本文主要基于 Umar Jamil 的课程进行学习和记录。我们的目标是让 LLM 的行为与我们的期望的输出相一致,RLHF 则是最著名的技术之一。
从 RL 来,到 RLHF 去
本文主要基于 Umar Jamil 的课程进行学习和记录。我们的目标是让 LLM 的行为与我们的期望的输出相一致,RLHF 则是最著名的技术之一。其标准流程涉及四个模型(听上去就很占显存,所以很多方法是去掉部分模型),这里只需记得一共需要四个即可:Reward、Actor、Critic 和 Reference Model,我们最后优化得到的模型是这里说的 Actor Model。
LLM to RL
以前对 RL 的认识中,策略是告诉你在当前 State 下把你应该采取的 Action 的概率的东西,那这么说来,语言模型本身就可以看作一个 Policy:接收一个 Prompt (state),输出下一个 token (action) 的概率,采样后得到一个新 state(token 被拼到 prompt 后),即相当于一个有 vocab_size 大小 Action Space 的 Policy,也是一个 RL Agent。
那这么说,还差一个提供 Reward 的东西(传统 RL 中一般是环境内置的奖励函数)
做一个“Q-A-Reward”的数据集可以实现这点,但是人类并不擅长寻找共识,但在比较优劣这点却很擅长。所以我们把方向转为:模型在 High Temperature 下 generate 多个 A,然后请领域专家(可以是人也可以是 AI Model)来选择出 Chosen / Prefer 的答案,标注出一个偏好数据集,用此训练出一个生成数值奖励的 Reward Model。
Reward Model
这个 RM 是用一个预训练 LLM 如 Llama 来实现的。
[!note] 在文本生成任务中,我们取 prompt 输入 Transformer 后产生的 Embedding (Hidden States) 的最后一个 (token 的) Hidden State 送入 Linear 投影到词表中得到 logits,然后用 Softmax 和采样策略来选择 next token。
当我们不想生成文本而是生成数值奖励时,可以投影到词汇表中的 Linear 替换为一个 one output feature (输出一个标量) 的 Linear,用来产生整个文本序列的单一评分值。

Reward Model Loss
[!tip] 训练时,我们要让这个模型为选择的答案生成高奖励,为未被选择的答案生成低奖励
类似 Bradley-Terry 的参数化形式:
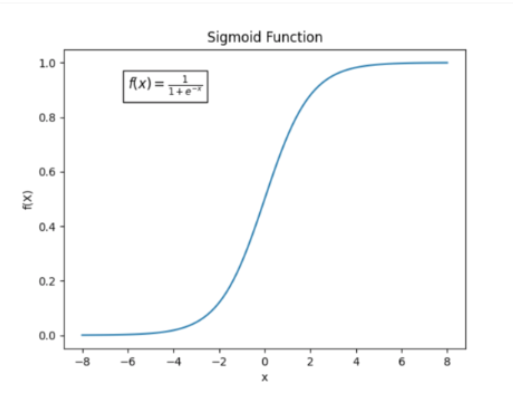
$$ Loss = -\log \sigma(r(x, y_w) - r(x, y_l)) $$
表示 Chosen, 反之。因此当模型为 chosen 给出高 reward 时,
这样损失会低,而模型为选择的答案给出低 reward 时损失会很高
HuggingFace 中 RewardTrainer 类接收一个 AutoModelForSequenceClassification 输入(即我们上面提到的模型结构)

Actor & Critic Model
Trajectories
如前所述,强化学习(RL)的核心目标是找到一个策略(policy, ),该策略能指导 agent 的行动,以获得最大可能的期望回报(expected return)。
数学上,我们将其表示为找到最大化目标函数 的最优策略 :
期望回报 代表了智能体遵循策略 时,在许多可能的生命周期或回合(episodes)中,预期能累积到的平均总回报。
它的计算方法是:考虑所有可能发生的轨迹(trajectory, ),并将每个轨迹的总回报 乘以该轨迹在策略 下发生的概率 进行加权平均(或积分)。
- 表示当轨迹 是根据策略 生成时的期望值(Expected Value)。
- 是在单个轨迹 上获得的总回报(奖励)。
- 是当智能体使用策略 时,特定轨迹 发生的概率。
轨迹 就是 agent 经历的一系列状态和动作的序列,从初始状态开始。它是 agent 与环境交互的一种可能的“故事”或“路径”。
- :时间步 的状态(State)。
- :在时间步 采取的动作(Action)(通常基于状态 和策略 )。
我们通常将环境建模为随机的(stochastic)。这意味着在同一个状态 下执行相同的动作 ,并不总会导致完全相同的下一个状态 。其中涉及到随机性。
下一个状态 是从一个以当前状态 和采取的动作 为条件的概率分布中抽取的:
考虑到随机性的状态转移和 Agent 的策略,我们可以计算整个轨迹发生的概率。它由以下各项连乘得到:
- Agent 在初始状态 的概率:。
- 对于轨迹中的每一个时间步 :
- 环境在给定 和 的条件下转移到状态 的概率:。
- 智能体根据其策略在状态 选择动作 的概率:。
(其中 是轨迹的长度)。
在计算轨迹的总回报 时,我们几乎总是使用折扣回报(discounted rewards)。这意味着较早收到的回报比较晚收到的回报更有价值。
为什么?
- 反映了现实场景(今天到手的一美元比明天画饼的一美元更有价值)。
- 在持续性任务(没有固定终点的任务)中避免了无限回报的问题。
- 提供了数学上的便利性。
我们引入一个折扣因子(discount factor),其中 。 越接近 0,Agent 越“短视”(更关注眼前利益); 越接近 1,Agent 越“有远见”(更关注长期回报)。
轨迹的总折扣回报计算如下:
- 是在时间步 收到的即时回报(immediate reward)。
- 是应用于时间步 回报的折扣系数。
那在 LLM 中,轨迹是什么呢?前面提到了,模型是策略,prompt 是状态,next token 是 action,因此自回归生成中的这些 s, a 序列组成了轨迹。

Policy Gradient
我们确定了强化学习的目标:找到一个最优策略 来最大化期望回报 。很好。但我们实际上如何表示并找到这个策略呢?
通常,尤其是在处理复杂问题时,我们不会去搜索所有可能的策略。我们会定义一个参数化策略(parameterized policy),记作 。你可以把 想象成一组“旋钮”或参数——如果我们的策略是一个神经网络,那 可能就是网络的权重和偏置。
我们现在的目标就变成了:如何调整这些旋钮 来最大化我们的期望回报?
[!note] 在参数为 的策略 下,所有可能轨迹的期望回报:
这意味着期望回报依赖于轨迹 ,而轨迹的分布又依赖于我们特定策略 所选择的动作。改变 ,就改变了策略,改变了轨迹,也就改变了期望回报。
[!note] 我们想通过改变 来最大化 。在深度学习中一般使用梯度下降(gradient descent)来最小化一个损失函数。而在这里,我们想要最大化一个函数。所以,我们反过来使用梯度上升(gradient ascent)!这就像爬山——想找到最陡峭的上升方向(也就是梯度),然后朝着那个方向迈出一步。
我们的策略 是一个神经网络,我们会迭代地调整其参数 来增加 。这个更新规则看起来会非常熟悉(只是把梯度下降里的减号换成了加号):
- :我们在第 次迭代时的参数。
- :学习率(步长大小)。
- :期望回报 相对于参数 的梯度(gradient),在当前参数 处计算。它告诉我们在参数空间中哪个方向能最大程度地增加 。

[!important] PG 推导 这里一开始会啰嗦一点来把角标重新都介绍一遍,ADHD 友好型推导…
第一步,重申我们要求梯度的对象是期望回报 :
$ \nabla{\theta} J(\pi{\theta}) = \nabla{\theta} E{\tau \sim \pi_{\theta}} [R(\tau)] $
这里:
- 就是期望回报。
- 表示期望值,这个期望是针对所有可能的轨迹 (trajectory, ) 来计算的。轨迹 是 Agent 与环境交互产生的一系列状态和动作 。
- 表示这些轨迹是根据我们当前的策略 生成的。
- 是指一条完整轨迹 所获得的总回报(通常是折扣回报)。
- 是梯度算子,表示我们要对参数 求偏导数。
第二步,我们来展开期望的表达式: 期望值的定义是什么?对于一个随机变量 ,它的期望 可以通过它的概率分布 来计算:
- 如果是连续变量:
- 如果是离散变量:
在我们的例子里,随机变量是轨迹的回报 ,概率分布是轨迹发生的概率 (给定策略 下轨迹 发生的概率)。所以,期望可以写成积分(或求和)的形式:
$ E{\tau \sim \pi{\theta}} [R(\tau)] = \int P(\tau|\pi_{\theta}) R(\tau) d\tau $
(这里用积分符号 代表对所有可能的轨迹求和或积分,更通用)。 把这个代入第一步的公式:
$ \nabla{\theta} J(\pi{\theta}) = \nabla{\theta} \int P(\tau|\pi{\theta}) R(\tau) d\tau $
第三步:把梯度算子移到积分号里面
$ \nabla{\theta} \int P(\tau|\pi{\theta}) R(\tau) d\tau = \int \nabla{\theta} [P(\tau|\pi{\theta}) R(\tau)] d\tau $
这里需要一点微积分知识:在满足一定条件下(通常我们假设在强化学习中是满足的),我们可以交换求导和积分的顺序。就像 一样。 接着,注意到 是一条轨迹确定后的总回报,它本身的值不直接依赖于策略参数 。(是策略 影响了哪条轨迹会发生,而不是这条轨迹一旦发生后它的回报值是多少)。所以,梯度 只需要作用在 上:
$ = \int [\nabla{\theta} P(\tau|\pi{\theta})] R(\tau) d\tau $
这一步告诉我们,期望回报的变化,是由于参数 改变导致每条轨迹发生的概率 变化,再乘以该轨迹本身的回报 ,然后对所有轨迹累加起来的效果。
第四步:对数导数技巧 (Log-derivative trick) 这是整个推导中最核心、最巧妙的一步!我们需要引入一个恒等式。
- 高数复习 (链式法则与对数求导): 回忆一下自然对数 (通常指 ) 的导数是 。
- 稍微变形一下,我们就得到:。 现在,我们把这个技巧应用到梯度上。令 对应 ,自变量 对应参数 。那么:
把这个结果代入第三步的积分中:
第五步:重新变回期望形式 观察第四步的结果:
这又符合期望的定义了! 。 这里, 就对应方括号里的全部内容 。 所以,整个积分可以写回期望的形式:
重大意义! 我们成功地把期望的梯度 转换成了某个量(梯度乘以回报)的期望 。这个形式非常重要,因为它可以通过采样来近似!我们不需要真的去计算所有轨迹的积分了。只需要采样很多轨迹 ,对于每一条轨迹,计算括号里的值 ,然后求平均,就可以得到梯度的近似值!
第六步:展开对数概率的梯度 (Expression for grad-log-prob) 现在,我们需要处理一下期望里面的 这一项。 回忆一下轨迹 (假设轨迹长度为 T+1 个状态和 T+1 个动作,或者 T 个时间步)。一条轨迹发生的概率是:
:初始状态 的概率。
:环境动力学 (Environment Dynamics),在状态 执行动作 后转移到状态 的概率。
:策略,在状态 选择动作 的概率(这部分依赖于 )。
数学复习 (对数性质): 并且 。 对 取对数:
现在对上式关于 求梯度 :
数学复习 (梯度性质): 梯度的加法法则 。梯度 只对依赖于 的项有作用。
关键点:
- 初始状态概率 通常不依赖于策略参数 ,所以 。
- 环境动力学 描述的是环境本身的性质,也不依赖于策略参数 ,所以 。
- 只有策略 依赖于 。 所以,上式简化为:
整条轨迹的对数概率的梯度,等于这条轨迹中每一步动作的对数概率梯度之和!这大大简化了计算。
第七步:最终的策略梯度定理 把第六步简化后的结果代回到第五步的期望公式中:
$\nabla{\theta} J(\pi{\theta}) = E{\tau \sim \pi{\theta}} [(\sum{t=0}^{T} \nabla{\theta} \log \pi_{\theta}(a_t|s_t)) R(\tau)] $
这就是策略梯度定理 (Policy Gradient Theorem) 的最终形式(或者说其中一种常见形式)。 期望回报 对参数 的梯度,等于“采样一条轨迹 ,计算该轨迹的总回报 ,再乘以这条轨迹中所有 (状态,动作) 对对应的策略对数概率梯度 之和”,然后对所有可能的轨迹求期望(平均)。
显然得到所有轨迹的成本是极高的,例如我们要采样出 max_token_length=100 的所有生成结果,因此我们可以用样本均值来近似期望:
[!note] 蒙特卡洛近似:* 运行当前策略 ,收集 条轨迹,组成数据集 (记 )。
- 用这些样本的平均值近似期望值:
应用到 LM Policy 上
通过图中所示的生成流程得到这条采样轨迹中每个 state action pair 的对数概率,现在就可以反向传播来计算梯度,

然后将每个梯度乘以从 RM 中 reward 送入表达式来运行梯度上升优化:

High Variance
PG 算法对于小问题效果较好,但是用于语言建模会有一些问题。
[!note] 中心极限定理告诉我们:只要样本够大,样本均值就会呈正态分布,这让我们能更好地预测和分析数据。当样本量较小时,样本均值的波动会很大;即使均值趋向于正态分布,但单次抽样的结果可能差异很大。而我们又知道从 LM 中采样很多轨迹的成本是很高的,这会导致估计量的高方差问题。
如何在不增加样本量的情况下减少方差呢?
- 移除历史奖励:reward-to-go 首先必须要承认的是,当前的 action 无法影响到过去已经获得的奖励,而过去的奖励增加了不必要的噪声,这和 RL 中的信用分配问题应该有点关系。因此去掉过去的项可以避免增加噪音,让估计的梯度与真实梯度拉近。所以与其从零开始计算轨迹的奖励,我们可以只考虑从当前时间步开始的动作的奖励

- 引入 baseline RL 的研究已证实,引入一个依赖于 state 的项(比如计算轨迹奖励的函数,也可以是一个常数)可以减少方差。这里我们选择 价值函数 .
Value Function
告诉你根据当前策略进行行动,剩余轨迹的期望奖励是多少。
经典 RL 场景和 LM 场景中的价值定义例子:

实际操作中,用的是我们试图优化的那个 LM 做初始化,在其顶部再添加一个线性层来预估 value,这样 Transformer 层的参数可以同时用于语言建模(用将 token 投射到词表的层)和价值估计

前面说的 reward-to-go 在 RL 中被称为 Q 函数,即从当前状态开始采取这个动作,然后得到即时奖励,按照策略完成后续行动的预期奖励:

再通过引入 Value 函数得到 Q 与 V 的差异,这个差异被称为 Advantage 函数

这个 优势项表示这个特定动作,相对于在状态 中可以采取的平均动作好多少

在图中红箭头指向的状态,向下移动的优势函数将高于其它动作的优势函数
梯度乘上优势函数后,效果就变为了让策略增加具有高优势 action 的 logprob,并降低带来低平均回报 action 的 log prob。
[!note] 在传统的强化学习方法中,Q 网络 和 V 网络 通常是独立的。也就是说,Q 函数用于估计在状态 下执行动作 所期望的总回报,而 V 函数 只是估计状态 的值。这样需要两个不同的神经网络来分别计算这两个值。
然而,现在我们引入了优势函数 ,其计算方式是基于 Q 值和 V 值之间的差异,即:
通过将 表达为 和 之间的差异,我们发现,我们只需要训练一个网络来输出 ,再通过奖励 和折扣因子 计算出 Q 值。
因此,只有一个神经网络是需要的,这个网络主要预测 。Q 值通过以下公式计算得出:
优势函数则进一步计算为:
优势采样
短步长的优势估计器偏差大但方差小,长步长的优势估计器偏差小但方差大。这个权衡问题是强化学习中需要仔细选择和调整的部分,取决于模型的稳定性要求和训练效率。
一个例子:“短期记忆的人只记得昨天发生的事,虽然不够全面,但很稳定;长期记忆的人能看清未来几天的全貌,但可能会被更多的未知因素所干扰。” GAE
为了解决这个偏差 - 方差问题,可以使用 GAE(广义优势估计),本质上就是对所有的优势项的加权和,每项乘上一个衰减因子。

[!note] 现在来聊聊 TD 误差 在线学习有一个妙处:你不需要等到最后再更新策略。于是,时序差分误差(TD Error) 就登场了:
这里的关键是:TD 误差实际上是优势函数的在线估计。它告诉你,就在此刻,你的动作是否让未来状态比你预期的要好。这个误差 直接反映了优势的概念:
- 如果 :“嘿,这个动作比我想象中好!”(优势为正)。
- 如果 :“嗯,我本来以为会更好……”(优势为负)。
这让你可以逐步调整你的策略,不用等到一整 episode 结束才做改变。这对提高效率来说,简直是绝佳策略。
GAE 的目的是在策略梯度算法中,提供一个比原始回报 或简单 TD 误差 更好的优势函数 的估计值 ,以降低梯度估计的方差,提高学习的稳定性和效率。
这个公式递归地定义了广义优势估计 。它不是只看一步的 TD 误差 ,而是综合了未来多步的 TD 误差信息。
这个递归式从轨迹(episode)的末尾(假设 是最后一步,)向前计算:
- …
- 一般形式: (假设无限步长或在终止状态后的 为 0)
参数 ()是 GAE 的关键,它控制着估计 的偏差(bias)和方差(variance):
- 当 时:
- 。GAE 退化为简单的单步 TD 误差。这种估计方差较低(因为它只依赖于下一步的信息),但可能偏差较高(因为它严重依赖于可能不准确的 的估计)。
- 当 时:
- 。经过推导可以证明,这等价于 ,也就是蒙特卡洛(Monte Carlo)回报减去基线(baseline)。这种估计偏差较低(因为它使用了从 时刻开始的完整实际回报),但方差通常很高(因为它累积了多个时间步的随机性)。
- 当 时:
- GAE 在上述两种极端情况之间进行插值。 越接近 0,越偏向于低方差高偏差的 TD 估计; 越接近 1,越偏向于高方差低偏差的 MC 估计。
- 通过选择合适的 (例如 0.97),GAE 试图在偏差和方差之间取得一个良好的平衡,从而得到一个既相对准确(偏差可控)又相对稳定(方差较小)的优势估计。
语言模型的 Advantage
如图,目标是提高在当前状态“上海”token 的 logprob,降低“巧克力”的 logprob,因为选择”上海“的优势高于选择“巧克力”(胡乱说的 token)的优势。

重要性采样和离线学习
在很多情况下,我们可能想要计算 ,但是:
- 我们很难或者无法直接从目标分布 中采样得到 。
- 或者从 采样效率很低,语言模型中就是这个问题,LM 采样成本太高了。
但是,我们可能可以很容易地从另一个替代的,或称为提议(Proposal)的分布 中进行采样。
重要性采样 (Importance Sampling, IS) 是一种通过从不同的分布采样来估计目标分布期望的技术,将一个在概率分布 下计算的期望值 ,转换为在另一个不同的概率分布 下计算一个相关函数的期望值 。
这里的关键是引入了重要性权重(importance weight) 。这个权重的作用是修正偏差:对于一个从 中抽到的样本 ,如果它在目标分布 中出现的概率更高(),就会给它一个大于 1 的权重;反之,如果它在 中出现的概率更低(),就会给它一个小于 1 的权重。这样加权平均后,就能得到对原始期望 的一个(通常是无偏或一致的)估计。
重要性采样允许我们:
- 从容易采样的分布 中抽取样本 。
- 通过计算加权平均来估计原始的期望值:
回到我们的场景。前面我们得到了 On-Policy 的策略梯度估计:
[!info] On-Policy 的含义:即采集数据用的策略和训练时用的策略是同一个。由于计算时需要使用从当前策略 采样生成的轨迹。这意味着每次策略更新后,旧数据就不能直接用了,样本效率低。至于 mini_batch_num > 1 时,后面用于更新的数据还算是 On-Policy 吗?严格意义上感觉不算,所以也可以理解为 Semi-On-Policy?(表达不一定严谨)。
而 On-Policy 则是强调当前策略模型能否和环境进行交互。
我们希望利用过去由旧策略 生成的数据(这些数据可能是大量存在的)来估计当前新策略 的梯度。这样可以重复利用数据,提高样本效率。
回忆下重要性采样 IS 的原理: 。 对应到我们的 PG(简化考虑单步决策):
- 目标分布 对应新策略 。
- 采样分布 对应旧策略 。
- 重要性权重为 。
将重要性权重应用到 On-Policy 梯度的每一项(每个时间步 ),得到标准的 Off-Policy 估计:
现在我们找到了可以在不每次从我们正在优化的策略(要训练的模型)中采样的情况下完整梯度上升优化,而是只采样一次,将轨迹保存到内存/数据库中,用 mini-batch 优化策略,然后用新策略初始化离线策略(采样的策略)
PPO Loss
PPO Loss 主要由三个部分组成:策略损失()、价值函数损失()和熵奖励()。
1. 策略损失 ()
Clipped Surrogate Objective (裁剪的替代目标)
这是 PPO 的核心。你会注意到它和我们前面用重要性采样推导出来的 off-policy 策略梯度目标有点像,但有一个关键的改动。
: 这就是重要性采样比率,称之为 。它是在状态 下,根据当前(在线)策略 采取动作 的概率,除以根据收集轨迹数据时使用的旧(离线)策略 采取该动作的概率。这个比率修正了数据来自一个与我们当前试图改进的策略略有不同的策略这一事实。
: 这是优势函数估计值,是使用 GAE 计算出来的,有助于平衡偏差和方差。它告诉我们,在状态 下采取动作 比在该状态下采取平均动作要好多少或差多少(根据当前的价值函数判断)。
clip函数: 这就是 PPO 的关键点所在。 它基本上是说:如果概率比率 偏离 1 太远(过高或过低),我们就把它“裁剪”掉。所以,如果 试图变成 ,而 是 ,它就会被裁剪到 。如果它试图变成 ,它就会被裁剪到 。 参数 (epsilon) 是一个小的超参数(例如 0.1 或 0.2),它定义了裁剪范围 。min函数: 这个目标函数取了下面两项中的较小者:未裁剪的目标:
裁剪后的目标:
为什么要这样做呢? 策略梯度的目标是增加具有正优势的动作的概率,并减少具有负优势的动作的概率。 然而,使用重要性采样时,如果 变得非常大,可能会导致巨大的更新和不稳定性。PPO 通过裁剪这个比率来尝试保持新策略与旧策略的接近。
- 如果 (好动作): 我们希望增加 。
min函数意味着如果 增长超过 ,目标函数就会被限制在 。这可以防止策略在单次更新中变化过大,即使未裁剪的目标会建议一个更大的增幅。 - 如果 (坏动作): 我们希望减少 。如果 缩小到 以下,目标函数就会被限制在 。(注意:当 时, 这一项在 较小时值较大(更接近零或为正),而 也是在 较小时值较大。这里的
min实际上意味着当比率超出裁剪边界时,我们采取的是更悲观的更新步骤,或者说,导致 log 概率变化幅度更小的那一步。) 更准确地说,当 时,乘积 会随着 的增加而变得更负。min操作确保了如果 偏离了 区间,我们不会让目标变得过于负(也就是说,我们不会过分地降低该动作的概率)。
2. 价值函数损失 ()
这和前面的内容完全一样:
- 是价值网络的输出(即 LLM 顶部再加一个线性层,用来预测从状态 开始的期望累积奖励)。
- 这一项(称之为 或目标价值)是从状态 开始,并遵循当前策略直到回合结束所观察到的实际折扣奖励总和。这是我们为 设定的经验目标。
- 这个损失函数就是预测值 和观察到的目标值 之间的均方误差(MSE)。我们希望价值函数能够准确预测未来的奖励。这个价值函数对于计算优势 至关重要。
3. 熵奖励 ()
- 这里的 (或者更准确地说是 ,对于给定状态 下所有可能的动作 )代表了当前策略在给定状态下输出的动作概率分布。
- 这一项是这个概率分布的熵。熵衡量的是分布的随机性或不确定性。均匀分布(非常随机)具有高熵,而尖峰分布(对某个动作非常确定)具有低熵。
- 损失项是负熵。当我们在总损失 中最小化这个 时(假设 是正的),我们实际上是在最大化策略的熵。
鼓励更高的熵可以促进探索,会让策略变得更随机一些,尝试不同的动作(在 LLM 的情况下就是尝试不同的 token),而不是过快地收敛到一个可能是次优的确定性策略。这有助于 Agent 发现更好的策略。
最终形式
最终的 PPO 损失是这三个部分的加权和:
- : 价值函数损失,由 加权。 的一个常见值是 左右。
- : 熵奖励(如果 ,实际上是对低熵的惩罚),由 加权。 通常是一个小的正常数(例如 ),用于鼓励探索,同时又不会压倒主要的策略目标。
Agent 的参数(即 LLM 的权重)通过计算这个组合损失 的梯度并执行梯度下降来进行更新。
Reference Model
Reward Hacking
RL 的一大问题就是 reward-hacking,模型可能会学会总是输出带来好奖励但对人类来说没意义的 token 或序列,比如连续说十遍“谢谢你”来提升礼貌分数,所以我们希望对齐的模型(RL post-training 后)的输出尽量和原本模型的输出较为相近。
因此会有另一个冻结了权重的模型(ref model),我们要优化的模型在每个轨迹的每一步中通过 reward model 生成奖励的时候,这个奖励会减去 ref model 与优化的模型 log prob 之间的 KL 散度,作为惩罚项来防止模型生成与原始模型差异过大的答案,以此防止上面所说的模型作弊现象。

Code walk through
trl
class AutoModelForCausalLMWithValueHead(PreTrainedModelWrapper):
# ... (class attributes like transformers_parent_class) ...这个类的核心目的是将一个标准的因果语言模型(Causal LM)(我们的 Actor Model,负责生成文本的策略 )与一个 Value Head(即 Critic Model,负责估计状态价值 V(s))捆绑在一起。在 PPO / Actor Critic 算法中,我们同时需要策略和价值函数,这个类就提供了一个统一的模型结构来同时输出这两者。
def __init__(self, pretrained_model, **kwargs):
super().__init__(pretrained_model, **kwargs) # 基础设置
v_head_kwargs, _, _ = self._split_kwargs(kwargs) # 分离出给 ValueHead 的参数
# 确保传入的是个有语言模型输出能力的模型
if not any(hasattr(self.pretrained_model, attribute) for attribute in self.lm_head_namings):
raise ValueError("The model does not have a language model head...")
# 创建 ValueHead 实例,它将学习预测状态的价值 V(s)
self.v_head = ValueHead(self.pretrained_model.config, **v_head_kwargs)
# 初始化 ValueHead 的权重
self._init_weights(**v_head_kwargs) # 默认随机初始化,也可以指定正态分布初始化- 充当 Actor: 即我们的语言模型
pretrained_model,它会根据当前 prompt(状态 s)生成回应(动作 a,即一系列 token)。 - Critic: 评估 Actor 在某个状态 s 的“好坏”,即输出 。这就是线性层
self.v_head的任务。
def forward(
self,
input_ids=None, # 输入的 token IDs (状态 s)
attention_mask=None,
past_key_values=None, # 用于加速生成
**kwargs,
):
# 强制底层模型输出 hidden_states,ValueHead 需要它们作为输入
kwargs["output_hidden_states"] = True
# ... (处理 past_key_values 和 PEFT 的一些细节,PPO 核心理解中可先忽略)
# 1. Actor (基础语言模型) 进行计算
base_model_output = self.pretrained_model(
input_ids=input_ids,
attention_mask=attention_mask,
**kwargs,
)
# 2. 提取 Actor 的输出 (用于策略更新) 和 Critic 的输入
lm_logits = base_model_output.logits # Actor 的输出:预测下一个 token 的概率分布
# 这是计算 PPO 中 L_POLICY 和 L_ENTROPY 的基础
last_hidden_state = base_model_output.hidden_states[-1] # Critic 的输入:LM 最后一层的隐藏状态,
# 代表了当前状态 s 的表征
# (可选) 语言模型本身的损失,在 RL 阶段通常不直接用
loss = base_model_output.loss
# (确保数据和模型在同一设备)
if last_hidden_state.device != self.v_head.summary.weight.device:
last_hidden_state = last_hidden_state.to(self.v_head.summary.weight.device)
# 3. Critic (ValueHead) 进行计算
# ValueHead 接收状态表征,输出对该状态的价值估计 V(s)
value = self.v_head(last_hidden_state).squeeze(-1) # 这是计算 PPO 中价值损失 L_VF 和优势 A_hat 的基础
# (确保 logits 是 float32,为了数值稳定性)
if lm_logits.dtype != torch.float32:
lm_logits = lm_logits.float()
# 返回 Actor 的 logits, LM loss (可能为 None), 和 Critic 的 value
return (lm_logits, loss, value)对于 PPO-RLHF 训练的每一步:
- 我们把当前的一批 prompt (序列
input_ids) 输入模型。 self.pretrained_model(Actor) 会计算(Rollout)出lm_logits。这些 logits 代表了在当前 prompt 下,模型认为接下来应该生成哪些词元的概率分布。PPO 的策略损失 和熵奖励 都需要基于这个概率分布来计算。- 同时,我们从
base_model_output中取出last_hidden_state。这可以看作是当前 prompt (状态 s) 的一个向量表示。 - 这个
last_hidden_state被送入self.v_head(Critic),输出一个标量value。这个value就是模型对当前状态 s 的价值估计 。PPO 的价值函数损失 就是要优化这个 ,使其尽可能接近真实的回报。并且,这个 也是计算优势函数 的关键组成部分,而 又会指导 的计算。 - 同样的 prompt + response 序列输入给 Reward 和 Reference model 做推理,得到 reward 和 log probs(计算 KL 惩罚)。
所以一次 forward 调用,我们就同时获得了更新 Actor (策略) 和 Critic (价值函数) 所需的核心信息。
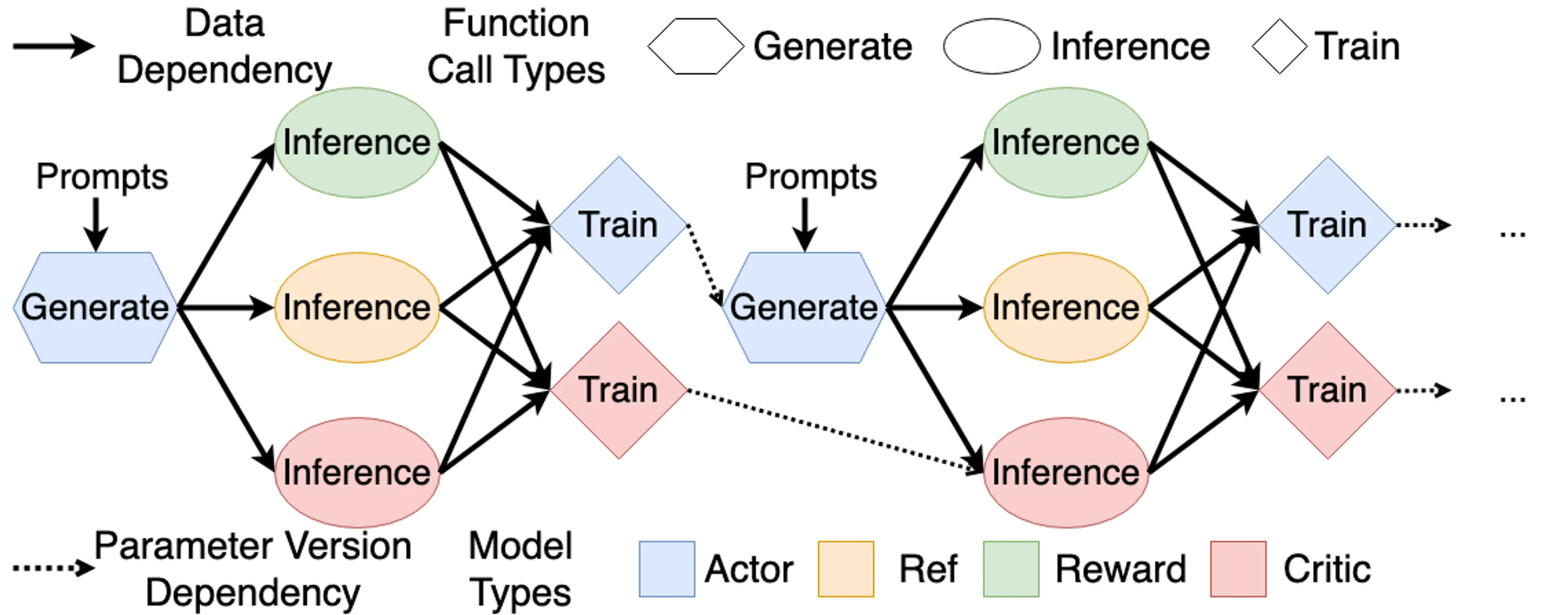
训练的流程可以借下图帮助了解:
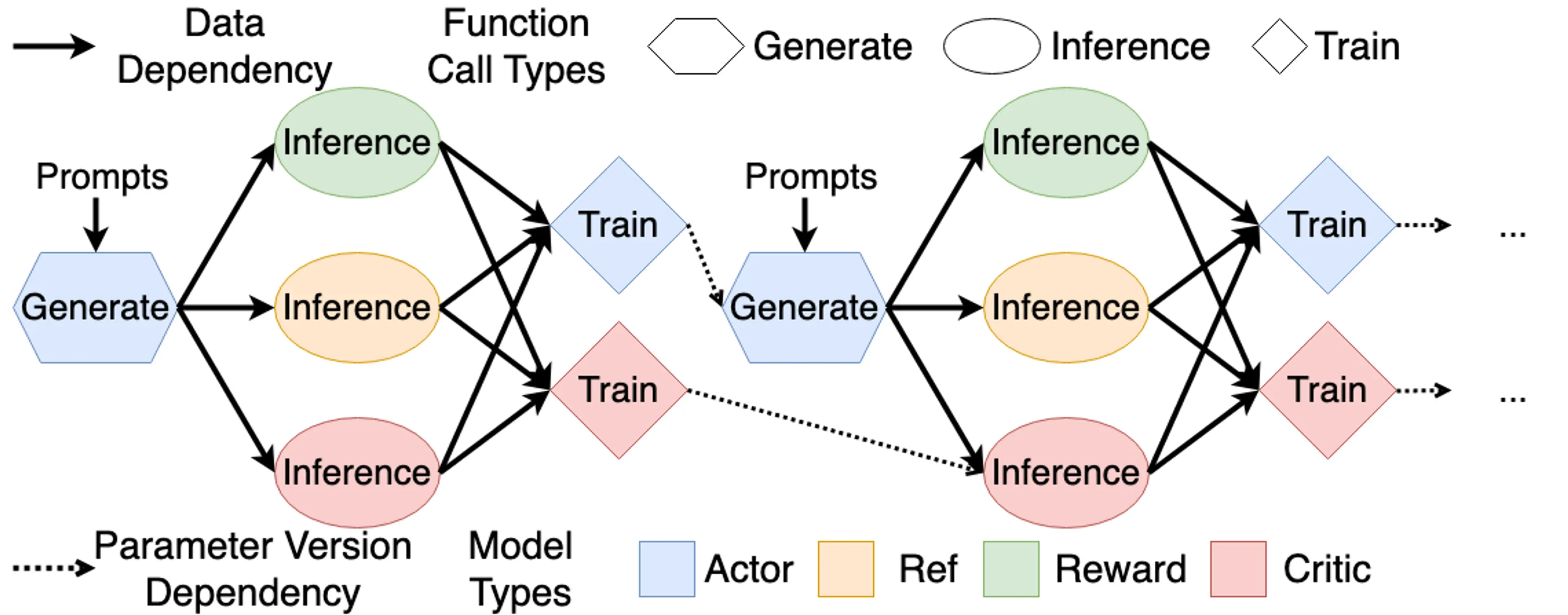
[!tip] 在 RLHF 中,只有 Actor 在经验收集(Rollout)时需要 Prefill + Decode(完整的 Auto-Regressive Generation),其余的模型都是在处理已有的 response 获取 logprob 和 value 等,只做 Prefill。
此外 Actor 涉及训练和推理(指 Rollout),因此需要 training engine(如 Megatron、DeepSpeed 和 FSDP) + rollout engine(如 SGLang 和 vLLM)两者来各完成自己擅长的任务;Critic 推理时复用训练的 forward 中的内部表征来输出新的 value 预测,因此运行在同一个 training engine 中;而 Reference 和 Reward model 都只用推理引擎来得到 logprob 和 reward 即可。
verl
和 OpenRLHF 等都是优秀的 RLHF 框架,一个比较好的导读:【AI Infra】VeRL 框架入门&代码带读