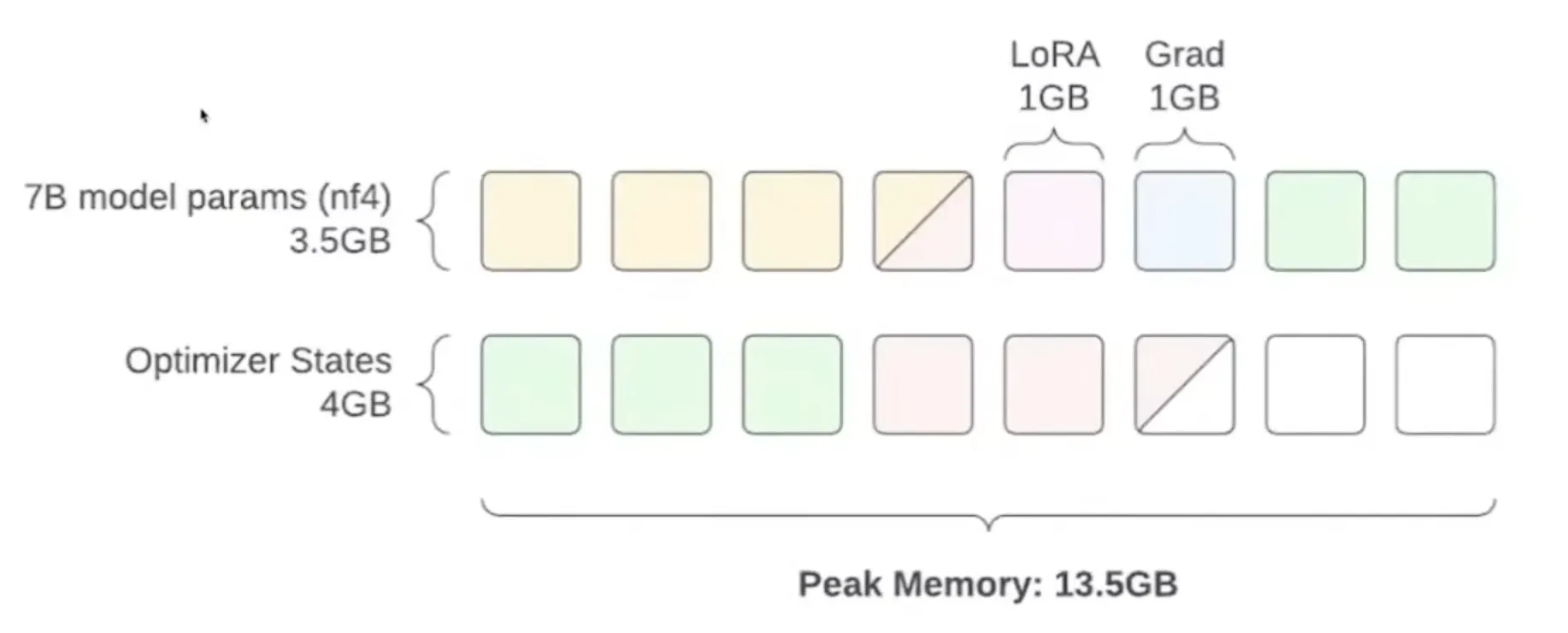
微调之道
学习如何在有限的显存条件下微调大语言模型,掌握半精度、量化、LoRA 和 QLoRA 等关键技术。
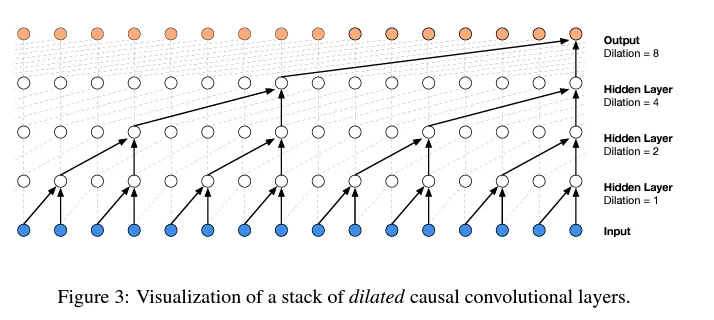
LLM 演进史 (四):WaveNet——序列模型的卷积革新
学习 WaveNet 的渐进式融合思想,实现树状分层结构来构建更深的语言模型。
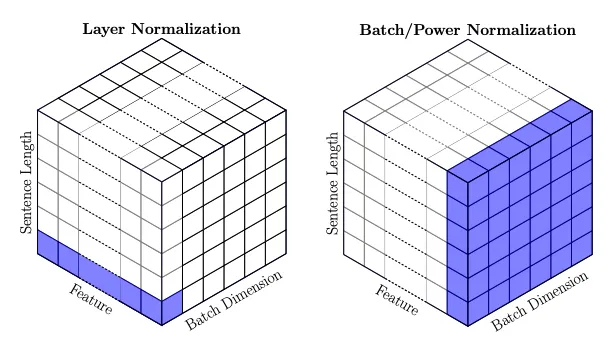
LLM 演进史 (三):批归一化——激活与梯度的统计调和
深入理解神经网络训练中的激活和梯度问题,学习批归一化如何解决深层网络的训练难题。

GPT 的现状
整理 Andrej Karpathy 在 Microsoft Build 2023 的演讲,深入理解 GPT 的训练过程、发展现状、当前 LLM 生态以及未来展望。
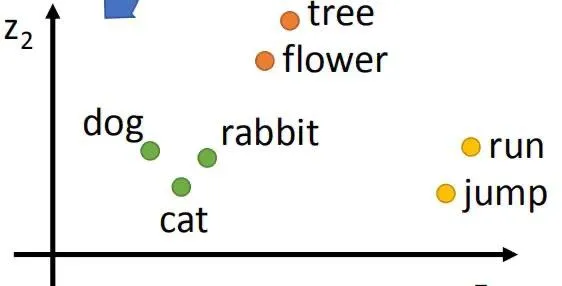
LLM 演进史 (二):词嵌入——多层感知器与语言的深层连接
探索 Bengio 的经典论文,了解如何通过神经网络学习词的分布式表示,以及如何构建一个神经概率语言模型 (NPLM)。

LLM 演进史 (一):Bigram 的简洁之道
从最简单的 Bigram 模型开始,探索语言模型的基础。了解如何通过计数和概率分布来预测下一个字符,以及如何用神经网络框架实现相同的效果。

从 0 实现一个极简的自动微分框架
学习 Andrej Karpathy 的 micrograd 项目,从零开始实现一个自动微分框架,深入理解反向传播和链式法则的核心原理。

Turning 21
21 岁生日总结,回顾这一年来的成长与收获。