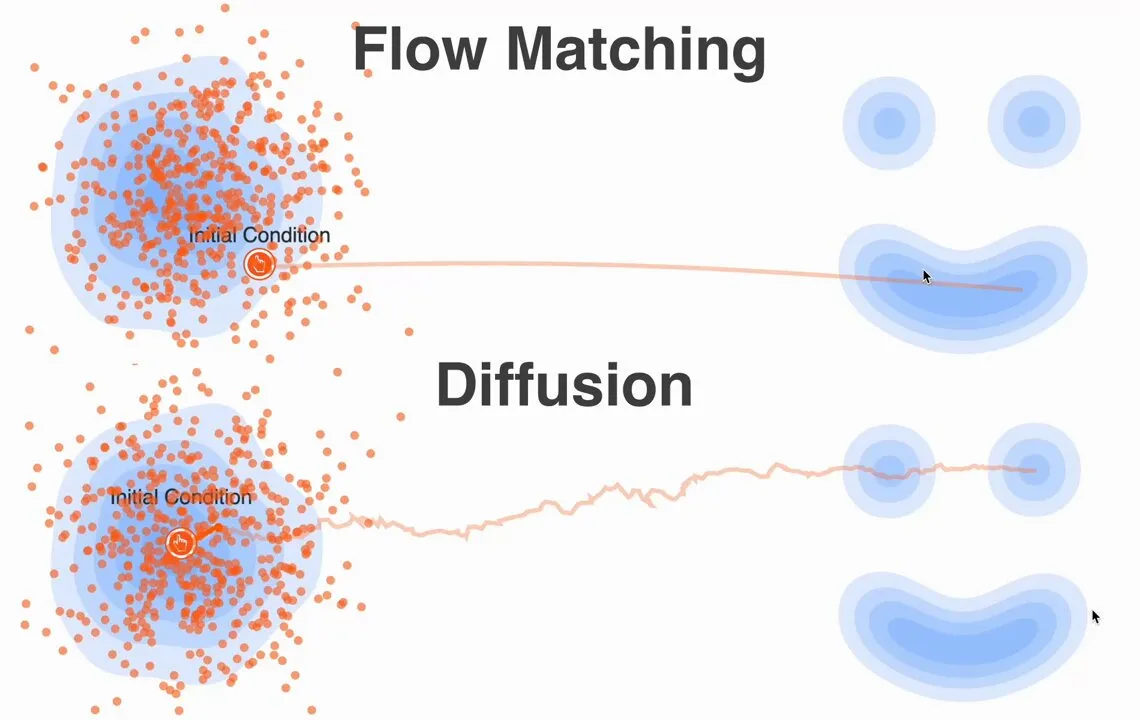
Flow Matching 给了我们一个全新的、更简单的视角来看待 generative modeling。我们不再考虑概率密度和分数,而是考虑向量场和流。
Ditching the SDEs: A Simpler Path with Flow Matching
本文主要以该视频的教学逻辑为主线,结合讲解内容进行整理和阐述,如有错误欢迎在评论区纠正!
Flow Matching:让我们从第一性原理重塑生成模型
好了,我们来聊聊 generative models。目标很简单,right?我们有一个数据集,比如说,一堆猫的图片,它们来自某个疯狂的、高维的概率分布 。我们想训练一个模型,它能吐出新的猫咪图片。目标简单,但实现方法可能会变得……嗯,相当 gnarly。
你可能听说过 Diffusion models。整个想法就是从一张图片开始,通过几百个步骤慢慢地加入噪声,然后训练一个巨大的网络来一步步地逆转这个过程。它背后的数学涉及到 score functions ()、随机微分方程 (stochastic differential equations, SDEs)……it's a whole thing。这套方法确实有效,而且效果出奇地好,但作为一个计算机科学家,我总是会想:我们能用一种更简单、更直接的方式达到同样的目的吗?有没有办法 hack 一下?
让我们退一步,从零开始。第一性原理。
核心问题
我们有两个分布:
- :一个我们可以轻松采样的、超级简单的噪声分布。可以想象成
x0 = torch.randn_like(image)。 - :我们真实数据的、复杂的、未知的分布(比如猫!)。我们可以通过从数据集中加载一张图片来从中采样。
我们想要学习一个 mapping,它能接收一个来自 的样本,然后把它变成一个来自 的样本。
Diffusion 的方式是定义一个复杂的分布路径 ,让 慢慢地演变成 ,然后再学习如何逆转它。但这个中间分布 正是所有数学复杂性的来源。
那么,我们能做的最简单的事情是什么呢?
一个天真的、“高中物理”般的想法
如果我们只是……画一条直线呢?
说真的。让我们挑选一个噪声样本 ,和一个真实的猫咪图片样本 。它们之间最简单的路径是什么?当然是线性插值。
在这里, 是我们的“时间”参数,从 变到 。
- 当 时,我们处于噪声 。
- 当 时,我们处于猫咪图片 。
- 在两者之间的任何时间 ,我们都处于两者的某种模糊混合状态。
好了,很简单。现在,如果我们想象一个粒子在一秒钟内沿着这条直线路径从 移动到 ,它的速度是多少?再次,让我们坚持高中物理知识,只对时间 求导:
等一下。让这个结论在你脑中停留一会儿。

对于这条简单的直线路径,我们的粒子在任何时间点的速度,都只是那个从起点指向终点的恒定向量。这是你能想象到的最简单的 vector field。
这就是那个“Aha!”时刻。如果这就是我们所需要的一切呢?
构建模型
我们有了一个目标!我们想学习一个 vector field。让我们定义一个神经网络 ,它接收任何点 和任何时间 作为输入,然后输出一个向量,也就是它对该点速度的预测。
我们如何训练它?嗯,我们希望网络的输出与我们的简单目标速度 相匹配。最直接的方法就是使用 Mean Squared Error 损失。
所以,我们整个的训练目标就变成了:
让我们来分解一下 training loop。它简直是滑稽般的简单:
x1 = sample_from_dataset() # 抓一张真实的猫咪图片
x0 = torch.randn_like(x1) # 抓一些噪声
t = torch.rand(1) # 随机选一个时间
xt = (1 - t) * x0 + t * x1 # 插值得到我们的训练输入点
predicted_velocity = model(xt, t) # 让模型给出速度预测
target_velocity = x1 - x0 # 这就是我们的 ground truth!
loss = mse_loss(predicted_velocity, target_velocity)
loss.backward()
optimizer.step()Boom. 就是这样。这就是 Conditional Flow Matching 的核心。我们把一个令人费解的概率分布匹配问题,变成了一个简单的回归问题。
为什么这如此强大:“Simulation-Free”
注意我们没有做什么。我们从未需要提及那个复杂的边缘分布 。我们从未需要定义或估计一个 score function。我们完全绕过了整个 SDE/PDE 的理论体系。
我们所需要的只是能够抽取点对 并在它们之间进行插值的能力。这就是为什么它被称为 simulation-free 训练。它难以置信地直接。
生成图片 (Inference)
好了,我们已经训练好我们的网络 ,让它成为了一个从噪声导航到数据的优秀“GPS”。我们如何生成一张新的猫咪图片呢?
我们只需遵循它的指示!
- 从一个随机的噪声点开始:
x = torch.randn(...)。 - 从时间 开始。
- 迭代若干步:
a. 从我们的“GPS”获取方向:
velocity = model(x, t)。 b. 朝那个方向迈出一小步:x = x + velocity * dt。 c. 更新时间:t = t + dt。 - 经过足够多的步骤(例如,当 到达 1 时),
x就会成为我们全新的猫咪图片。
这个过程只是在求解一个常微分方程 (Ordinary Differential Equation, ODE)。它基本上就是欧拉方法,你也可能在高中学过。Pretty cool, right?
总结
所以,回顾一下,Flow Matching 给了我们一个全新的、更简单的视角来看待 generative modeling。我们不再考虑概率密度和分数,而是考虑向量场和流。我们定义了一条从噪声到数据的简单路径(比如一条直线),然后训练一个神经网络来学习产生这条路径的速度场。
事实证明,这个简单的、直观的想法不仅仅是一个 hack;它在理论上是健全的,并且为像 SD3 这样的一些最新的 state-of-the-art 模型提供了动力。它完美地提醒了我们,有时,最深刻的进步来自于为一个复杂问题找到一个更简单的 abstraction。
Simplicity wins.
Flow Matching 的“正规推导”:为啥我们那个简单的“黑科技”是可行的?
好,前面我们用一个超级简单直观的想法推导出了 Flow Matching 的核心。我们取一个噪声样本 ,一个真实数据样本 ,在它们之间画一条直线(),然后说我们的神经网络 只需要学习它的速度就行了… 也就是 。损失函数几乎是自己蹦出来的。搞定。
老实说,对于一个实践者,这已经是你需要知道的 90% 的内容了。
但如果你和我一样,你脑海里可能会有个小声音在嘀咕:“等等…这感觉也太轻松了吧。我们那个技巧是建立在一对独立的样本点 上的。凭什么通过学习这些独立的直线,就能让我们的网络理解整个高维概率分布 的流动呢?我们那个简单的技巧,到底是一个站得住脚的捷径,还是一个碰巧奏效的、有点可爱的‘黑科技’?”
这就是论文里那部分形式化推导的用武之地了。它的目的,就是为了证明我们那个简单的、conditional(基于条件的)目标函数,确实能够魔法般地优化那个更宏大、更吓人的 marginal(基于边缘分布的)目标。
让我们暂时戴上数学家的帽子,看看他们是如何填平这条鸿沟的。
那个“官方的”、纯理论的问题:边缘流 (Marginal Flows)
“真正的”、理论上纯粹的问题是这样的:我们有一系列概率分布 ,它从噪声 逐渐“变形”为数据 。这个连续的变形过程由一个 vector field(向量场) 所支配。这个 就是在时间 、位置 处点的速度向量。
所以,“官方”目标是训练我们的网络 来匹配这个真实的、边缘向量场 。对应的损失函数应该是:
看到这个公式,我们应该立刻意识到:这玩意儿简直是一场灾难。它完全是 intractable(没法处理的)。我们没法从 中采样,也压根不知道目标 是什么。所以,暂时来看,这个损失函数毫无用处。
沟通的桥梁:连接“边缘”与“条件”
于是,研究者们使出了一招经典的数学招式。他们说:“好吧,边缘场 是个猛兽。但我们能不能把它表示成一大堆简单的、conditional(条件的)向量场的平均值呢?”
一个条件向量场,我们称之为 ,指的是一个点 的速度,前提是我们已经知道它的最终目的地是数据点 。
论文证明了(这也是其核心的理论洞察),那个吓人的边缘场 ,其实就是所有简单的条件场的期望值,并由“一条从 出发的路径会经过 的概率”进行加权:
这就建立了一座桥梁。我们把一个未知的东西 () 和一堆我们或许可以定义出来的、更简单的东西 () 联系了起来。
我们的出发点是那个“官方的”、理论上正确但无法直接优化的 边缘流损失函数 (Marginal Flow Matching Loss)。对于任意一个时间步 ,其形式如下:
这里的 是在时间 的边缘概率密度,而 是我们想要学习的真实边缘向量场。这两个我们都无法得到,所以这个形式是无法计算的。我们的目标是通过数学变换,把它变成一个可以计算的形式。
第一步:展开平方误差项
我们使用代数恒等式 来展开损失函数:
注意到,在优化过程中,我们只关心和我们模型的参数 相关的项。上式中的 是真实向量场的模长平方,它不依赖于 ,因此在求梯度时可以被看作一个常数项。为了最小化 ,我们只需要最小化剩余的部分即可:
第二步:将期望重写为积分
根据期望的定义 ,我们将上式重写为积分形式。我们重点关注包含未知项 的第二部分,即交叉项:
第三步:代入连接“边缘”与“条件”的桥梁公式
这里的关键在于一个核心等式,它将难以处理的边缘项 和可以定义的条件项联系起来。这个等式是:
我们将这个等式代入到我们重点关注的交叉项中:
第四步:交换积分次序 (Fubini-Tonelli 定理)
现在我们得到了一个双重积分。这个表达式看起来更复杂了,但我们可以利用 Fubini-Tonelli 定理交换 和 的积分次序。这个操作是合法的,它能让我们重新组合被积函数:
第五步:将积分重新变回期望形式并完成配方
仔细观察第四步中括号内的部分:。这正是关于条件概率分布 的期望!所以,我们可以将内部的积分写成 。
现在再看整个表达式,它又变成了关于 的积分,所以我们又可以把它写成关于 的期望:
这个嵌套的期望可以合并成一个关于联合分布的期望:
现在,我们将这个变换后的交叉项代回到 中。同时,通过类似的变换,第一项也可以被重写:。 于是我们得到:
为了得到一个完美的平方形式,我们对上式加上再减去同一个项 :
中括号里的部分正好构成了一个完全平方式。而减去的最后一项不依赖于模型参数 ,因此在优化时可以忽略。
最终结果
我们成功证明了,最小化最初那个无法处理的边缘损失函数,等价于最小化下面这个可以处理的条件流匹配目标函数 (Conditional Flow Matching Objective):
至此,我们便在数学上严格证明了,只需要定义一个简单的条件路径(如线性插值)和其对应的向量场,并优化这个简单的回归损失,就能达到优化真实边缘流的宏大目标。
这是巨大的一步!我们成功消除了对边缘密度 的依赖。我们的损失函数现在只依赖于条件路径的密度 和条件向量场 。
回到我们最初的简单想法
那么,我们现在到哪一步了?这个形式化证明告诉我们,只要我们能定义一个条件路径 和它对应的向量场 ,我们就能用上面的 损失来训练模型。
现在,我们终于可以把最初那个“高中物理”级别的简单想法给请回来了。我们可以自由地定义这个条件路径。那么,我们就选一个最简单、最不做作的定义:
- 定义条件路径 :就让路径是确定性的,一条直线。所以,概率分布在 这条线上是 1,在其他任何地方都是 0。(而 Diffusion 中从 出发的路径是随机的)
- 定义条件向量场 :正如我们之前计算的,这条路径的速度就是 。
[!NOTE] 在数学中,这种“全部集中于一点,别处皆为零”的特殊分布,被称为狄拉克 函数 (Dirac delta function)。所以,当我们选择一条直线路径时,我们其实是选择了狄拉克函数作为我们的条件概率分布 。
现在,把这两个简单的定义代入到我们刚刚推导出的、那个看起来很高级的 目标函数中。期望 就变成了“在我们的直线上取点 ”,目标 就变成了我们简单的 。
于是,见证奇迹的时刻到了,我们最终得到了:
我们回到了那个完全相同、无比简洁的损失函数,也就是我们从那个最天真的第一性原理推导中“猜”出来的那个!这就是整个形式化证明的意义所在!
总结
好吧,相当酷。我们刚刚经历了一大堆复杂的数学推导——积分、富比尼定理,全套流程——结果只是为了证明我们那个简单直观的“取巧”方法,从一开始就是正确的。我们已经确认:在一条直线路径上学习那个简单的向量目标 ,确实是训练生成模型的一种有效方式。
从理论到 torch :编码流程匹配
好了,我们已经了解了直观的想法,甚至还看过了详细的正式证明。归根结底,这都是一个简单的回归问题。但空谈无益,让我们来看代码。
令人惊叹的是,PyTorch 的实现几乎是我们最终简单公式的 1:1 翻译。没有隐藏的复杂性,没有令人害怕的数学库。只是纯粹的 torch 。
让我们拆解一下脚本中最重要的部分:训练循环和采样(推理)过程。
源代码见视频配套的实现:https://github.com/dome272/Flow-Matching/blob/main/flow-matching.ipynb
设置:数据与模型
首先,脚本设置了一个二维棋盘格图案。这是我们的小型“猫咪图片数据集”。这些点是我们的真实数据,。
然后,它定义了一个简单的 MLP(多层感知机)。这就是我们的神经网络,我们的“GPS”,我们的向量场预测器 。它是一个标准的网络,接受一批坐标 x 和一批时间值 t,并为每个点输出一个预测的速度向量。这里没有什么花哨的,魔法不在于架构,而在于我们让它做什么。
训练循环:魔法就在这里发生
这就是实现的核心部分。让我们回顾一下博客中那最终、优美的损失函数:
现在,让我们逐行查看训练循环的代码。这正是这个公式在起作用。
data = torch.Tensor(sampled_points)
training_steps = 100_000
batch_size = 64
pbar = tqdm.tqdm(range(training_steps))
losses = []
for i in pbar:
# 1. Sample real data x1 and noise x0
x1 = data[torch.randint(data.size(0), (batch_size,))]
x0 = torch.randn_like(x1)
# 2. Define the target vector
target = x1 - x0
# 3. Sample random time t and create the interpolated input xt
t = torch.rand(x1.size(0))
xt = (1 - t[:, None]) * x0 + t[:, None] * x1
# 4. Get the model's prediction
pred = model(xt, t) # also add t here
# 5. Calculate the loss and other standard boilerplate
loss = ((target - pred)**2).mean()
loss.backward()
optim.step()
optim.zero_grad()
pbar.set_postfix(loss=loss.item())
losses.append(loss.item())让我们将其直接映射到我们的公式上:
x1 = ...andx0 = ...:从我们的数据分布 和噪声分布 中采样,提供了期望 所需的 和 。target = x1 - x0:就在这里。问题的核心。这一行计算我们简单直线路径的真实向量场。它是我们损失函数的目标部分,。xt = (1 - t[:, None]) * x0 + t[:, None] * x1:这是另一个关键部分。这是创建路径上点 的线性插值。它是模型的输入,。pred = model(xt, t):这是前向传播,获取我们网络的预测,。loss = ((target - pred)**2).mean():是最后一步。它计算 target 与 pred 之间的均方误差。这是我们公式的 部分。
就这些!这五行最重要的代码是我们推导出的优雅公式的直接逐行实现。
采样:Following the Flow 🗺️
所以我们已经训练好了我们的模型。它现在是一个具有高度技能的“GPS”,能够知道速度场。我们如何生成新的棋盘格图案呢?我们从一片空旷的地方(噪声)开始,按照指示一路前行。
其基本数学原理是我们希望求解常微分方程(ODE): 解决这个问题的最简单方法是欧拉法,它就是通过逐步取小的离散步来实现。
[!TIP] 由于 是一个复杂的神经网络,我们无法用笔和纸解决这个问题。我们必须进行模拟。最简单的方式是用一系列小的离散直线步骤来逼近平滑、连续的流动。
根据导数的基本定义,我们知道在一个很小的时间步长 内,位置的变化 大约等于速度乘以时间步长:。
因此,为了在时间 获得我们新的位置,我们只需在当前位置上添加这个微小的变化。这为我们提供了更新规则:
这段“沿着速度方向稍微移动一点”的方法有一个著名的名字:它被称为欧拉方法(或欧拉更新)。这是数值求解常微分方程最简单、最基本的方法。正如你所看到的,你几乎可以从第一原理自己发明出来。
# The sampling loop from the script
xt = torch.randn(1000, 2) # Start with pure noise at t=0
steps = 1000
for i, t in enumerate(torch.linspace(0, 1, steps), start=1):
pred = model(xt, t.expand(xt.size(0))) # Get velocity prediction
# This is the Euler method step!
# dt = 1 / steps
xt = xt + (1 / steps) * predxt = torch.randn(...):我们从一团随机的点云开始,即我们的初始。for t in torch.linspace(0, 1, steps):我们在一系列离散的steps中模拟从 到 的流动随时间的变化。pred = model(xt, ...):在每一步,我们向模型询问当前速度,。xt = xt + (1 / steps) * pred:这是欧拉更新。我们将当前点 xt 朝模型 pred 预测的方向迈出微小的一步。步长 dt 为 1 / steps。
通过重复这个简单的更新,随机点云逐渐被学习到的向量场“推动”着,直到它们流入棋盘格数据分布的形状。
理论的简洁性直接转化为简洁、清晰且高效的代码,令人感到美妙。
DiffusionFlow
但等等……先别急着庆祝,让我们暂停一下。来个“思考气泡”时刻。
[!WARNING] 我们证明了这套数学在假设 (随机噪声向量)和 (随机猫图)之间走直线路径的前提下是成立的。可是……直线真的就是最好、最高效的路径吗?
从高斯噪声云的混沌状态,到猫图像所处的那个精细复杂的流形,其“真实”的变换过程很可能是一段狂野、曲折、高维的旅程。而我们强行假设走直线……是不是有点太粗暴了?我们要求单个神经网络 学习一个向量场,让它神奇地适用于所有这些被强制设定的、不自然的线性插值。这或许正是为什么我们仍然需要相当多的采样步数才能生成高质量图像的原因——学到的向量场不得不持续纠正我们这个过于简化的路径假设。
于是,一个优秀的“黑客”接下来自然会问:“我们能不能让要解决的问题变得更简单?”
试想一下……如果我们不再强行连接两个完全随机的点 和 ,而是能找到一组“更好”的起点和终点呢?比如一对点 ,它们本身就以某种方式“天然”关联,两点之间的路径已经非常接近直线,简单得多?
这样的点对从哪儿来?很简单——我们可以用另一个生成模型(比如随便一个现成的 DDPM)来帮我们生成!我们给它一个噪声向量 ,它经过几百步的迭代,输出一张不错的图像 。这样,我们就得到了一个 点对,它代表了一个强大模型实际走过的“真实”路径。
现在,我们就有了一个“教师 - 学生”(teacher-student)的训练框架:旧的、慢速的模型为我们提供这些“预先拉直”的路径,而我们则用它们来训练新的、简单的流匹配(Flow Matching)模型。这样一来,新模型的学习任务就变得简单多了。
这种用一个模型为另一个模型构造更简单学习问题的思路非常强大。本质上,你是在把一条复杂、弯曲的路径“蒸馏”成一条更简单、更直的路径。事实上,DeepMind 等团队也想到了完全相同的点子——这正是他们提出的 Rectified Flow(校正流)或 DiffusionFlow 的核心思想:通过迭代不断拉直路径,直到它足够直,几乎一步就能从起点跳到终点。
这是一个建立在我们最初那个简单“取巧”之上的、极具美感的元层级(meta-level)思想。值得细细品味。