
在 B 站偶然刷到清华大学主办的大模型与人工智能系统训练营,果断报名参加。计划利用春节返乡时间通过实践巩固 LLM Inference 的理论知识,恰逢学校 VPN 故障无法科研,正好整理学习笔记。
用 Rust 实现简单 LLM 推理
在 B 站偶然刷到清华大学主办的大模型与人工智能系统训练营,果断报名参加。计划利用春节返乡时间通过实践巩固 LLM Inference 的理论知识,恰逢学校 VPN 故障无法科研,正好整理学习笔记。
关于 Rust 语言,大三时曾两度尝试入门(某圣经教材劝退警告),这次改变策略采用rustlings+官方文档双轨学习,终于突破入门难关(但也仅限于次)。
Llama 架构解析
从核心组件拆解开始,重温经典架构设计:

层归一化(RMS Norm)
Llama 采用 Pre-Norm 架构,即在每层输入前执行归一化操作。相较于传统 Layer Norm:
RMSNorm 通过移除均值中心化实现计算优化:
其中为可学习缩放参数 gamma, 防止除零错误。
注:所有算子初步仅需实现 FP32 支持,后面可以用 generics 和 macro 来支持其它格式推理。
pub fn rms_norm(y: &mut Tensor<f32>, x: &Tensor<f32>, w: &Tensor<f32>, epsilon: f32) {
let shape = x.shape();
assert!(shape == y.shape());
let feature_dim = shape[shape.len() - 1]; // d in mathematical notation
// Calculate number of feature vectors to process
let num_features = shape[0..shape.len()-1].iter().product();
let _y = unsafe { y.data_mut() };
let _x = x.data();
let _w = w.data();
// Process each feature vector independently
for i in 0..num_features {
let offset = i * feature_dim;
// 1. Calculate Σ(x_i²)
let sum_squares: f32 = (0..feature_dim)
.map(|j| {
let x_ij = _x[offset + j];
x_ij * x_ij
})
.sum();
// 2. Calculate RMS(x) = sqrt(1/d * Σ(x_i²) + ε)
let rms = f32::sqrt(sum_squares / feature_dim as f32 + epsilon);
// 3. Apply normalization and scaling: y_i = (w_i * x_i) / RMS(x)
for j in 0..feature_dim {
let idx = offset + j;
_y[idx] = (_w[j] * _x[idx]) / rms;
}
}
}旋转位置编码 RoPE
- 绝对位置编码:如通过影响 max_length 的可学嵌入向量或三角函数构建,直接加到词向量中,每个位置编码基本上是相互独立的;
- 相对位置编码:学习一对 token 之间的距离,需要修改注意力计算(如 T5 模型用 bias 嵌入矩阵表示相对距离,加到 self-attention 的 Q、K 矩阵中),可以拓展到任意长度的序列,推理速度较慢,难利用 KV-Cache;
- Rotary Positional Embedding(RoPE)兼具有绝对位置编码和相对位置编码的优点,二维情况的公式如下:
在旋转矩阵作用前,会先应用线性变换来获得 Query & Key 来保持旋转不变性。然后经过旋转矩阵,其作用是将词向量旋转 度(为是该 token 在句子中的绝对位置):
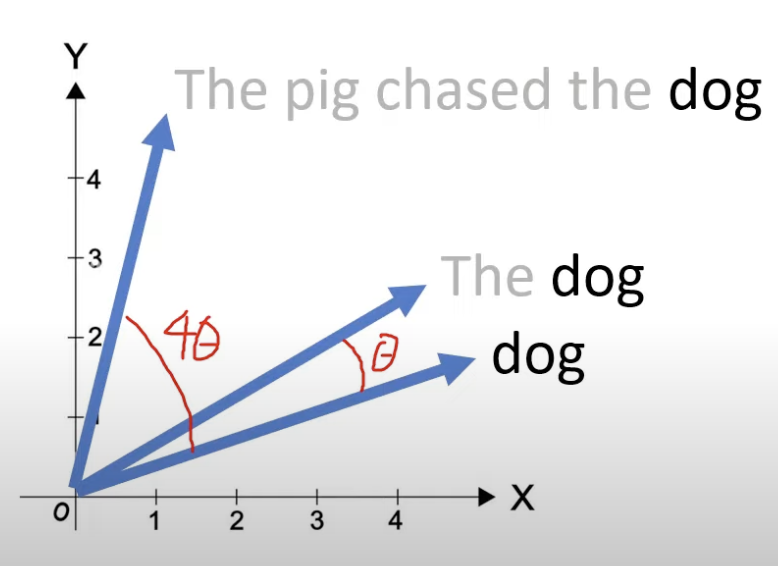
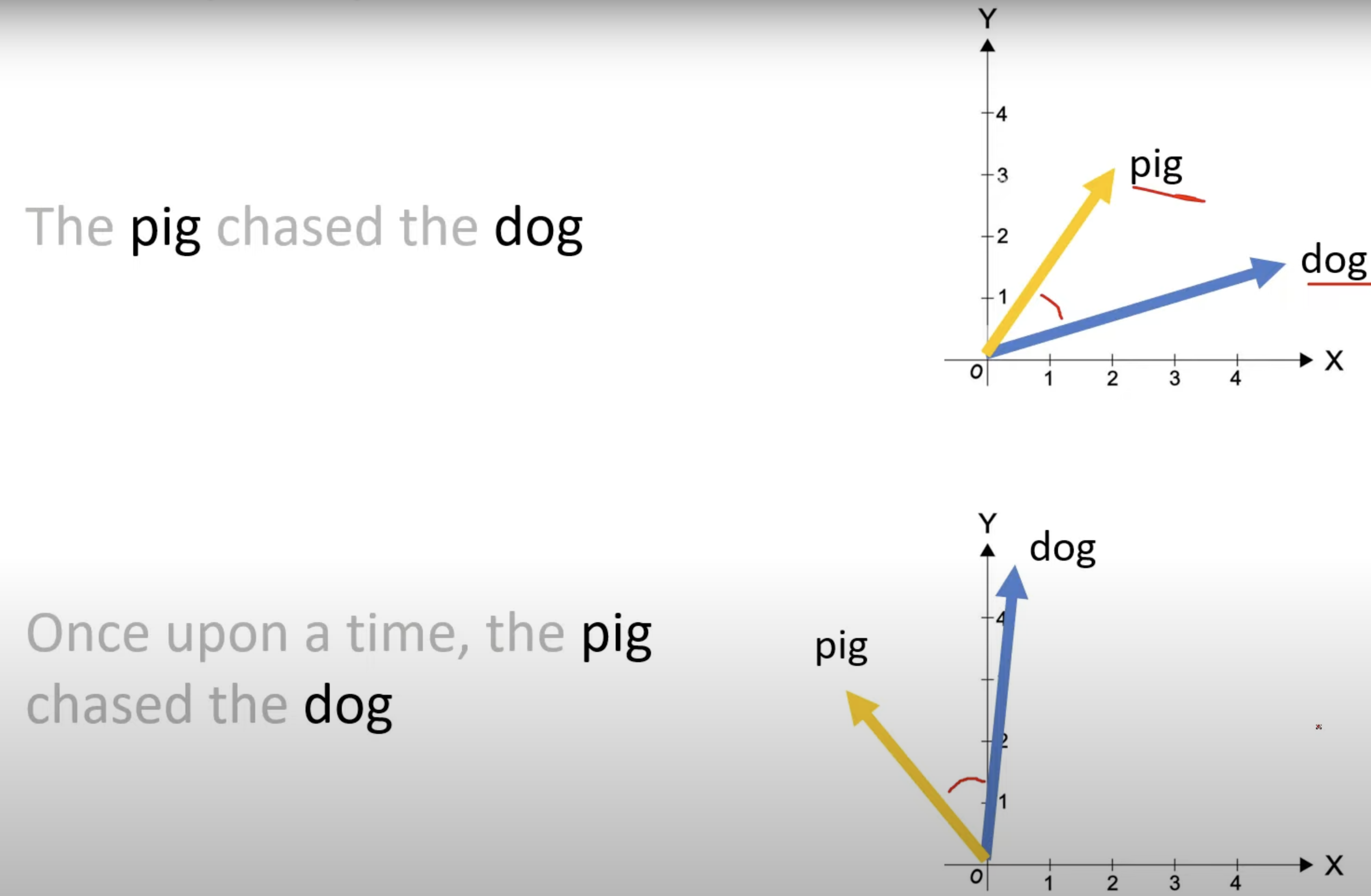
更一般的形式如下,即将向量分割成多组 2D 的块(默认向量维度是偶数),然后分组对每对维度应用不同旋转角度:
优化计算效率,上述计算等价于:

这里的实现是仓库中已经给出的:
// RoPE: Rotary Positional Embedding
pub fn rope(y: &mut Tensor<f32>, start_pos: usize, theta: f32) {
let shape = y.shape();
assert!(shape.len() == 3);
let seq_len = shape[0];
let n_heads = shape[1];
let d = shape[2];
let data = unsafe { y.data_mut() };
for tok in 0..seq_len {
let pos = start_pos + tok;
for head in 0..n_heads {
// 遍历维度对
for i in 0..d / 2 {
let a = data[tok * n_heads * d + head * d + i];
let b = data[tok * n_heads * d + head * d + i + d / 2];
let freq = pos as f32 / theta.powf((i * 2) as f32 / d as f32);
let (sin, cos) = freq.sin_cos();
// 应用旋转矩阵
data[tok * n_heads * d + head * d + i] = a * cos - b * sin;
data[tok * n_heads * d + head * d + i + d / 2] = b * cos + a * sin;
}
}
}
}FFN(MLP)
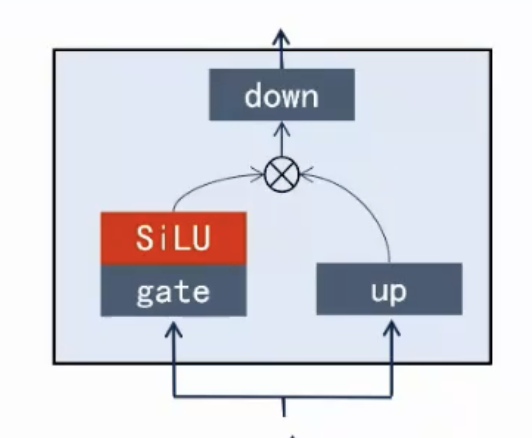
MLP 结构(src/model.rs):
fn mlp(
residual: &mut Tensor<f32>,
hidden_states: &mut Tensor<f32>,
gate: &mut Tensor<f32>,
up: &mut Tensor<f32>,
w_up: &Tensor<f32>,
w_down: &Tensor<f32>,
w_gate: &Tensor<f32>,
rms_w: &Tensor<f32>,
eps: f32,
) {
// 1. hidden = rms_norm(residual)
OP::rms_norm(hidden_states, residual, rms_w, eps);
// 2. gate = hidden @ gate_weight.T
OP::matmul_transb(gate, 0., hidden_states, w_gate, 1.0);
// 3. up = hidden @ up_weight.T
OP::matmul_transb(up, 0., hidden_states, w_up, 1.0);
// 4. act = gate * sigmoid(gate) * up (SwiGLU)
OP::swiglu(up, gate);
// 5. residual = residual + up @ down_weight.T
OP::matmul_transb(residual, 1.0, up, w_down, 1.0);
}算子
整个流程中涉及的基本计算操作如图:

MatMul (scr/operators.rs):
// C = beta * C + alpha * A @ B^T
// hint: You don't need to do an explicit transpose of B
pub fn matmul_transb(c: &mut Tensor<f32>, beta: f32, a: &Tensor<f32>, b: &Tensor<f32>, alpha: f32) {
// C_xy = beta * C_xy + alpha * Σ(A_xk * B_yk) k=1..inner_dim
let shape_a = a.shape();
let shape_b = b.shape();
let (a_rows, b_rows) = (shape_a[0], shape_b[0]);
let inner = shape_a[1];
let _c = unsafe { c.data_mut() };
let _a = a.data();
let _b = b.data();
// 1. using slice to scale C
_c.iter_mut().for_each(|val| *val *= beta);
// 2. using slice to matmul
for x in 0..a_rows {
// get current row of A
let a_row = &_a[x * inner..(x + 1) * inner];
for y in 0..b_rows {
// get current row of B (equivalent to column of B^T)
let b_row = &_b[y * inner..(y + 1) * inner];
let sum: f32 = a_row.iter()
.zip(b_row.iter())
.map(|(&a, &b)| a * b)
.sum();
_c[x * b_rows + y] += alpha * sum;
}
}
}SwiGLU (scr/operators.rs)
,其中
// hint: this is an element-wise operation
pub fn swiglu(y: &mut Tensor<f32>, x: &Tensor<f32>) {
let len = y.size();
assert!(len == x.size());
let _y = unsafe { y.data_mut() };
let _x = x.data();
for i in 0..len {
_y[i] = _y[i] * _x[i] / (1. + f32::exp(-_x[i]));
}
}从 safetensor 中读取
(src/params.rs)
use crate::config::LlamaConfigJson;
use crate::tensor::Tensor;
use num_traits::Num;
use safetensors::SafeTensors;
pub struct LLamaParams<T: Num> {
// token_id to embedding lookup table
pub embedding_table: Tensor<T>, // (vocab_size, dim)
// decoder layer
pub rms_att_w: Vec<Tensor<T>>, // (hidden_size, ) x layers
pub wq: Vec<Tensor<T>>, // (n_heads * head_size, hidden_size) x layers
pub wk: Vec<Tensor<T>>, // (n_kv_heads * head_size, hidden_size) x layers
pub wv: Vec<Tensor<T>>, // (n_kv_heads * head_size, hidden_size) x layers
pub wo: Vec<Tensor<T>>, // (hidden_size, n_heads * head_size) x layers
// ffn layer
pub rms_ffn_w: Vec<Tensor<T>>, // (hidden_size, ) x layers
pub w_up: Vec<Tensor<T>>, // (intermediate_size, hidden_size) x layers
pub w_gate: Vec<Tensor<T>>, // (intermediate_size, hidden_size) x layers
pub w_down: Vec<Tensor<T>>, // (hidden_size, intermediate_size) x layers
// output
pub rms_out_w: Tensor<T>, // (hidden_size, )
pub lm_head: Tensor<T>, // (vocab_size, dim)
}
trait GetTensorFromSafeTensors<P: Num> {
fn get_tensor_from(tensors: &SafeTensors, name: &str) -> Result<Tensor<P>, &'static str>;
}
impl GetTensorFromSafeTensors<f32> for f32 {
fn get_tensor_from(tensors: &SafeTensors, name: &str) -> Result<Tensor<f32>, &'static str> {
let tensor_view = tensors.tensor(name).map_err(|e| {
assert!(matches!(e, safetensors::SafeTensorError::TensorNotFound(_)));
"Tensor not found"
})?;
let data = match tensor_view.dtype() {
safetensors::Dtype::F32 => tensor_view.data()
.chunks_exact(4)
.map(|b| f32::from_le_bytes([b[0], b[1], b[2], b[3]]))
.collect(),
_ => return Err("Unsupported data type"),
};
Ok(Tensor::new(data, &tensor_view.shape().to_vec()))
}
}
macro_rules! get_tensor_vec {
($tensors:expr, $pattern:literal, $layers:expr) => {{
(0..$layers)
.map(|i| {
let name = format!($pattern, i);
f32::get_tensor_from($tensors, &name).unwrap()
})
.collect::<Vec<_>>()
}};
}
impl LLamaParams<f32> {
pub fn from_safetensors(safetensor: &SafeTensors, config: &LlamaConfigJson) -> Self {
let embedding_table = if config.tie_word_embeddings {
f32::get_tensor_from(safetensor, "lm_head.weight").unwrap()
} else {
f32::get_tensor_from(safetensor, "model.embed_tokens.weight").unwrap()
};
let n_layers = config.num_hidden_layers;
Self {
embedding_table,
rms_att_w: get_tensor_vec!(safetensor, "model.layers.{}.input_layernorm.weight", n_layers),
wq: get_tensor_vec!(safetensor, "model.layers.{}.self_attn.q_proj.weight", n_layers),
wk: get_tensor_vec!(safetensor, "model.layers.{}.self_attn.k_proj.weight", n_layers),
wv: get_tensor_vec!(safetensor, "model.layers.{}.self_attn.v_proj.weight", n_layers),
wo: get_tensor_vec!(safetensor, "model.layers.{}.self_attn.o_proj.weight", n_layers),
rms_ffn_w: get_tensor_vec!(safetensor, "model.layers.{}.post_attention_layernorm.weight", n_layers),
w_up: get_tensor_vec!(safetensor, "model.layers.{}.mlp.up_proj.weight", n_layers),
w_gate: get_tensor_vec!(safetensor, "model.layers.{}.mlp.gate_proj.weight", n_layers),
w_down: get_tensor_vec!(safetensor, "model.layers.{}.mlp.down_proj.weight", n_layers),
rms_out_w: f32::get_tensor_from(safetensor, "model.norm.weight").unwrap(),
lm_head: f32::get_tensor_from(safetensor, "lm_head.weight").unwrap(),
}
}
}KV-Cache 机制
fp16(参数占 2 字节) 推理时 KV 缓存占用计算:
随着序列长度增加,性能呈指数级下降(注意最新 token 生成的增量计算):

对应参数use_cache: true与max_position_embeddings: 4096,后者决定模型的最大上下文窗口。
推理优化方案
分组查询注意力(GQA)
通过多组 Q 共享单组 KV 实现内存优化(需满足头数整除关系):
Batching 技术、会话管理、对话回滚等暂时没有精力实现,后面仅作科普总结。
混合精度推理
常用的有 FP16、BF16,前者精度和 TF32 一样,后者表示范围和 FP32 一样,精度则低一些,TF32 兼具 FP32 的表示范围和 FP16 的精度,不过需要有 tensor core 硬件支持。

注意,下面的精度敏感操作需保留 FP32:
- RoPE 的三角函数计算
- RMS Norm 的指数运算
- Softmax 数值稳定性
量化推理
通过数据类型映射实现:
- 计算加速(需要硬件支持低精度指令)
- 显存优化(fp16 仅需 fp32 的 50% 空间,甚至是 int8、int4…)

进阶优化方向
- MoE 架构:动态路由的 MLP 优化
- 分布式推理:
- 数据并行:参数全拷贝,提升吞吐
- 流水线并行:层间切分,通信开销敏感
- 张量并行:参数分布式存储,需 AllGather/AllReduce 同步

总结
本次训练营以硬核实践打通 LLM 推理优化的技术脉络,很值得后面有时间的时候继续推进实现,最近事情超多,这里就先草草收个尾 🥲