学习如何在有限的显存条件下微调大语言模型,掌握半精度、量化、LoRA 和 QLoRA 等关键技术。
微调之道

为什么要微调
选择 LLM 完成一个 NLP 任务,如何下手? 从下图中就能很好的明白哪个操作适合完成你当前的任务:

如果你有时间和大量数据,你完全可以重新训练模型;一定量的数据,可以对预训练模型进行微调;数据不多,最好的选择是“in context learning”,上下文学习,如 RAG。
当然,这里我们主要研究微调这部分,微调让我们无需重新训练模型就可以取得比原先更好的表现。
怎么微调
众所周知,显卡(显存)是限制我们平民玩家玩 LLM 的瓶颈,大部分人只能购买消费级显卡,如 RTX 系列,因此需要找到一种能够利用这 16GB 显存进行微调的聪明办法。

微调的瓶颈
在训练 llama 7B 这样中等参数量的模型时,我们可能需要大大概 28GB VRAM 来存储模型原先的参数(下面会讲这是怎么估计的),再需要等量的显存来存储训练过程中的梯度,通常还需要用参数量两倍的量来跟踪优化器的状态。
来计算一下:
那我缺的这块 96GB 的显存谁给我补啊?
解决问题
半精度
第一步就是加载模型本身,对于 7B 模型,其中的每个参数的单位都是 32 位浮点数。 一个字节是 8bits,所以 32 位需要 4 字节 (4B)。7Billion,也就是 70 亿,总共需要的存储大小就是。 ()
我们这里就超出了 28-16=12GB,因此需要想办法将模型的参数打包成一个更小的形式,一个非常自然的想法就是对参数的单位下手,能不能改用 16 或者是 8 位的浮点数呢,(分别对应 2B、1B 的单位存储空间),只要换成 F16 就可以把这部分的显存需求折半。As the tradeoff,相对应的浮点数精度、表示范围会降低,可能会出现梯度爆炸、梯度消失等情况。谷歌对此提出了 bfloat16(brain float,脑浮点),其核心目的就是提供一种既能保持较宽的数值范围 (相较于 IEEE 规范,exponent: 5bit 到 8bit),又能简化硬件实现的浮点格式 (fraction: 10bit 到 7bit),从而在不牺牲过多精度的情况下加速深度学习模型的训练和推理过程。
我们选择 16 位浮点数,显存需求减半后一张卡就够用了:

量化
这里简单说下神经网络的训练流程:
我们对输入内容进行 forward pass(前向传播),也就是激活,然后使用结果与预测目标进行比较,根据预测和实际目标之间的差异 (损失),计算损失函数对于每个参数的梯度 (偏导数) 用于 BP(反向传播),选择一个优化算法 (如 SGD,即随机梯度下降) 来更新参数,多轮迭代后得到模型。
模型中的梯度通常与原始模型中的参数拥有同样的数据类型,对于每个参数都有对应的梯度,因此在不考虑优化器的时候都需要两倍参数量的显存。
一般会采用 Quantized(量化) 的方法,我们可以选择 8 位浮点数

图源自Nvidia 博客
可以看到在量化过程中,数据的表示范围会被压缩,数据会压缩而集中,每个参数之间的差异减小,这可能导致大量的信息损失。对于那些超出新表示范围的异常值进行剪切,可以减少由于这些极端数值引起的量化误差。
选择 int8 量化后,我们把模型参数和梯度所需要的内存砍到了 14GB:

LoRA
尽管我们做了这么多努力,但优化器才是关键部分。
业界喜爱而常用的 Adam 优化器效果很好,但也有相当高的内存占用,原因如下:
Adam 优化器在每一步迭代中会更新参数,使用的更新公式如下(不必须深入理解数学):
- 计算梯度的一阶矩估计(即梯度的均值)和二阶矩估计(即梯度的未中心化的方差)
其中,是在时间步的梯度,和是衰减率,通常取值接近 1,对应Karpathy 的 Batch-Norm 教程在第 3 小节介绍的指数移动平均。
- 对和进行偏差校正,以修正它们的偏差向 0 的初始化偏差
- 使用修正后的一阶矩估计和二阶矩估计来更新参数:
其中,是学习率,是为了保持数值稳定而加入的一个很小的常数。
这个过程在每个时间步重复,直到模型的参数收敛或达到某个停止条件。
对于1.中的 momentum vector(动量向量),和 variance(方差) 向量,它们都各自有 7B 的参数,这是前面提到的需要 2 倍参数量的原因。
这里的解决方案就是 LoRA(Low-Rank Adaptation),低秩适应:

这项技术可以减少可训练参数数量,达到了减少模型权重占用空间,加快训练速度的效果。在这个情景下,LoRA 显著地减少了需要被优化器以及梯度追踪的参数量,减少了训练过程中需要的显存。
LoRA 背后的关键思想是,当对 llama2 这样的大模型进行微调时,你不需要对每个参数都微调(也就是全参数微调),因为通常有一些参数和层相较于其它的来说更重要,如负责注意力机制和确定序列中哪些 token 与其它 token 相关以及相关方式的部分会更重要。LoRA 会取出这些特定的参数,注入低秩矩阵,后面训练和传播、更新参数时,修改的只是这个辅助的低秩矩阵。

LoRA 中的 R 超参数,也就是秩是可以调整的。但一般在实践中,可能 LoRA 选取的特定参数只占总体的 10% 以下。

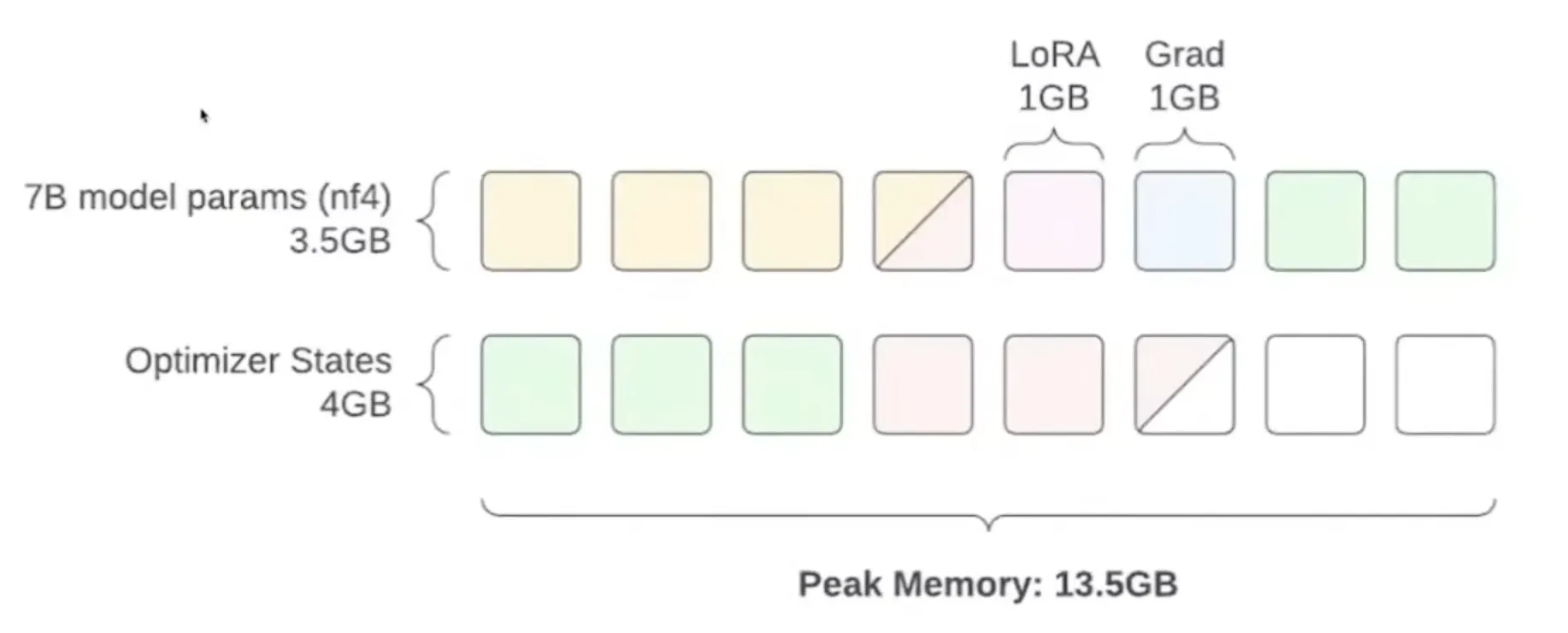
对于 LoRA 参数,选择精度较高的 fp16,而优化器状态的单位则是 fp32,因此内存占量在这里是参数量的四倍。
但这里还有一个问题,那就是激活部分。激活的前向传播过程中的开销,是神经网络中最大层的大小批次大小 batch size(一次更新多少样本),这可能还会占用 5G 的内存,仍然超出了我们的预算。
QLoRA
那我们能不能使用 4bit 量化呢? 这就是 QLoRA 这篇论文提出的思想,其所做的就是通过paged atom(分页原子)优化技术,在需要时让优化器状态的分页内存移到 CPU 上,减少训练期间训练峰值的影响:

为此,引入了新的单位nf4(normal float 4)。

又能省下一些显存:

梯度累计
最后的一个问题在于 Batch Size 的选取上。如果我们选择一次更新很少的样本,训练过程中的方差会很大,极端情况是完全的 SGD(随机梯度下降)。所以一般会选择中间地带,也就是步伐在大而平滑与小而急促之间的 sweet spot,这也是为什么一般都选择 23, 64, 128 作为 batch size。
但我们现在只能一次加载一个样本,因此引出了 Gradient Accumulation 技术。
其关键思想在于,不增加额外内存开销的情况下获得使用更大 batch size 的训练效果。

其中的操作:
分批处理:将较大的批量数据分成多个小批量(这些小批量的大小是基于可用内存资源确定的)。对于每个小批量:
- 执行前向传播来计算损失。
- 执行反向传播来计算当前小批量的梯度,但不立即更新模型参数。
梯度累积:将每个小批量计算得到的梯度累加到之前的梯度上,而不是立即用它们来更新参数。
参数更新:在处理完所有的小批量数据,并累积了足够数量的梯度之后,使用累积的梯度来一次性更新模型的参数。
微调实战:Mistral 7B
QLoRA
16GB VRAM
Mixtral 8x7B (MoE)
硬件需求:>=65GB VRAM
感谢阅读,我会尽快更新微调实战部分~