https://www.youtube.com/watch?v=HoKDTa5jHvg
本文主要以该视频的教学逻辑为主线,结合讲解内容进行整理和阐述,如有错误欢迎在评论区纠正!
Deep Unsupervised Learning using Nonequilibrium Thermodynamics
这篇论文奠定了扩散模型的理论基础。作者提出了一种基于非平衡热力学的生成模型,通过逐步添加和去除噪声来实现数据生成。这为后续的扩散模型研究提供了重要的理论支持。
我们对图像应用大量噪声,然后用神经网络去噪。如果这个神经网络学得很好,那可以从完全随机的噪声开始最终得到我们训练数据中的图像。
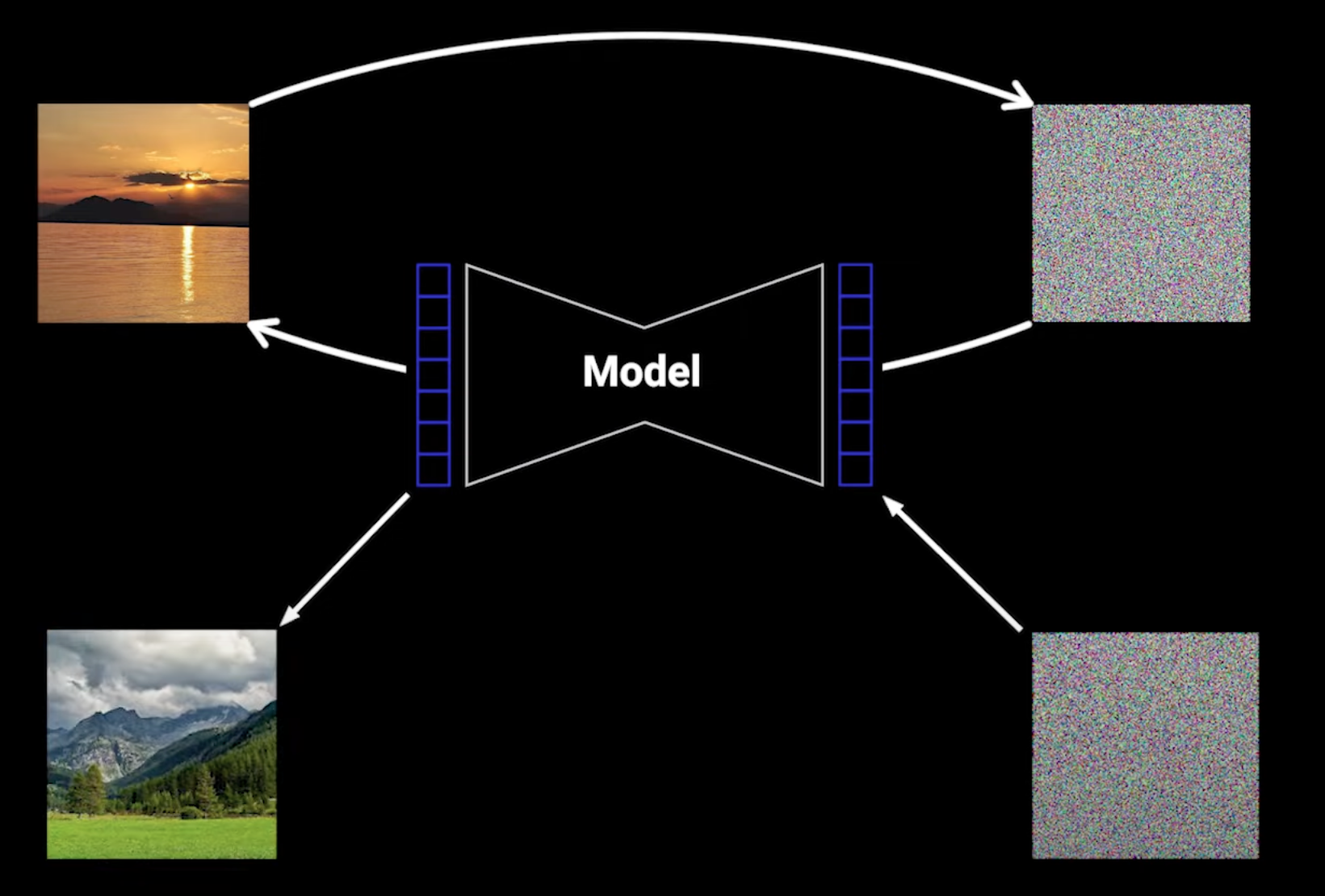
迭代地对图像施加噪声,步骤足够多时图像会完全变成噪声,使用正态分布作为噪声源:

从纯粹的噪声到图像,涉及一个学习一步步去噪的神经网络。
为什么是逐渐去噪?作者在论文中提到”一步直接完成去噪”的结果很糟糕。
那么这个网络是什么样的?它又要预测什么?
Denoising Diffusion Probabilistic Models
这篇论文提出了去噪扩散概率模型(DDPM),显著提高了扩散模型的生成质量和效率。通过引入简单的去噪网络和优化的训练策略,DDPM 成为了扩散模型领域的一个重要里程碑。
作者讨论了神经网络可以预测的三种目标:
预测每个时间步的噪声均值 (predict the mean of the noise at each timestep)
- 即预测条件分布 p(xt−1∣xt) 的均值
- 方差是 fixed 的,不可学习
预测原始图像 (predict x0 directly)
- 直接预测原始、未被污染的图像
- 实验证明这种方式效果较差
预测添加的噪声 (predict the added noise)
- 预测在正向过程中添加的噪声 ε
- 和第一种方法(预测噪声均值)实际上是数学上等价的,只是参数化方式不同,它们可以通过简单的变换相互转换
论文最终选择了预测噪声(第三种方式)作为主要方法,因为这种方式训练更稳定且效果更好
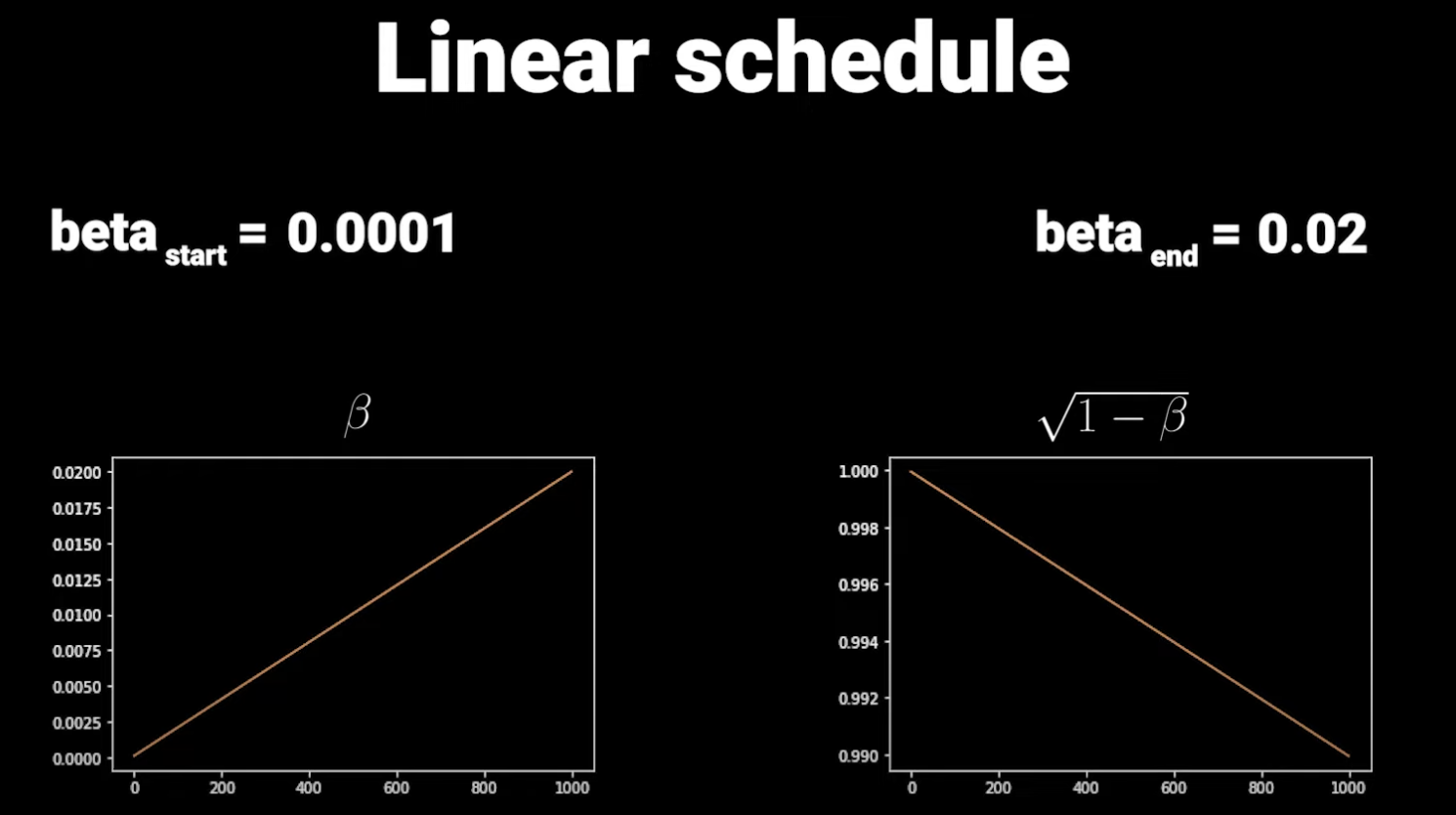
这里每一步添加的噪声量是不固定的,通过一个 Linear Schedule 来控制噪声添加,防止训练过程不稳定。
大概长下面这样: 
可以看到最后最后几个时间步都接近完全噪声了,信息很少,此外整体来看信息摧毁得太快了,因此 OpenAI 使用了 Cosine Schedule 解决了这两个问题:

随着这篇论文一起发表的是一个名叫 U-Net 的模型架构:
这个模型在中间有一个 Bottleneck(也就是参数量较小的层),用 Downsample-Block 和 Resnet-Block 来将输入图像投影到小分辨率,输出时用 Upsample-Block 将其投影回初始尺寸。
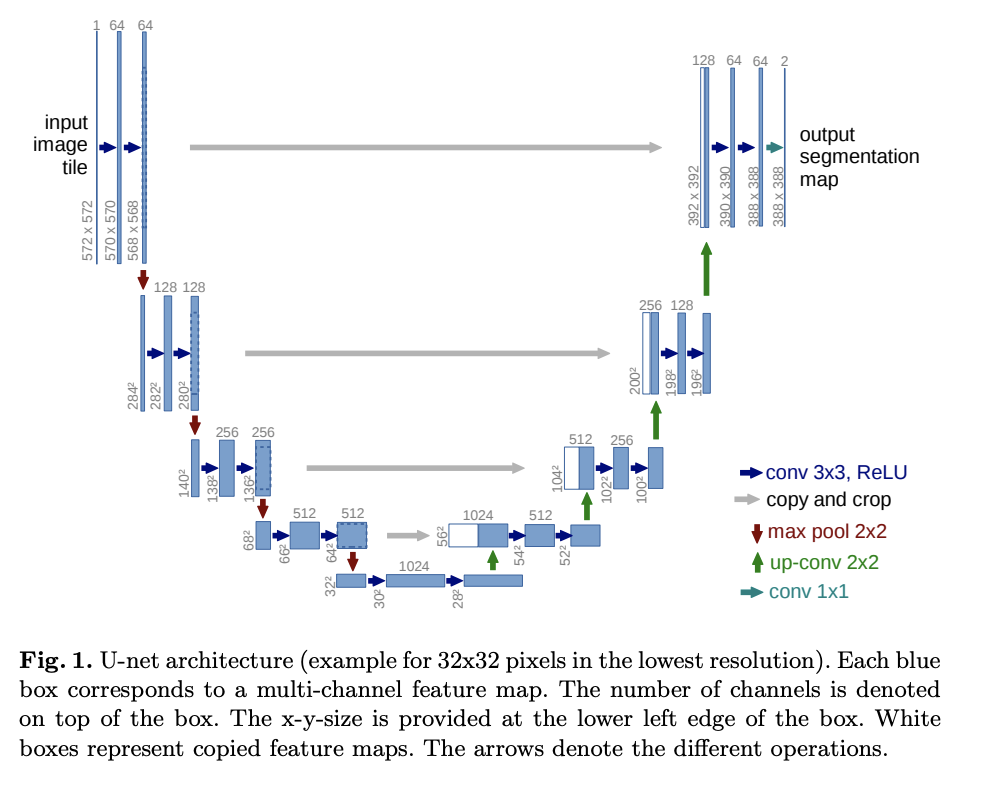
在某些分辨率下,作者加入了 Attention-Block 并在相同分辨率空间的层之间做 Skip-Connection。模型是被涉及为针对每一个时间步的,这是通过 Transformer 中的正弦位置编码嵌入来实现的,嵌入被投影到每个 Residual-Block 中。模型还能结合 Schedule,在不同时间步中去除不同量的噪声来提升生成效果,后面会详细讨论。
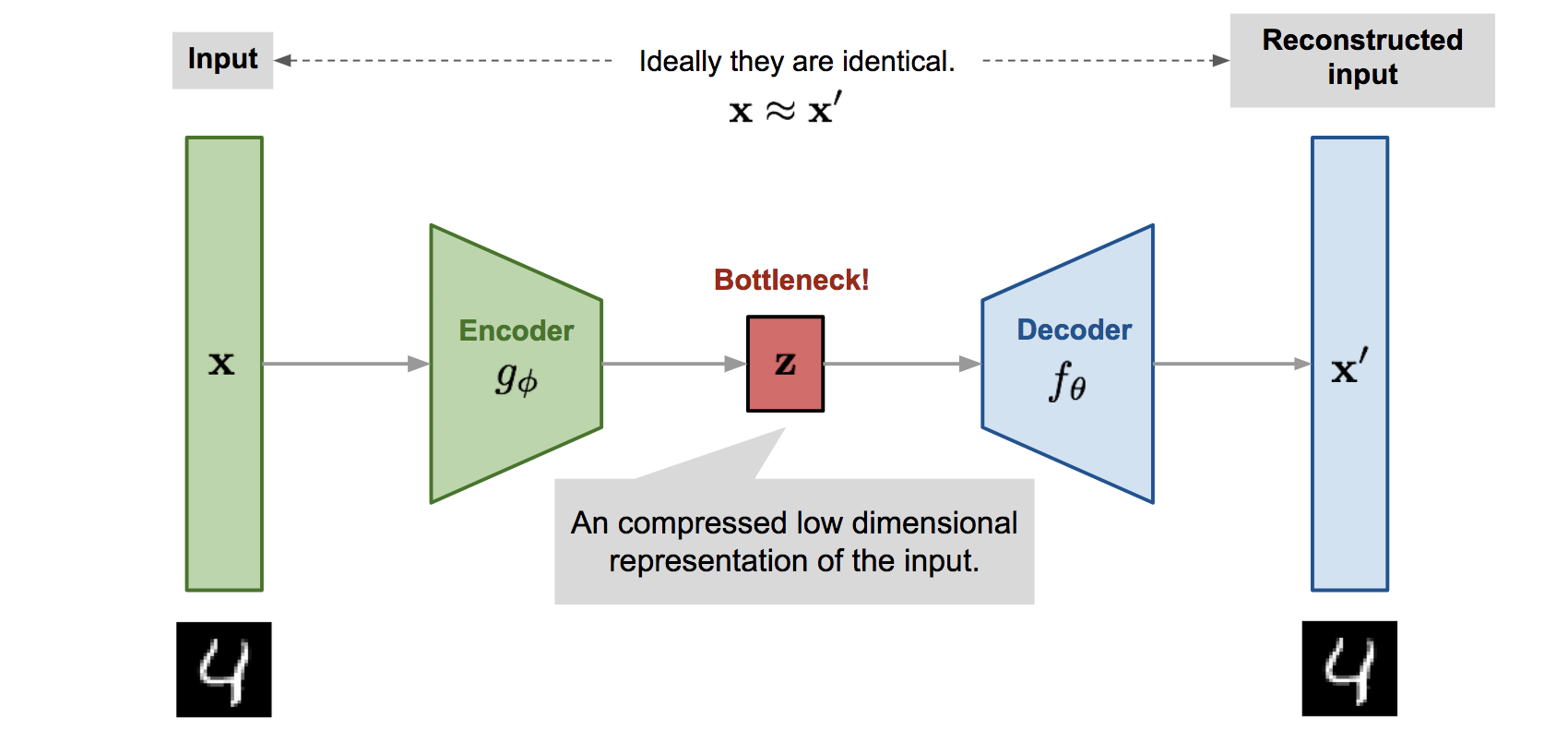
Bottleneck(瓶颈层)的概念最初是在无监督学习方法”自编码器(Autoencoder)“中提出并广泛使用的。作为自编码器架构中维度最低的隐藏层,它位于编码器和解码器之间,构成了网络中最窄的部分,强制网络学习数据的压缩表示,最小化重建误差并起到正则化作用:Lreconstruction=∥X−Decoder(Encoder(X))∥2
OpenAI 在他们的第二篇论文 Diffusion Models Beat GANs on Image Synthesis 中通过改进架构显著改善了整体效果:
- 增加网络深度(更多层),减少宽度(每层的通道数)
- 增加 Attention-Block 数量
- 并扩大每个 Attention Block 中的 heads 数量
- 引入 BigGAN 风格的 Residual Block 用于上采样和下采样
- 引入 Adaptive Group Normalization (AdaGN),通过条件信息(如时间步)来动态调整归一化的参数
- 用 Separate Classifier Guidance 帮助模型生成某类图片
- Xt 代表在 t 时间步的图像,即 X0 是原始图像。可以简记 t 越小噪声越少:

- 噪声的最终图像是一个 isotropic(各方向相同)的完全噪声,记作 XT,在最开始的研究中 T=1000,后续工作会将其减小很多:

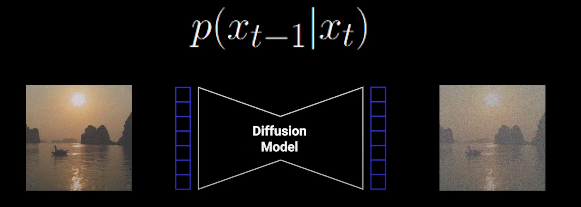
- Forward Process:q(xt∣xt−1),输入xt−1图像输出一张噪声更多的图像Xt:
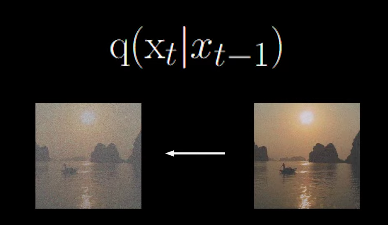
- Backward Process:p(xt−1∣xt),输入 xt 图像用神经网络输出一个降噪的图像 xt−1:
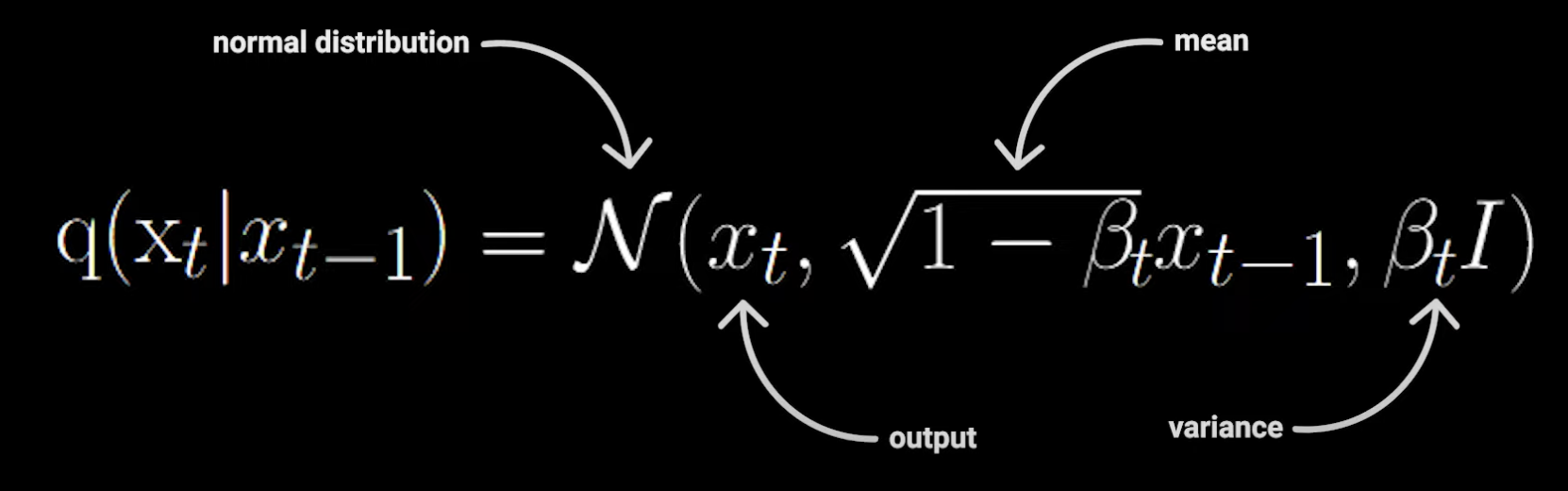
其中,
- 1−βtxt−1 是分布的均值(mean);βt 是 noise schedule 参数,范围在 0 到 1 之间,配合1−βt 对噪声完成缩放,随着时间步增加而减小,表示保留的原始信号部分。
- βtI 是分布的协方差矩阵(covariance matrix),I 是单位矩阵,表示协方差矩阵是对角的且各维度独立,随着时间步增加,添加的噪声量增大。
现在我们只需要将这个步骤不断迭代执行即可得到 1000 步后的结果,但其实这些可以一步完成。
重参数化技巧在扩散模型和其他生成模型(如变分自编码器,VAE)中非常重要。它的核心思想是将随机变量的采样过程转化为一个确定性函数加上一个标准化的随机变量。这种转换使得模型可以通过梯度下降进行优化,因为它消除了采样过程中的随机性对梯度计算的影响。
这里通过一个简单的例子来解释其意义
你要实现一个扔骰子可以有两种方式,
# 1. 直接掷骰子(随机采样)
def roll_dice():
return random.randint(1, 6)
result = roll_dice()
- 第二种则是让随机性在函数外部,函数本身是确定性的:
# 2. 将随机性分离出来
random_number = random.random() # 生成 0 到 1 之间的随机数
def transformed_dice(random_number):
# 将 0-1 的随机数映射到 1-6
return math.floor(random_number * 6) + 1
result = transformed_dice(random_number)
概率论中我们学过:如果 X 是一个随机变量,且 X∼N(0,1),那么有:aX+b∼N(b,a2)
因此对于正态分布 N(μ,σ2) 可以通过以下方式生成样本:
x=μ+σ⋅ϵ 其中 ϵ∼N(0,1) 是标准正态分布。
那同理,在正态分布中,
# 直接从目标正态分布采样
x = np.random.normal(mu, sigma)
# 先从标准正态分布采样
epsilon = np.random.normal(0, 1)
# 然后通过确定性变换得到目标分布
x = mu + sigma * epsilon
对应到模型训练中涉及的梯度计算时,
不使用重参数化:
def sample_direct(mu, sigma):
return np.random.normal(mu, sigma)
# 这种情况下很难计算关于 mu 和 sigma 的梯度
# 因为随机采样操作阻断了梯度传播
使用重参数化:
def sample_reparameterized(mu, sigma):
epsilon = np.random.normal(0, 1) # 梯度不需要通过这里传播
return mu + sigma * epsilon # 可以轻松计算 mu 和 sigma 的梯度
以 VAE(变分自编码器)为例:
class VAE(nn.Module):
def __init__(self):
super(VAE, self).__init__()
self.encoder = Encoder() # 输出 mu 和 sigma
self.decoder = Decoder()
def reparameterize(self, mu, sigma):
# 重参数化技巧
epsilon = torch.randn_like(mu) # 从标准正态分布采样
z = mu + sigma * epsilon # 确定性变换
return z
def forward(self, x):
# 编码器输出 mu 和 sigma
mu, sigma = self.encoder(x)
# 使用重参数化采样
z = self.reparameterize(mu, sigma)
# 解码器重建输入
reconstruction = self.decoder(z)
return reconstruction
想象你在制作奶茶:
不使用重参数化:
- 直接制作一杯特定甜度的奶茶
- 如果不好喝,你不知道是糖放多了还是放少了
使用重参数化:
- 先准备一杯标准浓度的糖水(ϵ)
- 然后通过调整糖水的量(μ)和稀释程度(σ)来达到目标甜度
- 如果不好喝,你可以清楚地知道是糖水量还是稀释程度需要调整(参数可优化)
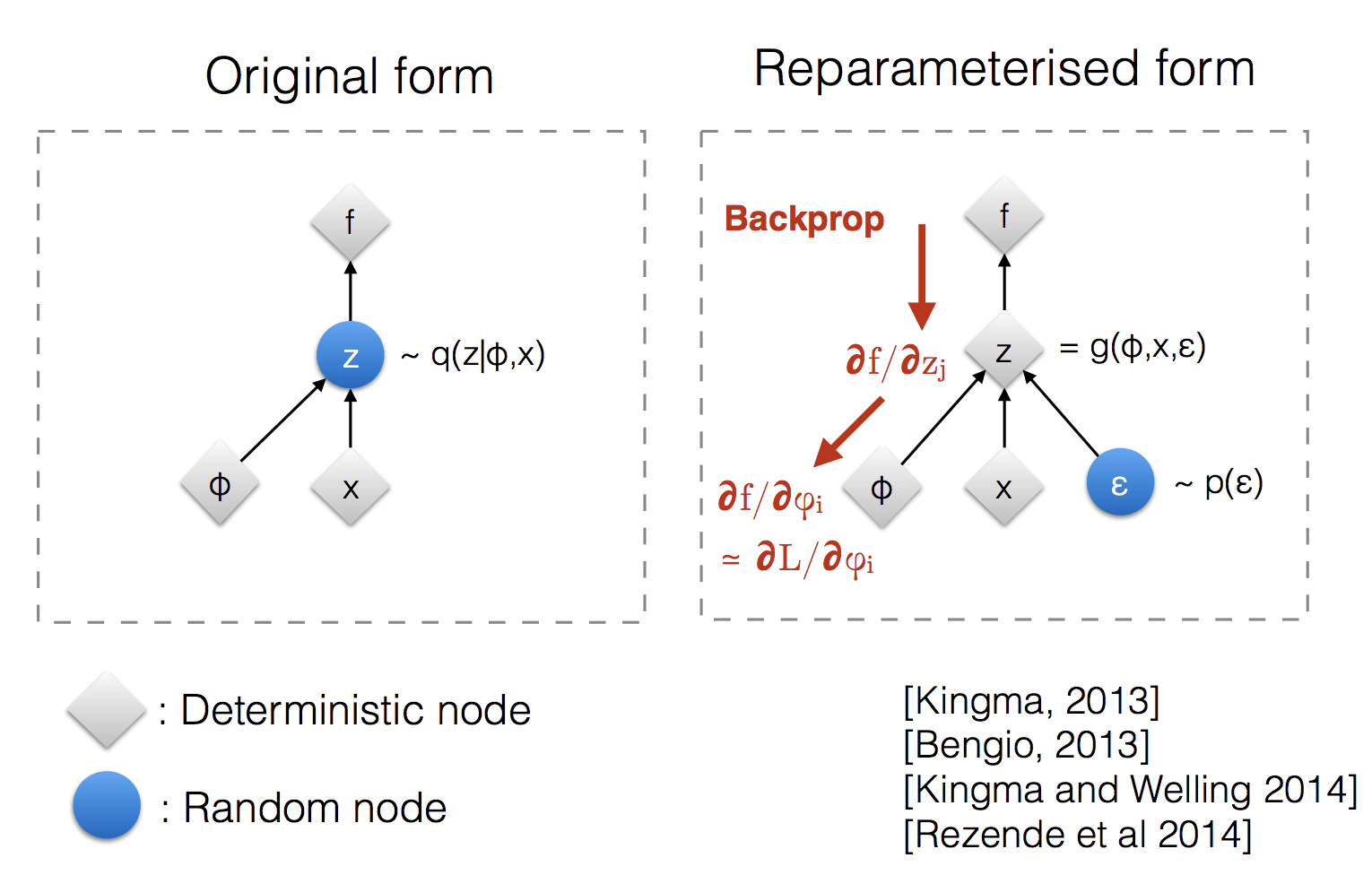
总之,经过重参数化:
- 梯度可以通过确定性变换传播
- 参数可以通过梯度下降优化
- 随机性被隔离,不影响梯度计算
从 xt−1 到 xt 的转移:
- 给定 xt−1,我们希望生成 xt。
- 对 q(xt∣xt−1)=N(xt;1−βtxt−1,βtI) 使用重新参数化技巧,
∵Σ∴σ=βtI,σ2=βt=βt 可将 xt 表示为 xt−1 的确定性变换加上噪声项:
xt=1−βtxt−1+βtϵ - 这里,1−βtxt−1 是均值部分,βtϵ 是噪声部分。由于 ϵ 是标准正态分布的样本,与模型参数无关,因此在反向传播时,梯度只需考虑 1−βt 和 βt 对应的参数。这使得模型可以通过梯度下降进行有效优化。
我们用 αt 简化记法 & 记录其乘积的累计:
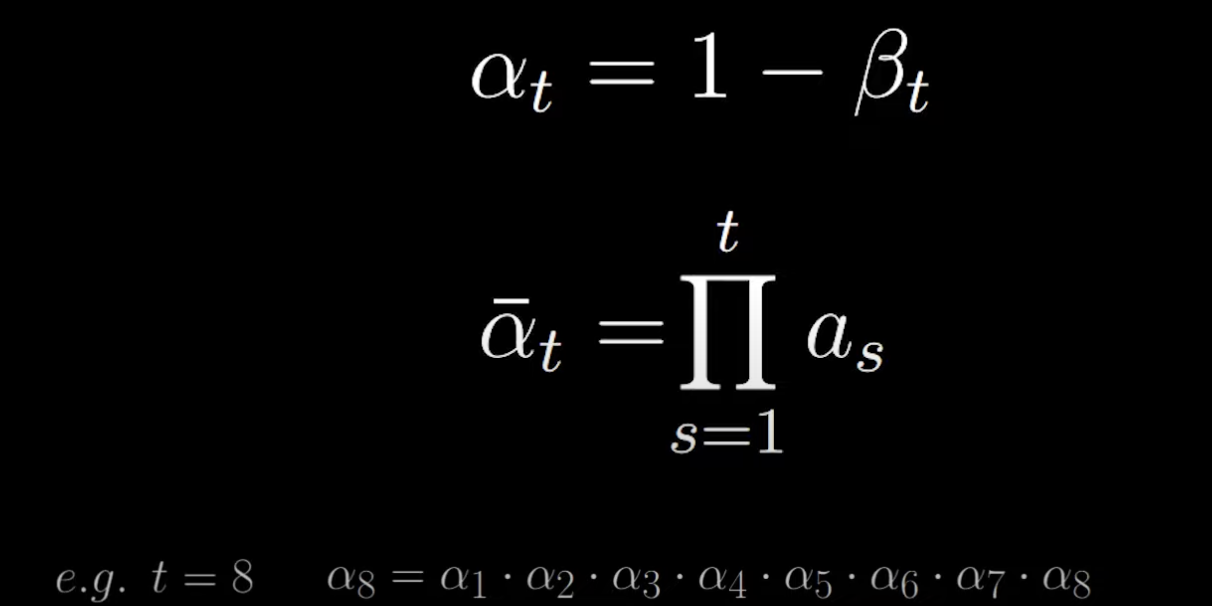
可得:
q(xt∣xt−1)=αtxt−1+1−αtϵ 计算两步转移:从 xt−2 到 xt
xt−1xtxt=αt−1xt−2+1−αt−1ϵt−1=αt(αt−1xt−2+1−αt−1ϵt−1)+1−αtϵt=αtαt−1xt−2+αt(1−αt−1)ϵt−1+1−αtϵt 因为 ϵt−1 和 ϵt 是独立的标准正态分布,合并噪声部分为一个新的噪声项 ϵ∼N(0,I):
xt=αtαt−1xt−2+1−αtαt−1ϵ 同理:
xtxtxt通过xt∵αˉt∴当=αtαt−1xt−2+1−αtαt−1ϵ=αtαt−1αt−2xt−3+1−αtαt−1αt−2ϵ=αtαt−1⋯α1α0x0+1−αtαt−1⋯α1α0ϵ归纳法,可以推出:=s=k+1∏tαsxk+1−s=k+1∏tαsϵ=s=1∏tαsk=0时,xt=αˉtx0+1−αˉtϵ(ϵ∼N(0,I)) 完整推导流程如下:
q(xt∣xt−1)q(xt∣xt−2)q(xt∣xt−3)q(xt∣x0)=N(xt;1−βtxt−1,βtI)=1−βtxt−1+βtϵ=αtxt−1+1−αtϵ=αtαt−1xt−2+1−αtαt−1ϵ=αtαt−1αt−2xt−3+1−αtαt−1αt−2ϵ=αtαt−1⋯α1α0x0+1−αtαt−1⋯α1α0ϵ=αˉtx0+1−αˉtϵ(ϵ∼N(0,I))=N(xt;αˉtx0,(1−αˉt)I) 由于方差是固定的而不需要去学习 (见 1.3),所以我们只需要神经网络去预测均值:
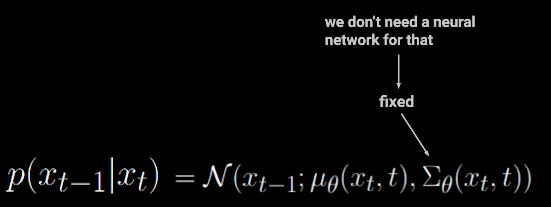
我们的最终目标是预测两个时间步中的噪声,现在从损失函数开始分析:
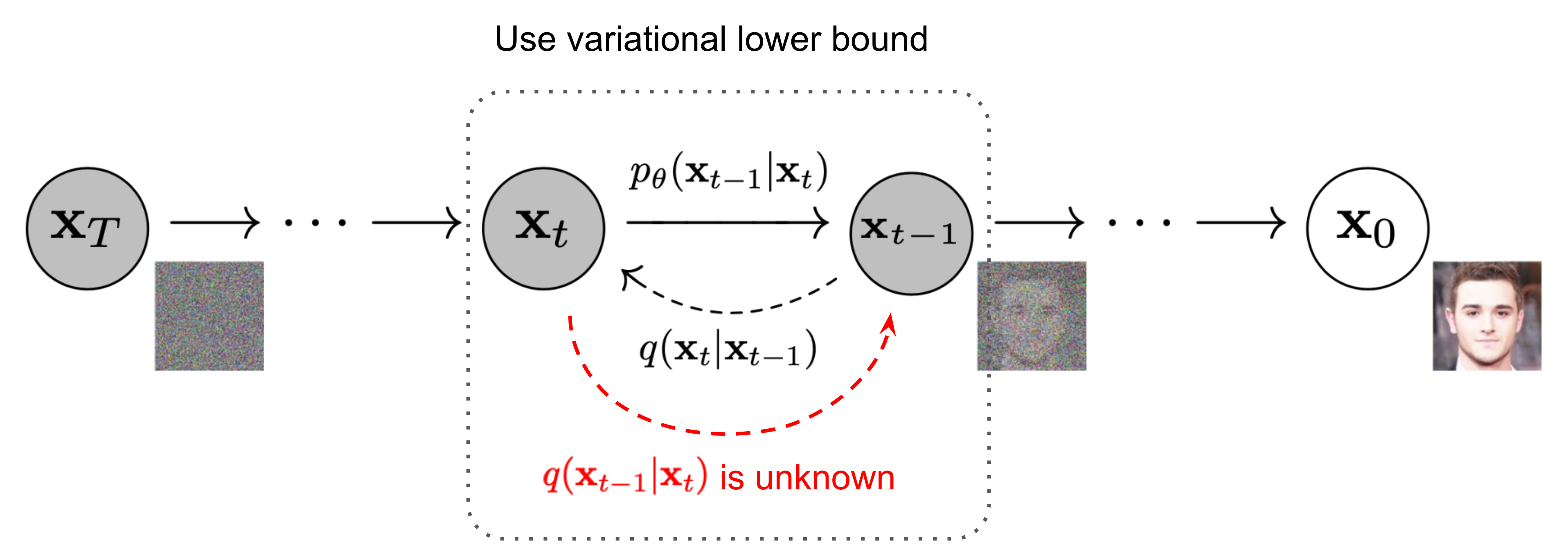
−log(pθ(x0)) 但是这个负对数似然中,x0的概率依赖前面的所有其它时间步。我们可以学习一个逼近这些条件概率的模型作为解决方案,这里就需要用到 Varational Lower Bound (变分下界) 来得到一个更好计算的公式。
假设我们有一个无法计算的函数f(x),在我们的场景中是负对数似然,我们可以找一个始终满足 g(x)≤f(x) 的可计算函数 g(x) ,那么优化 g(x) 也可以让 f(x) 增加: 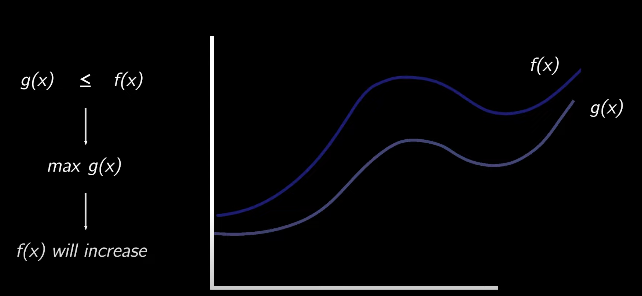
我们这里通过减去 KL 散度来保证这点,KL 散度是衡量两个分布相似度的指标,始终非负:
DKL(p∥q)=∫xp(x)logq(x)p(x)dx 减去一个始终非负的项可以保证结果始终小于原始函数,这里用 ”+” 是因为我们想要最小化损失,所以加上后始终保证原始的负对数似然大:
−log(pθ(x0))≤−log(pθ(x0))+DKL(q(x1:T∣x0)∥pθ(x1:T∣x0)) 这种形式下,因为负对数似然还在,下界仍然是不可计算的,我们需要得到一个更好的表达。首先将 KL 散度重写为两个项的对数比:
−log(pθ(x0))≤−log(pθ(x0))+DKL(q(x1:T∣x0)∥pθ(x1:T∣x0))=−log(pθ(x0))+log(pθ(x1:T∣x0)q(x1:T∣x0)) 再对其分母应用贝叶斯法则:
pθ(x1:T∣x0)=pθ(x0)pθ(x0∣x1:T)pθ(x1:T) [!NOTE]
贝叶斯法则: p(A∣B)=p(B)p(B∣A)p(A)
上式的分子部分 pθ(x0∣x1:T)pθ(x1:T) 实际上是联合概率 pθ(x0,x1:T),因为:
pθ(x0,x1:T)=pθ(x0∣x1:T)pθ(x1:T) 通常, pθ(x0:T) 表示 x0 和所有中间步骤 x1:T 的联合概率,即:
pθ(x0:T)=pθ(x0,x1:T) [!NOTE] pθ(x0:T) 表示从时间步 0 到 T 的所有状态 x0,x1,…,xT 的联合概率分布。
pθ(x0:T)=p(xT)t=1∏Tpθ(xt−1∣xt)
代入有:
log(pθ(x1:T∣x0)q(x1:T∣x0))=logpθ(x0)pθ(x0:T)q(x1:T∣x0)将分母pθ(x0)pθ(x0:T)转化为乘法形式:pθ(x0)pθ(x0:T)1=pθ(x0:T)pθ(x0)=log(pθ(x0:T)q(x1:T∣x0))+log(pθ(x0)) 即按照下图中的流程得到最后形式:
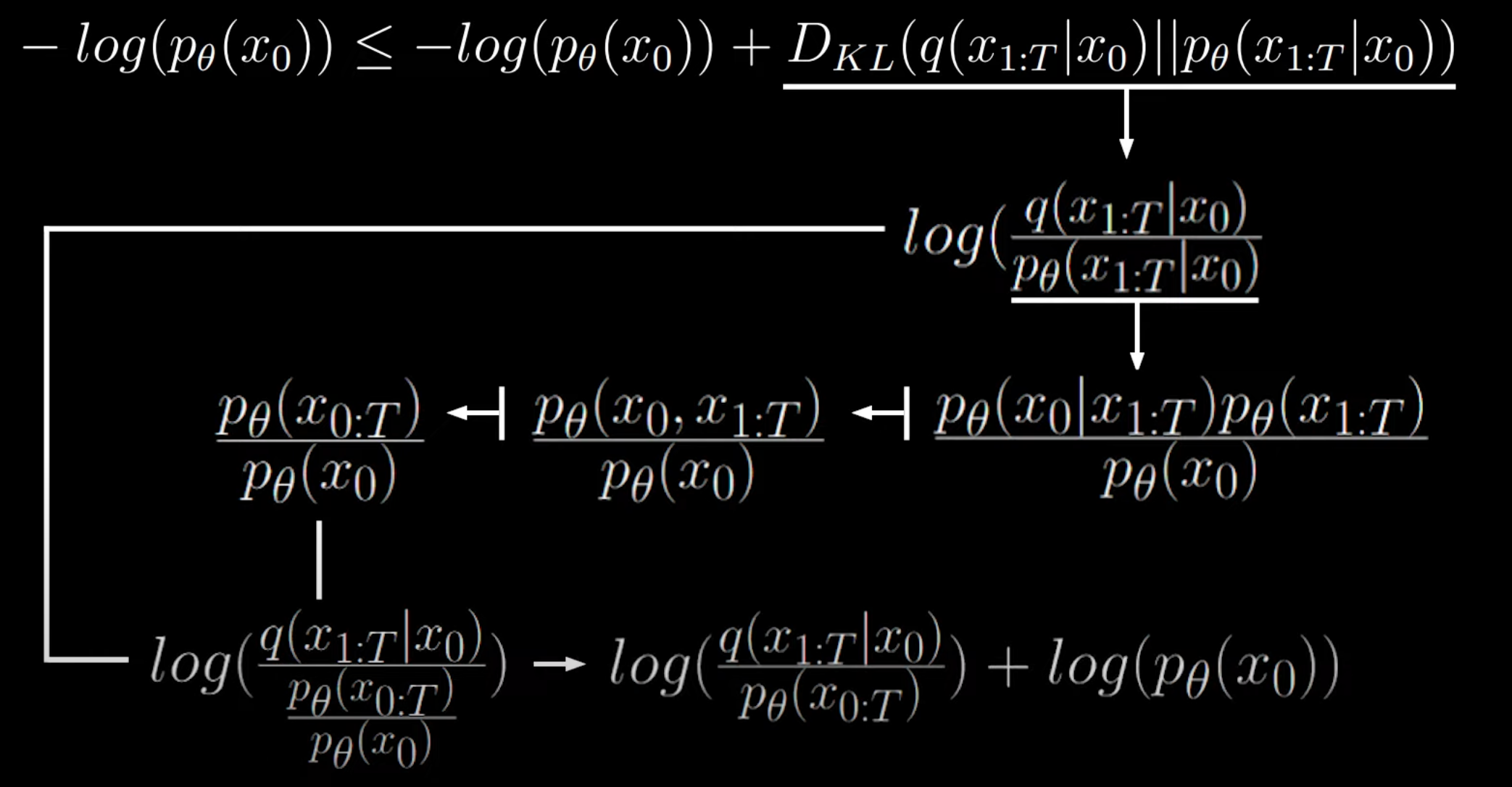
豁然开朗,烦人的两项消掉了:
−log(pθ(x0))≤−log(pθ(x0))+log(pθ(x0:T)q(x1:T∣x0))+log(pθ(x0))=log(pθ(x0:T)q(x1:T∣x0)) 这样就得到了可以最小化的下限,并且式中的内容都是已知的:
- 分子是正向过程的联合概率分布:q(x1:T∣x0)=∏t=1Tq(xt∣xt−1);
- 分母是逆向过程的联合概率分布:pθ(x0:T)=p(xT)∏t=1Tpθ(xt−1∣xt)
为了让其有解析解,还需要几个额外的重组步骤:
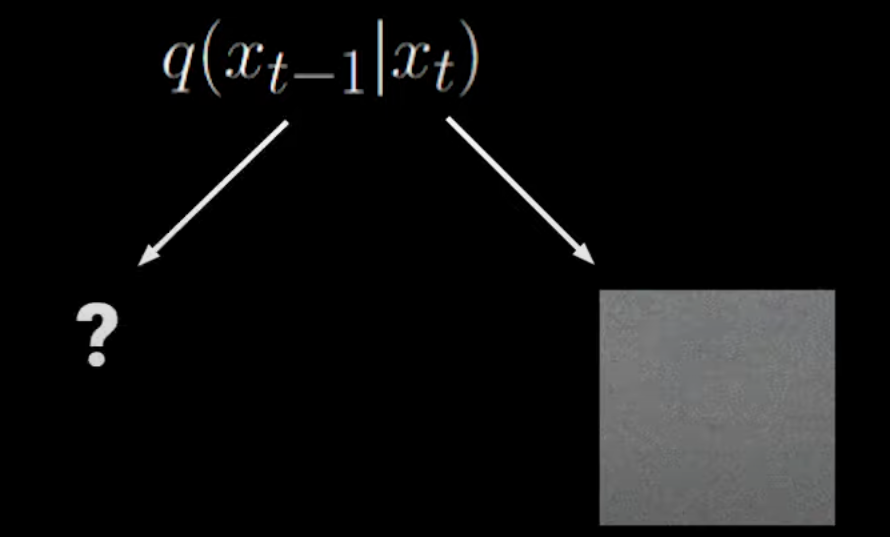
log(pθ(x0:T)q(x1:T∣x0))=log(p(xT)∏t=1Tpθ(xt−1∣xt)∏t=1Tq(xt∣xt−1))=log(p(xT)1⋅∏t=1Tpθ(xt−1∣xt)∏t=1Tq(xt∣xt−1))=log(p(xT)1)+log(∏t=1Tpθ(xt−1∣xt)∏t=1Tq(xt∣xt−1))=−log(p(xT))+log(∏t=1Tpθ(xt−1∣xt)∏t=1Tq(xt∣xt−1))=−log(p(xT))+t=1∑Tlog(pθ(xt−1∣xt)q(xt∣xt−1))=−log(p(xT))+t=2∑Tlog(pθ(xt−1∣xt)q(xt∣xt−1))+log(pθ(x0∣x1)q(x1∣x0)) 根据贝叶斯法则重写 sum 项的分子:q(xt∣xt−1)=q(xt−1)q(xt−1∣xt)q(xt)
但这又回到了前面,这些项都是需要估计全部样本导致 high variance,如给出下图所示的 xt,你很难确定上一个状态是什么样的:
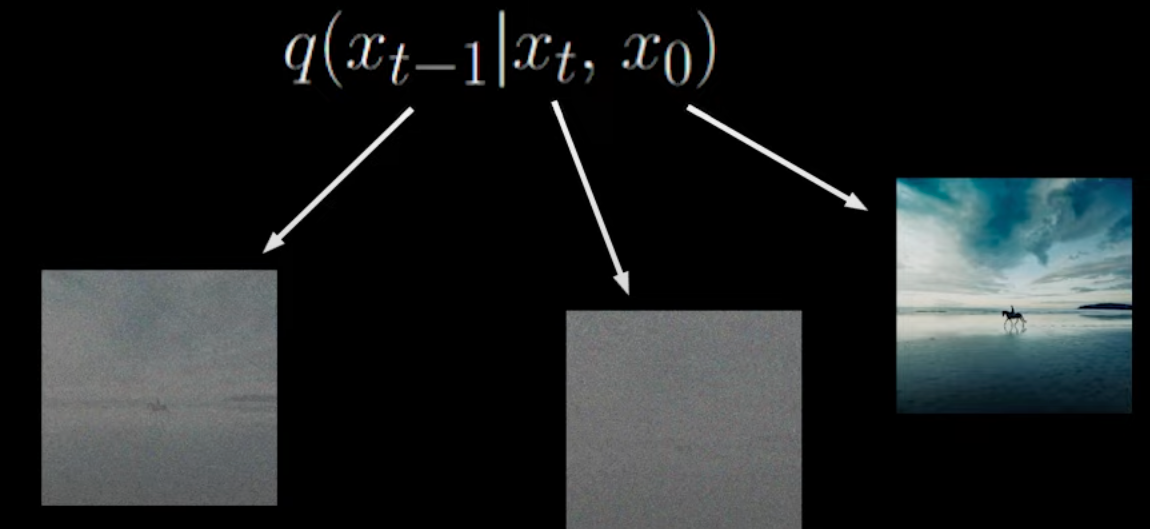
改进思路则为通过直接条件化于原始数据 x0:
⟹q(xt−1∣x0)q(xt−1∣xt,x0)q(xt∣x0) 这样同时给出无噪声的图像,侯选的 xt−1 就少了,方差会减小:
代入回原式:
=−log(p(xT))+t=2∑Tlog(pθ(xt−1∣xt)q(xt−1∣x0)q(xt−1∣xt,x0)q(xt∣x0))+log(pθ(x0∣x1)q(x1∣x0))=−log(p(xT))+t=2∑Tlog(pθ(xt−1∣xt)q(xt−1∣xt,x0))+t=2∑Tlog(q(xt−1∣x0)q(xt∣x0))+log(pθ(x0∣x1)q(x1∣x0)) 展开第二个 sum 项,可以发现大部分项都被化简掉了:

=−log(p(xT))+t=2∑Tlog(pθ(xt−1∣xt)q(xt−1∣xt,x0))+log(q(x1∣x0)q(xT∣x0))+log(pθ(x0∣x1)q(x1∣x0)) 对最后两项应用 log rules 可以化简一些项:
log(q(x1∣x0)q(xT∣x0))+log(pθ(x0∣x1)q(x1∣x0))=[logq(xT∣x0)−logq(x1∣x0)]+[logq(x1∣x0)−logpθ(x0∣x1)]=logq(xT∣x0)−logpθ(x0∣x1) 再将化简后的第一个项移到前面,合并成一个对数得到最终解析形式:
=−log(p(xT))+t=2∑Tlog(pθ(xt−1∣xt)q(xt−1∣xt,x0))+logq(xT∣x0)−logpθ(x0∣x1)=log(p(xT)q(xT∣x0))+t=2∑Tlog(pθ(xt−1∣xt)q(xt−1∣xt,x0))−logpθ(x0∣x1)=DKL(q(xT∣x0)∥p(xT))+t=2∑TDKL(q(xt−1∣xt,x0)∥pθ(xt−1∣xt))−log(pθ(x0∣x1))=t=2∑TDKL(q(xt−1∣xt,x0)∥pθ(xt−1∣xt))−log(pθ(x0∣x1)) 这个形式的第一个项是可以忽略的,因为 q 没有可学习参数,只是加噪声的正向过程,会收敛为正态分布,而 p(xT) 只是从高斯分布中随机采样的噪声,因此可以确定该项 KL 散度会很小。
剩余两项的推导结果如下(过程省略,详见 Lilian’s Blog) 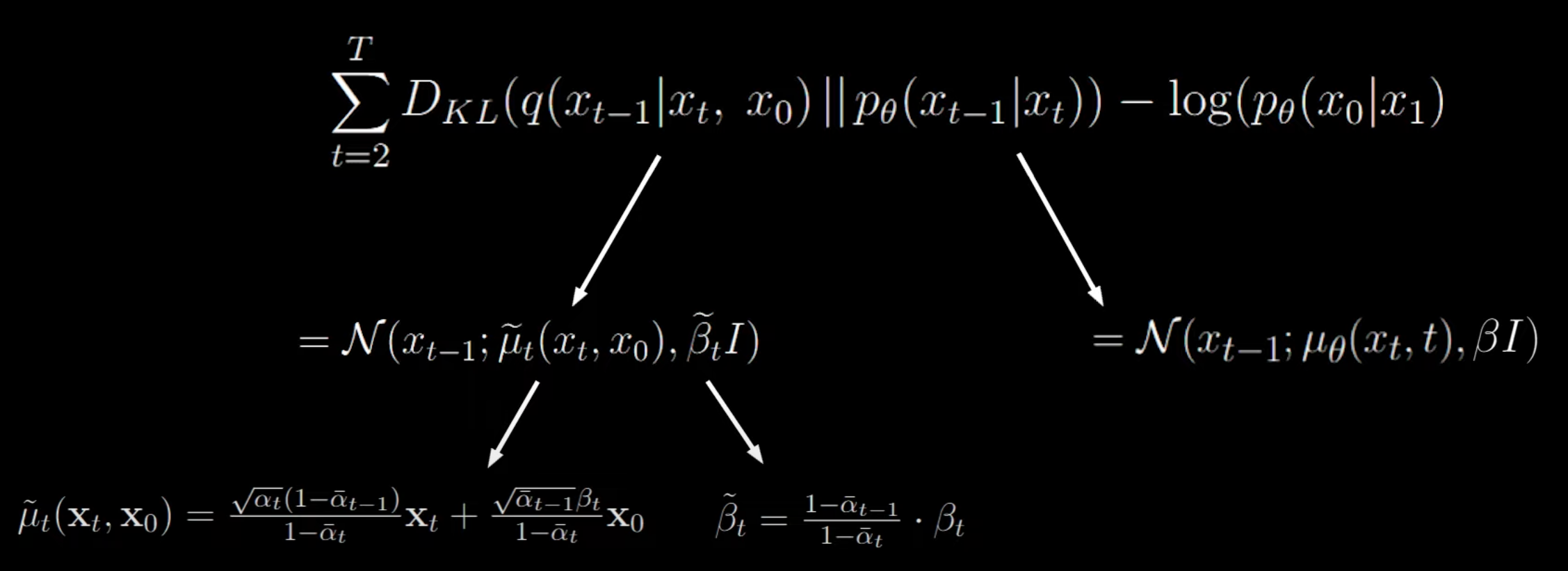
β 是固定的,那么就关注 μ 的形式:
μ~t(xt,x0)=1−αˉtαˉt(1−αˉt−1)xt+1−αˉtαˉt−1βtx0 正向过程生成的闭合形式 xt=αˉtx0+1−αˉtϵ 可以重写为 x0 形式:
x0=αˉt1(xt−1−αˉtϵ) 将上述 x0 的表达式代入预测均值公式 μ~t:
μ~t=1−αˉtαˉt(1−αˉt−1)xt+1−αˉtαˉt−1βt⋅αˉt1(xt−1−αˉtϵ) 现在 μ 不再依赖 x0。继续化简,首先展开第二项:
1−αˉtαˉt−1βt⋅αˉt1(xt−1−αˉtϵ)=αˉt(1−αˉt)αˉt−1βtxt−αˉt(1−αˉt)αˉt−1βt1−αˉtϵ 将 xt 项进行合并:
μ~t=(1−αˉtαˉt(1−αˉt−1)+αˉt(1−αˉt)αˉt−1βt)xt−αˉt(1−αˉt)αˉt−1βt1−αˉtϵ 对 xt 的系数进行进一步合并和化简,最终得到:
μ~t=αˉt1(xt−1−αˉtβtϵ) 这表示我们基本上只是减去 xt 生成的随机缩放噪声,这就是神经网络要预测的东西。
代入后的损失函数 Lt 定义为一个均方误差:
Lt=2σt21αˉt1(xt−1−αˉtβtϵ)−μθ(xt,t)2=2σt21αˉt1(xt−1−αˉtβtϵ)−αˉt1(xt−1−αˉtβtϵθ(xt,t))2=2σt21αˉt(1−αˉt)βt(ϵ−ϵθ(xt,t))2=2σt2αˉt(1−αˉt)βt2∥ϵ−ϵθ(xt,t)∥2 最后的形式就是时间步 t 的实际噪声和神经网络预测噪声之间的均方误差。研究人员发现忽略前面的缩放项会得到更好的采样质量并且更容易实现。
2σt2αt(1−α^t)βt2∥ϵ−ϵθ(xt,t)∥2⟶∥ϵ−ϵθ(xt,t)∥2 回到原始公式
N(xt−1;αt1(xt−1−αˉtβtϵθ(xt,t)),βt) 作者决定在最后一步的采样中,不再添加额外的随机噪声使生成过程更加稳定:
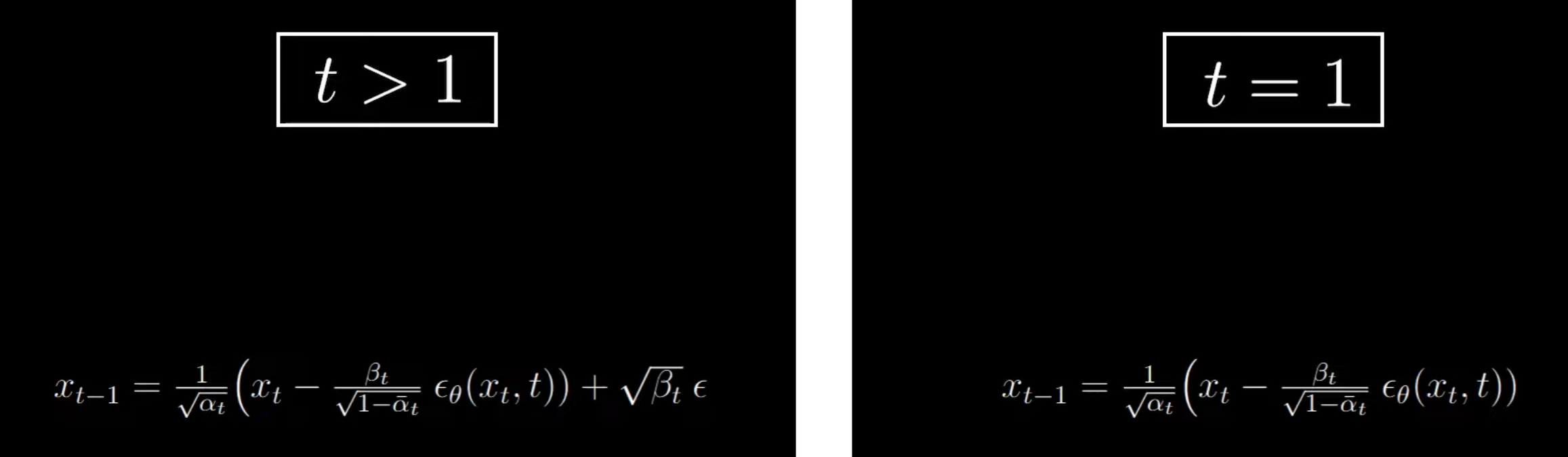
最后的形式为:
Lsimple=Et,x0,ϵ[ϵ−ϵθ(αˉtx0+1−αˉtϵ,t)2]⟹Et,x0,ϵ[∥ϵ−ϵθ(xt,t)∥2] - Et,x0,ϵ 表示对时间步 t、原始数据 x0 和噪声 ϵ 取期望
- ϵ 是实际添加的随机噪声
- ϵθ 是神经网络预测的噪声
- αˉtx0+1−αˉtϵ 是前向过程的闭式解,表示在时间步 t 的噪声数据,因此可以简化为:
- xt 直接表示时间步 t 的噪声数据,即 αˉtx0+1−αˉtϵ
- 整个损失函数本质上是在衡量预测噪声与实际噪声之间的均方误差
其中,时间步 t 通常是从均匀分布中采样的(即 t∼Uniform(1,T),T 是总的时间步数)。这种选择确保了在训练过程中,每个时间步都有相同的概率被选择,从而使模型在所有时间步上都能有效地学习去噪过程。

首先我们从数据集中采样一些图像,然后采样 t 和来自正态分布的噪声,然后通过梯度下降优化目标
首先从正态分布中采样 xt,然后用前面展示过的公式通过重参数化来采样 xt−1。

注意这里 t=1 时是不增加噪声的,根据公式
x0=αt1(x1−1−αˉtβtϵθ(x1,1)) 在 t=1 时,公式用于从 x1 恢复到 x0,这是去噪过程的最后一步。此时,我们希望尽可能准确地重建原始图像。在最后一步不添加噪声(即没有 βtϵ 项),可以避免在生成最终图像时引入不必要的随机性,从而保持图像的清晰度和细节。
推荐 知乎 Sunrise 的 MLP 简化实现 后面有时间的话考虑做一下 Stable Diffusion 的代码手撕,挖个坑…









