探索 Bengio 的经典论文,了解如何通过神经网络学习词的分布式表示,以及如何构建一个神经概率语言模型 (NPLM)。
LLM 演进史 (二):词嵌入——多层感知器与语言的深层连接
本节的源代码仓库地址
《A Neural Probabilistic Language Model》
本文算是训练语言模型的经典之作,Bengio 将神经网络引入语言模型的训练中,并得到了词嵌入这个副产物。词嵌入对后面深度学习在自然语言处理方面有很大的贡献,也是获取词的语义特征的有效方法。
论文的提出源于解决原词向量(one-hot 表示)会造成维数灾难的问题,作者建议通过学习词的分布式表示来解决这个问题。作者基于 n-gram 模型,通过使用语料对神经网络进行训练,最大化上文的 n 个词语对当前词语的预测。该模型同时学到了每个单词的分布式表示和单词序列的概率分布函数。

经典公示
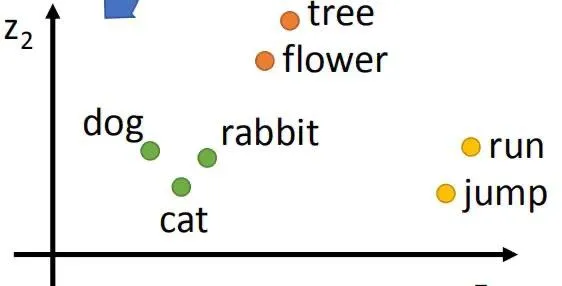
该模型学习到的词汇表示,与传统的 one-hot 表示不同,它可通过词嵌入之间的距离(欧几里得距离、余弦距离等),表示词汇间的相似程度。如在:The cat is walking in the bedroom A dog was running in a room 中,cat 和 dog 有着相似的语义,你可以通过嵌入空间,传递知识,将其推广到新的场景中。

共享 look-up 表 隐藏层的大小是一个超参数 输出层有 17000 个神经元,与隐藏层中的神经元完全相连,即 logits
在神经网络中,术语 “logits” 通常指的是最后一个线性层(即未经激活函数处理的)的输出。在分类任务中,这个线性层的输出被输入到 softmax 函数中以生成概率分布。logits 本质上是模型对每个类别未归一化的预测分数,它们可以被视为反映模型对每个类别的信心水平。
为什么叫 “logits”?
这个术语来自逻辑回归,其中”logit”函数是逻辑函数的反函数。在二分类的逻辑回归中,输出概率 与 logit 之间的关系可以表示为:
表示事件发生与不发生的概率之比,称为odds,即几率。相较于概率,几率的优势有:让输出范围拓展到了整个实数范围,特征与输出间是线性关系,似然函数简洁)
这里, 就是 logit。在神经网络中,尽管没有直接使用 logit 函数,术语 “logits” 仍然被用来描述网络的原始输出,因为这些原始输出在通过 softmax 函数之前与逻辑回归中的 logits 相似。
在多分类问题中,网络的 logits 通常是一个向量,其中每个元素对应一个类别的 logit。例如,如果一个模型在处理手写数字识别(如 MNIST 数据集),则输出 logits 将是一个具有 10 个元素的向量,每个元素对应一个数字类别(0 到 9)的预测分数。
softmax 函数将 logits 转换为概率分布:
这里, 是将第 个 logit 指数化,使其为正数,并且通过除以所有指数化 logits 的总和来归一化,从而得到一个有效的概率分布。
总结:在神经网络的上下文中,logits 是模型对每个类别的原始预测输出,通常在应用 softmax 函数之前。这些原始分数反映了模型的预测信心,并且在训练过程中用于计算损失,特别是交叉熵损失,这是许多分类任务中常用的损失函数。
构建 NPLM
创建数据集
# build the dataset
block_size = 3 # context length: how many characters do we take to predict the next one
X, Y = [], []
for w in words:
print(w)
context = [0] * block_size
for ch in w + '.':
ix = stoi[ch]
X.append(context)
Y.append(ix)
print(''.join(itos[i] for i in context), '--->', itos[ix])
context = context[1:] + [ix] # crop and append
X = torch.tensor(X)
Y = torch.tensor(Y)
现在我们来搭建神经网络,用 X 来预测 Y。
Lookup Table

我们要把可能出现的 27 个字符嵌入到低维空间中(原论文是将 17000 个词嵌入到 30 维空间)。
C = torch.randn((27,2))
F.one_hot(torch.tensor(5), num_classes=27).float() @ C
# (1, 27) @ (27, 2) = (1, 2)**也就是说,降低运算量并不是因为词向量的出现,而是因为把 one-hot 的矩阵运算简化为了查表操作。**相当于只保留了 C 的第五行


Hidden Layer

W1 = torch.randn((6, 100)) # 输入个数:3 x 2 = 6,100 个神经元
b1 = torch.randn(100)
emb @ W1 + b1 # 我们希望得到这样的形式但是由于 emb 的形状是[228146, 3, 2],怎么把 3 和 2 组合起来变成 6 呢?
torch.cat(tensors, dim, ):

因为 block_size 可以改变,我们要避免硬编码形式,就换用 torch.unbind(tensors, dim, ) 获取切片元组:

上面的方式会创建新的内存,有没有更高效的方式呢?
tensor.view():
a = torch.arange(18)
a.storage() # 0 1 2 3 4 ... 17
这样的做法是高效的。因为每个 tensor 都有底层存储形式,也就是存储的数字本身,永远都是一个一维向量。对其调用的view()的时候,我们只是改变了这个序列的解释方式属性,这个过程中没有发生内存的改变、复制、移动或者创建,也就是两者之间的存储是相同的。

所以最后的样子是如下:
emb.view(emb.shape[0], 6) @ W1 + b1
# or
emb.view(-1, 6) @ W1 + b1加入非线性变换:
h = torch.tanh(emb.view(-1, 6) @ W1 + b1)Output Layer
# 27 个可能输出的字符
W2 = torch.randn((100, 27))
b2 = torch.randn(27)
logits = h @ W2 + b2和上一节中一样,得到 counts 和概率:
counts = logits.exp()
prob = counts / counts.sum(1, keepdim=True)Negative log likelihood loss:
loss = -prob[torch.arange(Y.shape[0]), Y].log().mean()
当前损失是 19 多,是我们的训练优化起点。
重新整理一下我们的神经网络:
g = torch.Generator().manual_seed(2147483647)
C = torch.randn((27,2), generator=g)
W1 = torch.randn((6,100), generator=g)
b1 = torch.randn(100, generator=g)
W2 = torch.randn((100,27), generator=g)
b2 = torch.randn(27, generator=g)
parameters = [C, W1, b1, W2, b2]
sum(p.nelement() for p in parameters) # 3481
# forward pass
emb = C[X] # (228146, 3, 2)
h = torch.tanh(emb.view(-1, 6) @ W1 + b1) # (228146, 100)
logits = h @ W2 + b2 # (228146, 27)这里我们可以使用 torch 的交叉熵损失函数来替换之前的代码:
# counts = logits.exp()
# prob = counts / counts.sum(1, keepdim=True)
# loss = -prob[torch.arange(Y.shape[0]), Y].log().mean()
loss = F.cross_entropy(logits, Y)
可以看到结果完全一样
实践中都会使用 PyTorch 的实现方式,因为它让所有操作在一个fused kernel中进行,不会创建额外的存储张量的中间内存,并且表达式更简单,forward、backward pass 的效率更高。除此之外,教学的实现方式中,如果有一个 count 很大,经过 exp 后就会溢出变为 nan。
PyTorch 的实现方式是如何解决这个问题的:
举例:对于 logits = torch.tensor([1,2,3,4]) 和 logits = torch.tensor([1,2,3,4]) - 4,虽然两者的绝对值不同,但它们的相对差距保持不变。Softmax 函数是关于输入的相对差距敏感的,而不是其绝对值。
当你从 logits 中减去一个常数,指数函数的性质使得每个 logit 的指数减小了相同的倍数。但是,由于这个常数是从每个 logit 中都减去的,它会在分子和分母中抵消掉,因此不会影响最终的概率分布。也就是说,对于任何 logits 向量和常数 C:
PyTorch 通过在内部计算 logits 中的最大值,然后减去这个值,防止了在计算 e^logits 时发生数值上的溢出。
Training
for p in parameters:
p.requires_grad_()
for _ in range(10): # 数据量大,先测试一下优化是否成功
# forward pass
emb = C[X] # (228146, 3, 2)
h = torch.tanh(emb.view(-1, 6) @ W1 + b1) # (228146, 100)
logits = h @ W2 + b2 # (228146, 27)
loss = F.cross_entropy(logits, Y)
# backward pass
for p in parameters:
p.grad = None
loss.backward()
# update
for p in parameters:
p.data += -0.1 * p.grad
print(loss.item())
由于是在整个数据集上训练的,损失只能达到一个相对较小的值,可以看到输出的结果和正确结果之间有一定的相似度,如果只用一个 batch 来训练的话,能够达到过拟合的效果,预测结果基本和正确结果一样。从根本上来说,损失也不会非常接近 0,因为
...也是需要预测的,很多字母都有可能,不可能完全过拟合。
mini-batch
由于每次要回溯这 22 万个数据,每次迭代的速度较慢,运算量十分庞大。实践中,人们常用的是在前向和反向传递中在很多小批的数据上更新并衡量表现。我们要做的就是随机选择数据集的一部分,这就是mini-batch,然后在这些小批次数据上进行迭代。
for _ in range(1000):
# mini-batch
ix = torch.randint(0,X.shape[0],(32,))
# forward pass
emb = C[X[ix]] # (32, 3, 2)
h = torch.tanh(emb.view(-1, 6) @ W1 + b1) # (32, 100)
logits = h @ W2 + b2 # (32, 27)
loss = F.cross_entropy(logits, Y[ix])现在迭代速度变得飞快。
这样做每次优化的并不是真正的梯度和正确的方向,是在一个近似的梯度上多走几步,在实践中上是很有效的。

learning rate
lre = torch.linspace(-3, 0, 1000)
lrs = 10**lre # (0.001 - 1)
lri = []
lossi = []
for i in range(1000):
'''
mini-batch, forward and backward pass code
'''
# update
lr = lrs[i]
for p in parameters:
p.data += -lr * p.grad
# tracks stats
lri.append(lre[i])
lossi.append(loss.item())
plt.plot(lri, lossi)
如图,可以看到 lre 在 -1.0 附近损失达到最小附近,此时的学习率就是
现在我们有了对选择学习率的信心。
lr = 0.1
for p in parameters:
p.data += -lr * p.grad 在运行了几次 1 万步的迭代后,损失稳定在 2.4 附近,这时候可以降低学习率(learning rate decay),如降低十倍至 0.01 训练几轮,这样就的到了一个大概训练好的网络。

比之前的 bigram model 损失要低很多,那可以说这个模型比之前的要好吗?
其实这个说法并不对,如果我们把参数量提高,这个模型的损失甚至能达到非常接近 0 的地步,但你对其抽样只能得到训练集中完全一样的例子,在面对没见过的词语上损失可能会很大,所以这并不是一个好模型。
这就引出了这个领域的标准做法:将数据集分开,spliting 为 3 段,即 training split, validation(dev) split, test split,我们耳熟能详的训练集、验证集、测试集。
训练集(Training Split):
- 用途:用来训练模型的参数,即模型中的权重和偏差。
- 过程:在训练过程中,模型尝试学习数据的特征和模式,并通过反向传播和梯度下降等优化算法调整其参数以最小化损失函数。
验证集(Dev/Validation Split):
- 用途:用来训练(调整)模型的超参数,例如学习率、网络层数、层的大小等。
- 过程:在模型的训练过程中,我们不断地在验证集上评估模型的性能,以便调整和选择最佳的超参数。验证集帮助我们在不接触测试集的情况下评估模型的泛化能力,避免模型的过拟合。
测试集(Test Split):
- 用途:用来评估模型的最终性能,即在实际应用中模型可能的表现。
- 过程:在模型开发阶段,测试集是完全不被接触的。只有在模型经过训练,并且在验证集上调整好所有超参数后,才使用测试集来测试。这样可以提供一个未见过数据的公正评估,给出模型在处理新数据时的真实表现。
这种划分方法帮助研究人员和开发人员避免数据泄露(data leakage)和过拟合(overfitting),这两种情况都会导致模型在训练集上表现良好,但在看不见的新数据上表现不佳。通过这种方式,我们可以更加自信地预测模型在实际世界中的表现。
我们到前面构建数据集的位置,将其封装为一个函数,然后进行三部分的划分:
def build_dataset(words):
'''
previous code
'''
return X, Y
import random
random.seed(42)
random.shuffle(words)
n1 = int(0.8 * len(words))
n2 = int(0.9 * len(words))
Xtr, Ytr = build_dataset(words[:n1]) # 80% train
Xdev, Ydev = build_dataset(words[n1:n2]) # 10% validation
Xte, Yte = build_dataset(words[n2:]) # 10% test
三部分的数据量
修改神经网络训练部分:
ix = torch.randint(0,Xtr.shape[0],(32,))
loss = F.cross_entropy(logits, Ytr[ix])
可以看到,训练集和验证集的损失相近,所以我们的模型没有强大到过拟合,这样的状态被称为欠拟合(underfitting),这通常意味着我们的网络参数量太小了。
最简单的方式就是把隐藏层的神经元数量增加:

现在有 1 万多个参数,相较于原来的 3000 多个网络变大了很多

可以看到损失函数优化后面的过程”很厚”,是因为在 mini-batch 上训练会产生一些噪声(noise)
现在的网络效果仍然欠佳,影响性能瓶颈的原因有:
- mini-batch size 太小,噪声太大
- 嵌入方式有问题,将过多的字符放到了二维空间,神经网络并不能很好的利用
可视化当前的嵌入:
plt.figure(figsize=(8, 8))
plt.scatter(C[:,0].data, C[:,1].data, s=200)
for i in range(C.shape[0]):
plt.text(C[i,0].item(), C[i,1].item(), itos[i], ha="center", va="center", color="white")
plt.grid('minor')
可以看到是有训练成果的,
g、q、p还有.都被视作了特殊的向量,而x、h、b等则被视作相近的,可互相替换的向量。
嵌入向量很可能影响了网络的瓶颈。
C = torch.randn((27,10), generator=g)
W1 = torch.randn((30,200), generator=g)
b1 = torch.randn(200, generator=g)
W2 = torch.randn((200,27), generator=g)

损失比之前小了,看来嵌入向量确实有比较大的影响。
进一步的优化策略:
- 嵌入向量维度
- 上下文长度
- 隐藏层神经元数量
- 学习率
- 训练实践
- …
Sampling
最后,采样看一下模型当前效果:
g = torch.Generator().manual_seed(2147483647 + 10)
for _ in range(20):
out = []
context = [0] * block_size # initialize with all ...
while True:
emb = C[torch.tensor([context])] # (1, block_size, D)
h = torch.tanh(emb.view(1, -1) @ W1 + b1)
logits = h @ W2 + b2
probs = F.softmax(logits, dim=1)
ix = torch.multinomial(probs, num_samples=1, generator=g).item()
context = context[1:] + [ix]
out.append(ix)
if ix == 0:
break
print(''.join(itos[i] for i in out))
初具人形,可见还是有提高的。
接下来,我们就会进入现代的模型介绍,如 CNN、GRU 和 Transformers。