
感谢 Umar Jamil 在视频教程的中的精彩讲解。视觉语言模型可以分为四类,本文以 Paligemma 为例深入解析 VLM 的架构和实现。
以 Paligemma 为例的视觉语言模型
感谢 Umar Jamil 在视频教程的中的精彩讲解
视觉语言模型可以分为四类:
- 将图像转为可以和文本 token 共同训练的嵌入特征,如 VisualBERT、SimVLM、CM3 and etc.
- 学习良好的图像嵌入,作为冻结的预训练预言模型的前缀,如 ClipCap
- 通过专门涉及的 cross-attention 将视觉信息融合到语言模型的层中,如 VisualGPT 和 Flamingo 见下图
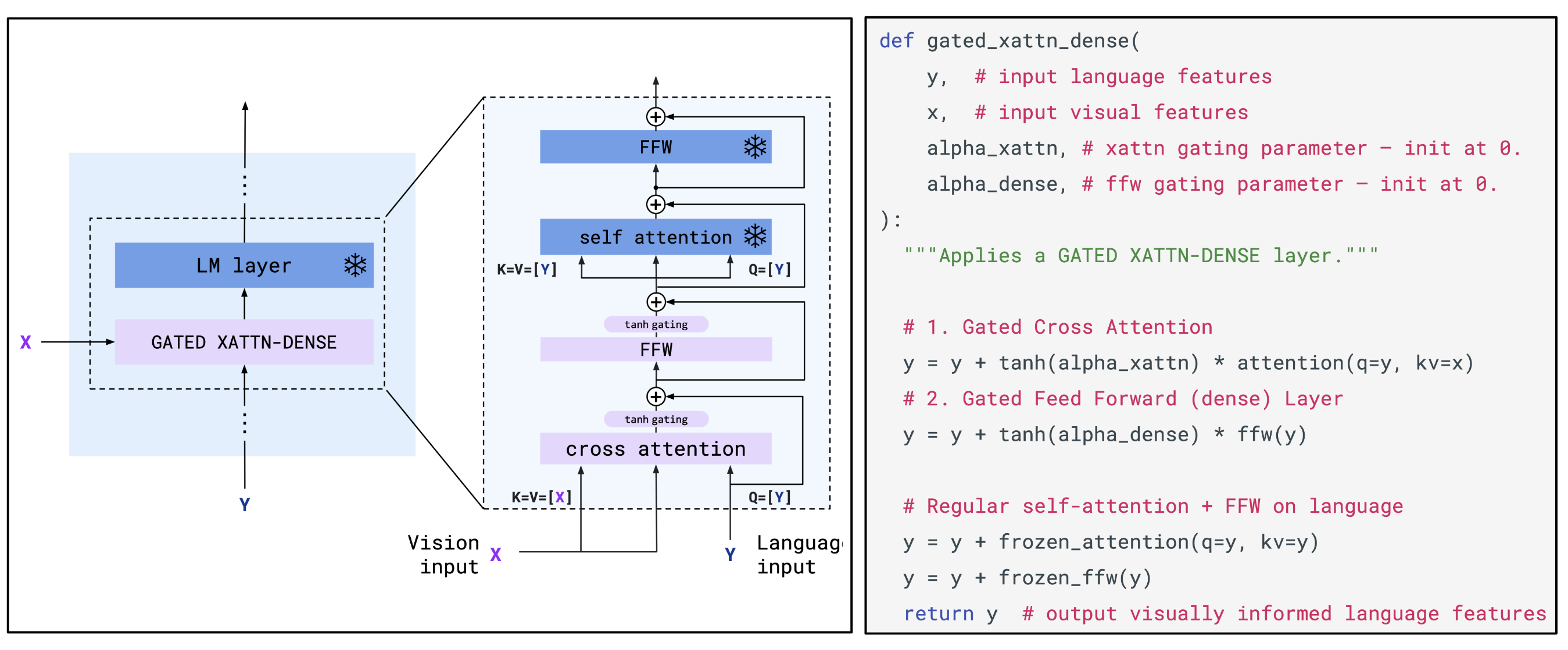
- 在没有任何训练的情况下结合视觉和语言模型,如 MAGiC(引导解码)

一个 VLM 是由 Vision Encoder,Linear Projection Layer 和 LLM Decoder 组成,重点在于如何将 Image token embedding 与文本 token embedding 结合起来,根据输入条件输出结果。

Vision Encoder
ViT
Vision Transformer (ViT) 通过将计算机视觉与 Transformer 架构相结合,采用纯 Encoder 结构来处理图像分类任务。其核心思想是将图像分割成固定大小的 patch,并将这些 patch 转化为 vision embedding 作为 Transformer 的输入序列。
每个图像 patch 都会加入可学习的位置编码(positional embedding)以保留其空间位置信息。由于 ViT 采用双向注意力机制而非自回归模式(无需 attention mask),每个 patch embedding 不仅能够编码其自身信息,还能通过自注意力机制捕获其他 patch 的上下文信息,从而形成上下文感知的(contextualized)表示。这种设计使得模型能够有效地理解图像的全局语义信息和局部特征之间的关系。

特殊的
0*token 为类别标 记([class] token),用于分类任务。
用于将图像输入转换为一系列嵌入表示,每个图像块对应一个嵌入向量表示,与文本 token 嵌入连接后输入 LLM。这里涉及到的技术是对比学习(Contrastive Learning)。
CLIP
简单来说就是用一个包含图像及其对应文本描述的数据集训练模型,给定一批图像文本对,对比学习(如 CLIP)的目标是找到批次中图像之间的正确配对,也就是某个文本与哪个图像的概率更高。所以一组数据里有 n 组正确的文本——图像对, 组错误的配对。
损失函数的效果就是让图像——文本匹配时有高点积高,其他所有组合时低点积。因此可以用交叉熵损失实现,因为交叉熵就是将输入向量通过 softmax 转换为概率分布,然后与标签比较。

它的核心思想是学习一个共享的嵌入空间(embedding space),在这个空间里,匹配的图像和文本对的表示(embeddings)会很接近,而不匹配的则会很远。
CLIP 的训练核心如下代码所示:
# image_encoder: 可以是 ResNet 或 Vision Transformer 等模型
# text_encoder: 可以是 CBOW 或 Text Transformer 等模型
# I[n, h, w, c]: 输入的图像 (minibatch),包含 n 张图像,每张维度为 h*w*c
# T[n, l]: 输入的文本小批量,包含 n 段文本,每段长度为 l (通常是 token 数量)
# W_i[d_i, d_e]: 学习到的图像投影矩阵,将 d_i 维图像特征映射到 d_e 维嵌入空间
# W_t[d_t, d_e]: 学习到的文本投影矩阵,将 d_t 维文本特征映射到 d_e 维嵌入空间
# t: 学习到的温度参数 (一个标量)
I_f = image_encoder(I) # 输出形状:[n, d_i]
T_f = text_encoder(T) # 输出形状:[n, d_t]
# --- 计算联合多模态嵌入 ---
# 将图像特征通过投影矩阵 W_i 映射到 d_e 维空间
image_embedding_projected = np.dot(I_f, W_i)
# 将文本特征通过投影矩阵 W_t 映射到 d_e 维空间
text_embedding_projected = np.dot(T_f, W_t)
# 对投影后的图像和文本嵌入进行 L2 归一化 (使其模长为 1),使点积等于余弦相似度
I_e = l2_normalize(image_embedding_projected, axis=1) # 输出形状: [n, d_e]
T_e = l2_normalize(text_embedding_projected, axis=1) # 输出形状: [n, d_e]
# --- 计算缩放后的成对余弦相似度 ---
# 计算 n 个图像嵌入和 n 个文本嵌入两两之间的点积。
# 由于 I_e 和 T_e 已经 L2 归一化,点积等价于余弦相似度。
# T_e.T 是 T_e 的转置,形状为 [d_e, n]。
# np.dot(I_e, T_e.T) 得到一个 [n, n] 的矩阵,(i, j) 位置的值是第 i 张图和第 j 段文本的余弦相似度。
# 乘以 np.exp(t) 对相似度进行缩放,t 是可学习的温度参数。
logits = np.dot(I_e, T_e.T) * np.exp(t) # 输出形状:[n, n]
# --- 计算对称损失函数 ---
# 创建目标标签,对于一个包含 n 个配对样本的批次,正确的配对在 logits 矩阵的对角线上。正好存储了每一行(每一张图片)对应的正确文本的索引。
# labels = [0, 1, 2, ..., n-1]
labels = np.arange(n)
# 计算图像到文本的对比损失:
# 对 logits 矩阵(相似度矩阵)的每一行 (代表一张图像),计算其与所有文本相似度得分的交叉熵损失。
# 目标是预测正确的文本索引 (即 labels)。axis=0 指示按行计算损失(不同框架实现可能略有差异,但概念如此)。
loss_i = cross_entropy_loss(logits, labels, axis=0)
# 计算文本到图像的对比损失:
# 对 logits 矩阵的每一列 (代表一段文本),计算其与所有图像相似度得分的交叉熵损失。
# 目标是预测正确的图像索引 (即 labels)。axis=1 指示按列计算损失(概念上是这样)。
loss_t = cross_entropy_loss(logits, labels, axis=1)
# 最终的对称损失是两个方向损失的平均值。
loss = (loss_i + loss_t) / 2SigLip
由于 Softmax 涉及指数运算存在数值稳定性问题,可以通过 safe softmax,即对指数减去行中的最大值解决:
softmax(x_i) = exp(x_i) / sum(exp(x_j))
safe_softmax(x_i) = exp(x_i - max(x)) / sum(exp(x_j - max(x)))而 CLIP 中,损失函数包括 text to image 和 image to text 两项,因此需要两次独立的 Softmax 计算,即跨图像(列)和跨文本(行),同时为了数值稳定性还要遍历两次最大值(需要两次 all-gather)。也就是说该 Softmax Loss 或者图中所示的图像——文本矩阵是不对称的,不便于并行化,计算成本十分高昂:
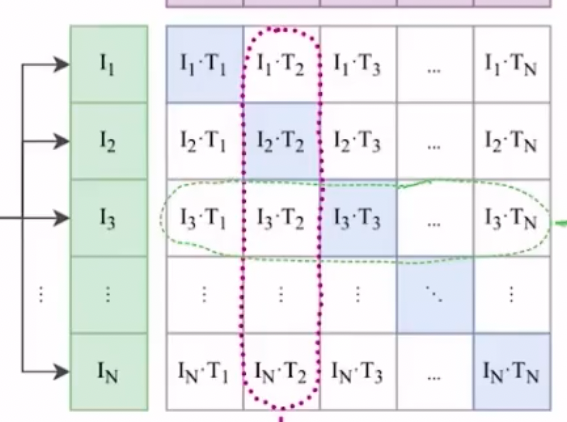
[!note] 可以把 CLIP 看作是在做多分类(softmax 本来的作用),而后面的优化(如 SigLip)就是将其转为多个二分类任务以去掉 softmax。
因此 SigLip 中提议用 Sigmoid Loss 代替。在这种思路下,每个图像——文本对可以独立计算损失,不需要全局归一化因子。现在每一个图像——文本的点积都变成了一个独立的二分类任务。
该函数输出(0, 1)之间的值,常用于二分类任务。好像是最开始的 ML 课讲过这个函数,现在又遇到感觉略微陌生…

通过该优化可以将 batch size 扩展到上百万,并且由于计算是设备独立的可以做并行处理。
[!note] 与一些常见做法不同的是,该工作在多模态预训练期间并没有冻结图像编码器 。研究认为,像字幕生成这样的任务能提供有价值的空间和关系信号,而像 CLIP 或 SigLIP 这样的对比模型可能会忽略这些信号。为了避免与最初未对齐的语言模型产生问题,研究人员对图像编码器的学习率采用了缓慢的线性预热。
Code Walk Through
由于 Transformer、Attention 基础的相关资料已经很完备,这里不再对上述内容做详细阐述,而聚焦于多模态的部分。
由于适配的模型 size 是可配置的,下面先实现基本的 Config Class:
class SiglipVisionConfig:
def __init__(
self,
hidden_size=768, # 嵌入向量大小
intermediate_size=3072, # FFN 中线性层尺寸
num_hidden_layers=12, # ViT 层数
num_attention_heads=12, # MHA 的注意力头数
num_channels=3, # 图片的通道数,即 RGB
image_size=224, # 接收的图像特征尺寸
patch_size=16, # 图片被分割的块数
layer_norm_eps=1e-6,
attention_dropout=0.0,
num_image_tokens: int = None, # 图像分割为 patch 后的 token 总数
# (image_size / patch_size)^2 = (224 // 16) ** 2 = 196
**kwargs
):
super().__init__()
self.hidden_size = hidden_size
...^866e44
对于原始图片,模型会通过卷积层提取 patches,然后将 patches 展平并添加位置编码。
回顾一下卷积操作:
注意实际上会在 RGB 三个通道上进行卷积提取特征

这一步是通过 SiglipVisionEmbeddings 完成的,其中:
nn.Conv2d的输入、输出通道数对应图片的 RGB 通道数和我们想要的隐藏层尺寸;stride属性表示卷积核滑动的步幅,这和我们之前提到的 patch 想切分的方式是一样的;- 至于
padding="valid"表示输入图像边缘不会被填充 0,所以输出特征图尺寸会比输入小; - 由于位置编码要给每个 patch 加上,因此
num_positions和计算得到的num_patches一样。而位置编码position_embedding是和 patch 大小相同的可学习向量; register_buffer用于在模型中注册不需要训练的张量,创建一个从 0 到self.num_positions - 1的序列。expand返回张量视图,转为shape = [1, num_positions]的二维张量[[0, 1, 2, ..., num_positions-1]](与 batch 维度兼容)。
class SiglipVisionEmbeddings(nn.Module):
def __init__(self, config: SiglipVisionConfig):
super().__init__()
self.config = config
self.embed_dim = config.hidden_size
self.image_size = config.image_size
self.patch_size = config.patch_size
self.patch_embedding = nn.Conv2d(
in_channels=config.num_channels,
out_channels=self.embed_dim,
kernel_size=self.patch_size,
stride=self.patch_size,
padding="valid", # This indicates no padding is added
)
self.num_patches = (self.image_size // self.patch_size) ** 2 # 对应前面
self.num_positions = self.num_patches
self.position_embedding = nn.Embedding(self.num_positions, self.embed_dim)
self.register_buffer(
"position_ids",
torch.arange(self.num_positions).expand((1, -1)),
persistent=False, # 该 buffer 是否作为模型的永久部分保存
)forward 中:
- 对于一批 resize 为 224x224 的输入图像,通过卷积将图像分割为不重叠的 patch,并映射到
embed_dim维的特征空间; - 通过
flatten(2)将从索引 2 开始的所有维度展平成一个维度,即将 patch 矩阵展平为一批一维的序列输入; - 然后交换张量的第 1 维和第 2 维,让最后一维是序列的特征维度符合标准;
- 前面提到
self.position_ids形状为[1, Num_Patches],包含从 0 到Num_Patches - 1的索引(使用时使用该索引来查找对应的嵌入向量),通过 broadcast 应用到每个 batch 来增加可学习的位置信息。
def forward(self, pixel_values: torch.FloatTensor) -> torch.Tensor:
_, _, height, width = pixel_values.shape # [Batch_Size, Channels, Height, Width]
# Convolve the `patch_size` kernel over the image, with no overlapping patches since the stride is equal to the kernel size
# The output of the convolution will have shape [Batch_Size, Embed_Dim, Num_Patches_H, Num_Patches_W]
# where Num_Patches_H = height // patch_size and Num_Patches_W = width // patch_size
patch_embeds = self.patch_embedding(pixel_values)
# [Batch_Size, Embed_Dim, Num_Patches_H, Num_Patches_W] -> [Batch_Size, Embed_Dim, Num_Patches]
# where Num_Patches = Num_Patches_H * Num_Patches_W
embeddings = patch_embeds.flatten(2)
# [Batch_Size, Embed_Dim, Num_Patches] -> [Batch_Size, Num_Patches, Embed_Dim]
embeddings = embeddings.transpose(1, 2)
# Add position embeddings to each patch. Each positional encoding is a vector of size [Embed_Dim]
embeddings = embeddings + self.position_embedding(self.position_ids)
# [Batch_Size, Num_Patches, Embed_Dim]
return embeddings[!note] 内部协变量偏移(Internal Covariate Shift)是指在神经网络训练过程中,由于参数更新导致每一层输入分布不断变化的现象。这个概念由 Sergey Ioffe 和 Christian Szegedy 在提出 Batch Normalization 时引入的重要概念。
通俗来说,归一化层的缺失会导致模型花费大量时间来学习输入分布的变化,而不是专注于学习任务本身。
插一个八股:BatchNorm 跨批次对每个特征单独归一化,LayerNorm 跨特征对每个样本单独归一化,后者不依赖于批次统计信息,在 batch size = 1 时也有效,且训练——推理时行为完全一致(Andrej Karpathy 的描述是:天下苦 BN 久矣,训练不稳定且“bug”很多)。
下面是一个标准的 Transformer Encoder Layer,可以看到这里用的是 post-norm:
class SiglipEncoderLayer(nn.Module):
def __init__(self, config: SiglipVisionConfig):
super().__init__()
self.embed_dim = config.hidden_size
self.self_attn = SiglipAttention(config)
self.layer_norm1 = nn.LayerNorm(self.embed_dim, eps=config.layer_norm_eps)
self.mlp = SiglipMLP(config)
self.layer_norm2 = nn.LayerNorm(self.embed_dim, eps=config.layer_norm_eps)
# Ignore copy
def forward(
self,
hidden_states: torch.Tensor
) -> torch.Tensor:
# residual: [Batch_Size, Num_Patches, Embed_Dim]
residual = hidden_states
# [Batch_Size, Num_Patches, Embed_Dim] -> [Batch_Size, Num_Patches, Embed_Dim]
hidden_states = self.layer_norm1(hidden_states)
# [Batch_Size, Num_Patches, Embed_Dim] -> [Batch_Size, Num_Patches, Embed_Dim]
hidden_states, _ = self.self_attn(hidden_states=hidden_states)
# [Batch_Size, Num_Patches, Embed_Dim]
hidden_states = residual + hidden_states
# residual: [Batch_Size, Num_Patches, Embed_Dim]
residual = hidden_states
# [Batch_Size, Num_Patches, Embed_Dim] -> [Batch_Size, Num_Patches, Embed_Dim]
hidden_states = self.layer_norm2(hidden_states)
# [Batch_Size, Num_Patches, Embed_Dim] -> [Batch_Size, Num_Patches, Embed_Dim]
hidden_states = self.mlp(hidden_states)
# [Batch_Size, Num_Patches, Embed_Dim]
hidden_states = residual + hidden_states
return hidden_statesAttention 学习序列中元素的上下文关系和交互,而 MLP 增强了非线性变化能力,对 Attention 后的表示进行信息整合,同时提升了参数量。
class SiglipEncoder(nn.Module):
def __init__(self, config: SiglipVisionConfig):
super().__init__()
self.config = config
self.layers = nn.ModuleList(
[SiglipEncoderLayer(config) for _ in range(config.num_hidden_layers)]
)
# Ignore copy
def forward(
self,
inputs_embeds: torch.Tensor
) -> torch.Tensor:
# inputs_embeds: [Batch_Size, Num_Patches, Embed_Dim]
hidden_states = inputs_embeds
for encoder_layer in self.layers:
# [Batch_Size, Num_Patches, Embed_Dim] -> [Batch_Size, Num_Patches, Embed_Dim]
hidden_states = encoder_layer(hidden_states)
return hidden_statesclass SiglipVisionTransformer(nn.Module):
def __init__(self, config: SiglipVisionConfig):
super().__init__()
self.config = config
embed_dim = config.hidden_size
self.embeddings = SiglipVisionEmbeddings(config)
self.encoder = SiglipEncoder(config)
self.post_layernorm = nn.LayerNorm(embed_dim, eps=config.layer_norm_eps)
def forward(self, pixel_values: torch.Tensor) -> torch.Tensor:
# pixel_values: [Batch_Size, Channels, Height, Width] -> [Batch_Size, Num_Patches, Embed_Dim]
hidden_states = self.embeddings(pixel_values)
last_hidden_state = self.encoder(inputs_embeds=hidden_states)
last_hidden_state = self.post_layernorm(last_hidden_state)
return last_hidden_state整体回顾该组件的作用:接受 batch images 输入,返回 batch (image)embeddings:
class SiglipVisionModel(nn.Module):
def __init__(self, config: SiglipVisionConfig):
super().__init__()
self.config = config
self.vision_model = SiglipVisionTransformer(config)
def forward(self, pixel_values) -> Tuple:
# [Batch_Size, Channels, Height, Width] -> [Batch_Size, Num_Patches, Embed_Dim]
return self.vision_model(pixel_values=pixel_values) 前面提到在 ViT 类模型中,通常会添加一个特殊的 CLS token 作为序列的第一个位置,通过自注意力机制,这个 token 能够与所有图像补丁交互并收集信息。经过多层 Transformer 编码后,该 token 的最终表示被作为整个图像的全局嵌入表示,可以用于下游任务如分类或图像检索。
当然另一种办法就是对所有 patch embedding 取平均来代表整个图像的嵌入。
Processor
在 VLM 架构中,processor 通常是一个综合性组件,它包含了:
- Tokenizer: 处理文本部分
- Image Processor/Feature Extractor: 处理图像部分 这种设计允许 processor 同时处理多模态输入 (文本和图像)。
LLM 中只用对文本做 tokenize,但现在要在文本 token 中为图像 token 创建一个占位符(image token),这样 LLM Decoder 可以在运行时将这些占位符替换为图像。因此下面要定义一个特殊组件,接受用户的文本 prompt 和图像,对图像做预处理(缩放等)并创建带有 image token 的 text tokens。
[!note] Gemma 模型的 tokenizer 并没有为图像准备 special token,但是 PaliGemma 能够同时处理多模态的自回归生成,同时还能完成物体分割和检测的任务,关键点在于它对 vocab(词表)进行了扩展。可以看到下面代码中,加入了 1024 个用于检测的 loc token 和 108 个用于分割的 seg token:
EXTRA_TOKENS = [ f"<loc{i:04d}>" for i in range(1024) # 用零填充左边空位,字段总宽度,格式化为十进制整数 ] # These tokens are used for object detection (bounding boxes) EXTRA_TOKENS += [ f"<seg{i:03d}>" for i in range(128) ] # These tokens are used for object segmentation tokenizer.add_tokens(EXTRA_TOKENS)
这里不过多赘述,详见 HuggingFace 的博客。

添加 image token 占位符到 tokenizer 中,它随后会被视觉编码器提取的嵌入替换。
下面参数中:
num_image_token表示用多少个连续的<image>占位符代表一张图片
class PaliGemmaProcessor:
IMAGE_TOKEN = "<image>"
def __init__(self, tokenizer, num_image_tokens: int, image_size: int):
super().__init__()
self.image_seq_length = num_image_tokens
self.image_size = image_size
# tokenizer.add_tokens(EXTRA_TOKENS)
# Tokenizer described here: https://github.com/google-research/big_vision/blob/main/big_vision/configs/proj/paligemma/README.md#tokenizer
tokens_to_add = {"additional_special_tokens": [self.IMAGE_TOKEN]}
tokenizer.add_special_tokens(tokens_to_add)
self.image_token_id = tokenizer.convert_tokens_to_ids(self.IMAGE_TOKEN)
# We will add the BOS and EOS tokens ourselves
tokenizer.add_bos_token = False
tokenizer.add_eos_token = False
self.tokenizer = tokenizer接下来,我们会看到 PaliGemmaProcessor 如何将 <image> 这个特殊的占位符添加到 tokenizer 中。在模型实际运行时,这些占位符所占据的序列位置,将成为视觉编码器提取出的图像嵌入(特征)与文本序列进行交互的关键“连接点”。
在下面的参数定义中,num_image_tokens 定义了我们要用多少个连续的 <image> 占位符来代表一张图片。例如,如果设为 256,那么在输入给语言模型的序列中,就会有连续 256 个 <image> 标记,为模型提供了足够的“带宽”来整合和理解图像信息。
def __call__(
self,
text: List[str], # 输入的文本 prompt
images: List[Image.Image], # 输入的 PIL.Image
# 标准的分词器填充和截断策略
padding: str = "longest",
truncation: bool = True,
) -> dict:
assert len(images) == 1 and len(text) == 1, f"Received {len(images)} images for {len(text)} prompts." # 这里只实现了一对图像——文本
pixel_values = process_images(
images,
size=(self.image_size, self.image_size),
resample=Image.Resampling.BICUBIC, # 选择双三次插值算法进行图像重采样,在调整图像尺寸时保留更多细节与纹理,提高视觉质量
rescale_factor=1 / 255.0, # 像素值重缩放到 [0, 1]
image_mean=IMAGENET_STANDARD_MEAN, # 标准化均值 (近似 [0.5, 0.5, 0.5])
image_std=IMAGENET_STANDARD_STD, # 标准化标准差 (近似 [0.5, 0.5, 0.5])
)
# 这会将像素值转换到 [-1, 1]
# Convert the list of numpy arrays to a single numpy array with shape [Batch_Size, Channel, Height, Width]
pixel_values = np.stack(pixel_values, axis=0) # 堆叠成一个 batch
# Convert the numpy array to a PyTorch tensor
pixel_values = torch.tensor(pixel_values)其中图像的处理流程:
图像 (PIL.Image) → 调整大小 → NumPy 数组 → 像素值缩放 (0-1) → 标准化 (均值/标准差) → 转置通道维度 → PyTorch 张量[!IMPORTANT] 构造 VLM 专属的输入序列:不仅仅是拼接字符串,还构建了一个严格遵循模型预训练格式的输入序列。任何偏差(如缺少
\n或bos_token位置错误)都可能导致模型无法正确理解或处理提示:def add_image_tokens_to_prompt(prefix_prompt, bos_token, image_seq_len, image_token): # 末尾拼接的 '\n' 在该模型里非常重要,保证和训练时的数据格式规范对齐 return f"{image_token * image_seq_len}{bos_token}{prefix_prompt}\n"
# Prepend a `self.image_seq_length` number of image tokens to the prompt
input_strings = [
add_image_tokens_to_prompt(
prefix_prompt=prompt,
bos_token=self.tokenizer.bos_token,
image_seq_len=self.image_seq_length, # <image>占位符的数量
image_token=self.IMAGE_TOKEN, # "<image>"字符串
)
for prompt in text
]然后经过 tokenizer 做最终的转换:
# 将包含<image>占位符的字符串序列转换为模型可读的 input_ids 和 attention_mask
inputs = self.tokenizer(
input_strings,
return_tensors="pt",
padding=padding,
truncation=truncation,
)
# 返回一个字典,包含处理好的图像张量和文本相关的 token 序列
return_data = {"pixel_values": pixel_values, **inputs}
return return_data```
为了便于理解,这里用一个例子$^{[2]}$来可视化最后的形态:
```python
from transformers.utils.attention_visualizer import AttentionMaskVisualizer
visualizer = AttentionMaskVisualizer("google/paligemma2-3b-mix-224")
visualizer("<img> What is in this image?")
图中黄色字是
<image>Prefix-LM Masking
该工作使用了 prefix-LM 的掩码策略 。这意味着对图像和“前缀 Prefix”(任务指令 prompt)进行完全(双向)注意力,允许图像 token“预见”任务,通过一个 [sep]token(其实就是是 \n)与后缀分隔开。而“后缀 Suffix”(答案)则是自回归生成的。他们的消融实验表明,这种方法比对前缀或图像标记进行自回归掩码的效果更好。
PaliGemma 首先会将图像和输入的文字 prompt(prefix,即关于图片的任务指令),形成统一的理解;然后,它就像写作文一样,根据这份理解逐字逐句地自回归生成答案(suffix 文本)。
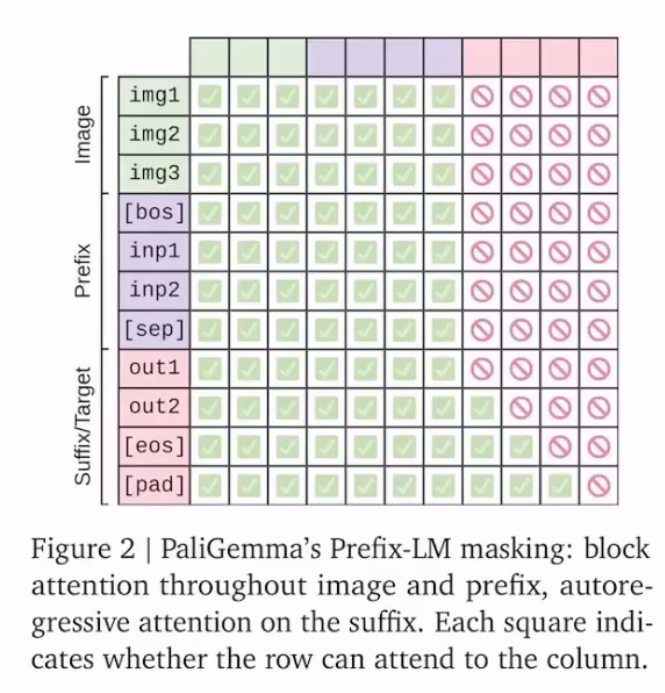
LLM Decoder
LLM 本身的工作流程如下图(来自 groundlight.ai 的博客)所示:
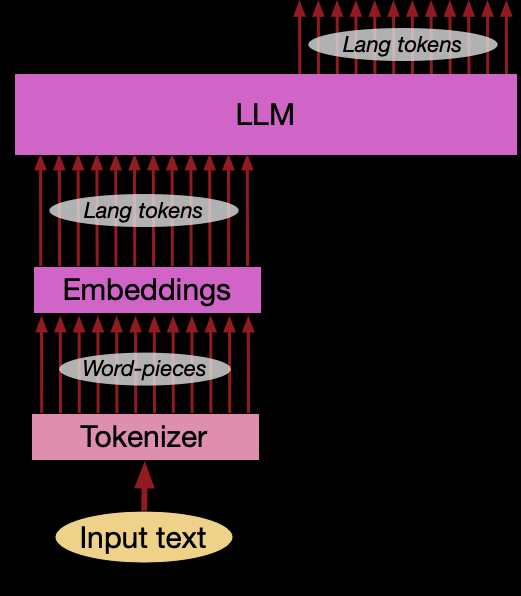
而下面是 VLM 的工作流程,前面提到 Preprocessor 会宗包含了 tokenizer 和 image processor

class PaliGemmaForConditionalGeneration(nn.Module):
def __init__(self, config: PaliGemmaConfig):
super().__init__()
self.config = config
self.vision_tower = SiglipVisionModel(config.vision_config)
self.multi_modal_projector = PaliGemmaMultiModalProjector(config)
self.vocab_size = config.vocab_size
language_model = GemmaForCausalLM(config.text_config)
self.language_model = language_model
self.pad_token_id = self.config.pad_token_id if self.config.pad_token_id is not None else -1
# weight tying
def tie_weights(self):
return self.language_model.tie_weights()[!note] 这里要提一嘴的是,Embedding Layer 和 Decoder 最后输出时的线性层的操作基本互为逆操作,前者是将 token ids 转为 embedding,后者则是将上下文 embedding 转为 vocab size。所以一些模型用了一种称为 weight tying 的方法,即让这两层共享参数来减少模型总参数(由于 vocab size 相当大,这个操作大约能省 10% )。
Forward 中,先获得是所有输入 token 的 embedding,包括 <image> 占位符的 embedding,但这里图像占位符的 embedding 并不对应实际的图像特征,所以后面会用正确的 embedding 这部分替换掉。

这张图里显示的是 patch token 的可视化结果。来源于 VLM 视觉部分处理图像后生成的特征向量,在语言模型词汇表中找到的最接近的文本词元及其关联强度。 这个 poor 有点出戏…
def forward(
self,
input_ids: torch.LongTensor = None,
pixel_values: torch.FloatTensor = None,
attention_mask: Optional[torch.Tensor] = None,
kv_cache: Optional[KVCache] = None,
) -> Tuple:
# Make sure the input is right-padded
assert torch.all(attention_mask == 1), "The input cannot be padded"
# 1. Extra the input embeddings
# shape: (Batch_Size, Seq_Len, Hidden_Size)
inputs_embeds = self.language_model.get_input_embeddings()(input_ids)图像的 patch token 经过 Vision Tower (SigLip) 提取出 patch_size 个特征向量(embedding):
# 2. Merge text and images
# [Batch_Size, Channels, Height, Width] -> [Batch_Size, Num_Patches, Embed_Dim]
selected_image_feature = self.vision_tower(pixel_values.to(inputs_embeds.dtype))
[!tip] LLM Embedding 层的形状:
(vocab_size, embedding_dim)
在 SigLip 处理之后,这些 image token 仍然处于 SigLip 的向量空间中,这与 LLM 的 text token 空间无关。对于 SigLip 这些向量是 768 维的。但像我们这里用 Gemma LLM 使用的是 2048 维的向量(hidden_size)。因此,VLM 最重要的部分就是下面的 Projection Layer,它将图像 patch 向量转换到 LLM 的 text token 空间。
# [Batch_Size, Num_Patches, Embed_Dim] -> [Batch_Size, Num_Patches, Hidden_Size]
image_features = self.multi_modal_projector(selected_image_feature)这里投影层就是一个线性层:
class PaliGemmaMultiModalProjector(nn.Module):
def __init__(self, config: PaliGemmaConfig):
super().__init__()
self.linear = nn.Linear(config.vision_config.hidden_size, config.vision_config.projection_dim, bias=True)
def forward(self, image_features):
# [Batch_Size, Num_Patches, Embed_Dim] -> [Batch_Size, Num_Patches, Projection_Dim]
hidden_states = self.linear(image_features)
return hidden_states重点看一下这个 在_merge_input_ids_with_image_features方法,其中 image mask 和 text mask 是用于识别和区分输入序列中不同类型 token 的关键机制。
# 3. Merge the embeddings of the text tokens and the image tokens
inputs_embeds, attention_mask, position_ids = self._merge_input_ids_with_image_features(image_features, inputs_embeds, input_ids, attention_mask, kv_cache)Image Mask 用于标识出输入序列中所有的图像 token 位置(值为 True),通过检查input_ids中值等于image_token_index(见 added_tokens.json) 的位置,只有在这些位置,模型会插入来自 vision tower 的图像特征:
# Shape: [Batch_Size, Seq_Len]. True for image tokens
image_mask = input_ids == self.config.image_token_index # "<image>": 257152Text Mask 用于标识出输入序列中所有的文本 token 位置(值为 True),通过检查既不是图像 token 也不是 padding token 的位置得到,在这些位置,模型会插入文本的词嵌入:
# Shape: [Batch_Size, Seq_Len]. True for text tokens
text_mask = (input_ids != self.config.image_token_index) & (input_ids != self.pad_token_id)假设输入序列为:<image><image><image><bos>描述这张图片,图像经过处理后的到 3 个 patch 嵌入,文本处理后得到对应的 token 嵌入,分别得到图像和文本的 mask,然后将 mask 扩展到嵌入维度,以便能用于选择性填充嵌入张量:
text_mask_expanded = text_mask.unsqueeze(-1).expand(-1, -1, embed_dim)
image_mask_expanded = image_mask.unsqueeze(-1).expand(-1, -1, embed_dim)然后应用 mask,对于图像嵌入使用masked_scatter是因为图像特征和最终嵌入的序列长度不同,不能直接用torch.where:
# 放置文本嵌入
final_embedding = torch.where(text_mask_expanded, inputs_embeds, final_embedding)
# 放置图像嵌入
final_embedding = final_embedding.masked_scatter(image_mask_expanded, scaled_image_features)最后输入语言模型:
# 4. 输入语言模型
outputs = self.language_model(
attention_mask=attention_mask,
position_ids=position_ids,
inputs_embeds=inputs_embeds,
kv_cache=kv_cache,
)
return outputs得到最后的 logits(包含在一个可能还有 KV-Cache 的字典里):
class GemmaForCausalLM(nn.Module):
# ... (其他代码) ...
def forward(
self,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.LongTensor] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
kv_cache: Optional[KVCache] = None,
) -> Tuple:
# ... (模型前向传播) ...
outputs = self.model( # self.model 是 GemmaModel
attention_mask=attention_mask,
position_ids=position_ids,
inputs_embeds=inputs_embeds,
kv_cache=kv_cache,
)
hidden_states = outputs # 这是来自 GemmaModel 的最后一个隐藏状态
logits = self.lm_head(hidden_states) # lm_head 是一个线性层,输出维度为词汇表大小
logits = logits.float()
return_data = {
"logits": logits,
}
if kv_cache is not None:
# 返回更新后的缓存
return_data["kv_cache"] = kv_cache
return return_dataProspectives
- VLM 如何更有效地利用图片信息,而不会忽略图片只关注文本
- VLM + RL,提升对于图片中信息的推理能力以完成视觉推理任务,及其可解释性