#Deep Learning
14 posts

Visual Language Models, with PaliGemma as a Case Study
Thanks to Umar Jamil’s excellent video tutorial. Vision-language models can be grouped into four categories; this post uses PaliGemma to unpack VLM architecture and implementation details.
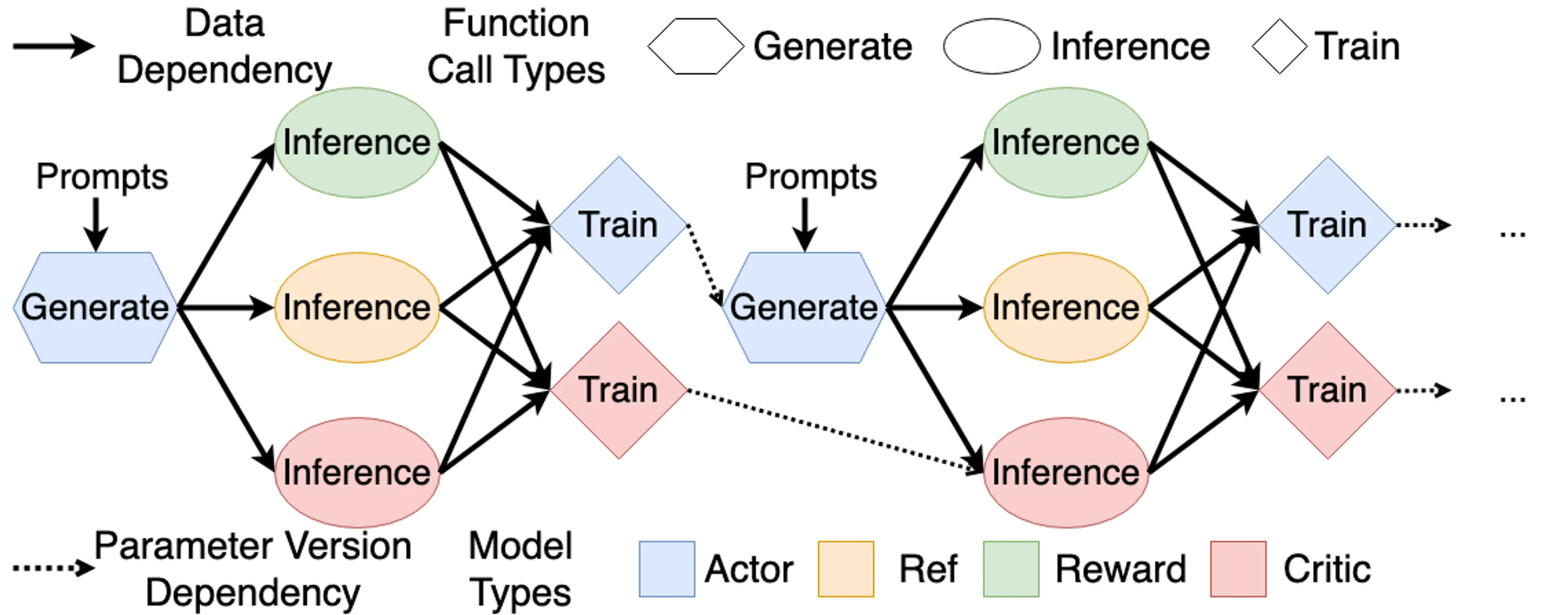
From RL to RLHF
This article is primarily based on Umar Jamil's course for learning and recording purposes. Our goal is to align LLM behavior with our desired outputs, and RLHF is one of the most famous techniques for this.

The Intuition and Mathematics of Diffusion
Deeply understand the intuitive principles and mathematical derivations of diffusion models, from the forward process to the reverse process, mastering the core ideas and implementation details of DDPM.
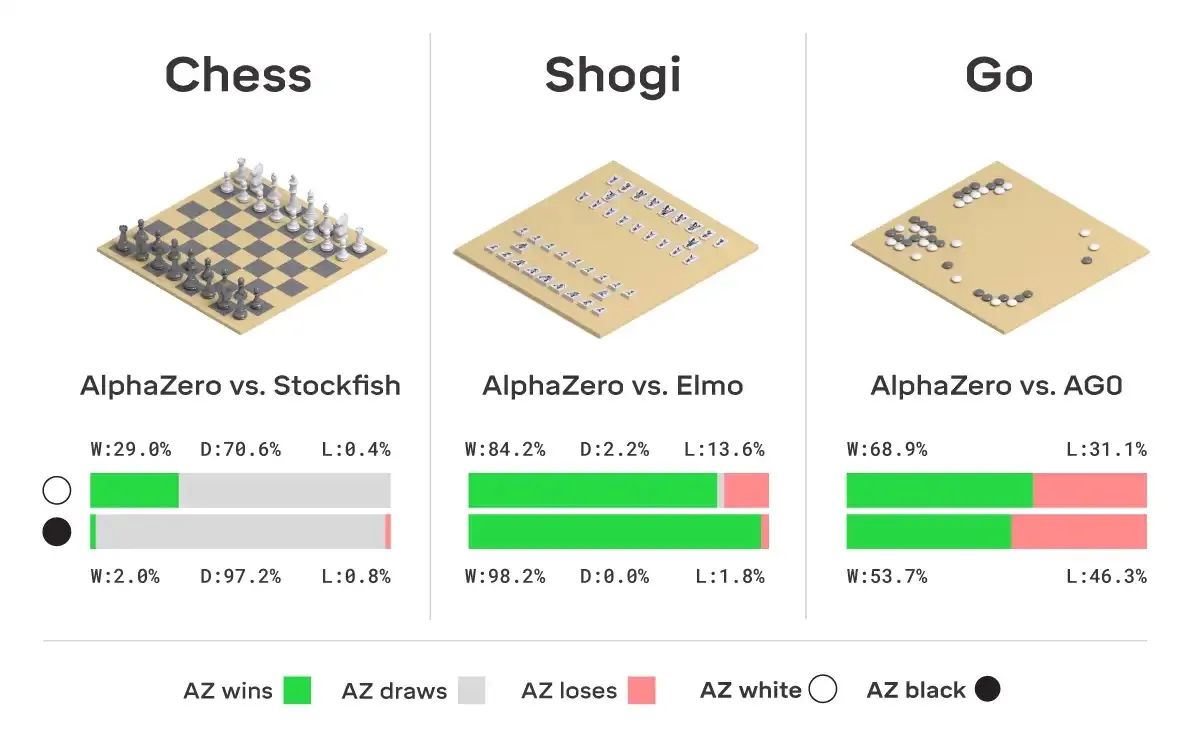
Let's build AlphaZero
Starting from the design principles of AlphaGo and diving deep into the core mechanisms of MCTS and Self-Play, we reveal step-by-step how to build an AI Gomoku system that can surpass human capabilities.

PPO Speedrun
Quickly understand the core ideas and implementation details of the PPO (Proximal Policy Optimization) algorithm, and master this important method in modern reinforcement learning.

Introduction to Knowledge Distillation
Learn the basic principles of Knowledge Distillation and how to transfer knowledge from large models (teachers) to small models (students) for model compression and acceleration.

Vector Add in Triton
Starting from simple vector addition, learn how to write Triton kernels and explore performance tuning techniques.

Softmax in OpenAI Triton
Learn how to write efficient GPU kernels using OpenAI Triton, implementing the Softmax operation and understanding Triton's programming model.

History of LLM Evolution (5): Building the Path of Self-Attention — The Future of Language Models from Transformer to GPT
Building the Transformer architecture from scratch, deeply understanding core components like self-attention, multi-head attention, residual connections, and layer normalization.
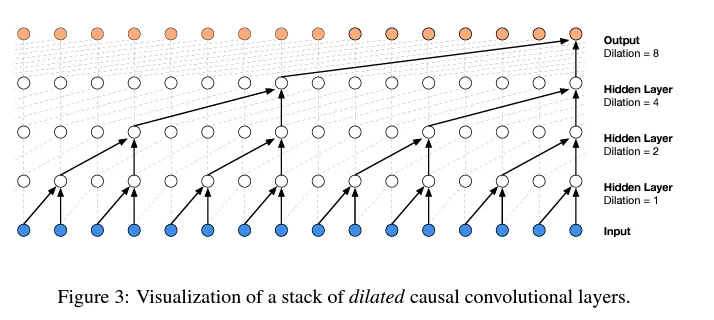
History of LLM Evolution (4): WaveNet — Convolutional Innovation in Sequence Models
Learn the progressive fusion concept of WaveNet and implement a hierarchical tree structure to build deeper language models.
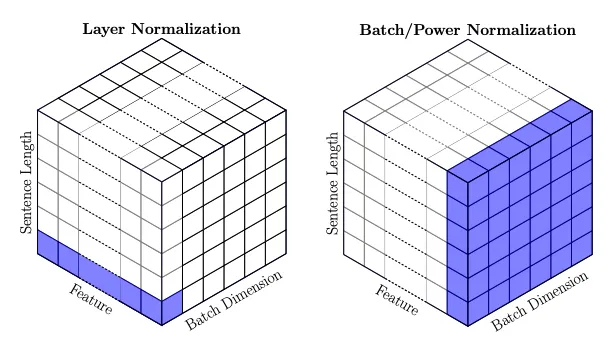
History of LLM Evolution (3): Batch Normalization — Statistical Harmony of Activations and Gradients
Deeply understand the activation and gradient issues in neural network training, and learn how batch normalization solves the training challenges of deep networks.
History of LLM Evolution (2): Embeddings — MLPs and Deep Language Connections
Exploring Bengio's classic paper to understand how neural networks learn distributed representations of words and how to build a Neural Probabilistic Language Model (NPLM).

History of LLM Evolution (1): The Simplicity of Bigram
Starting with the simplest Bigram model to explore the foundations of language modeling. Learn how to predict the next character through counting and probability distributions, and how to achieve the same effect using a neural network framework.

Building a Minimal Autograd Framework from Scratch
Learning from Andrej Karpathy's micrograd project, we build an automatic differentiation framework from scratch to deeply understand the core principles of backpropagation and the chain rule.