#AI
10 posts
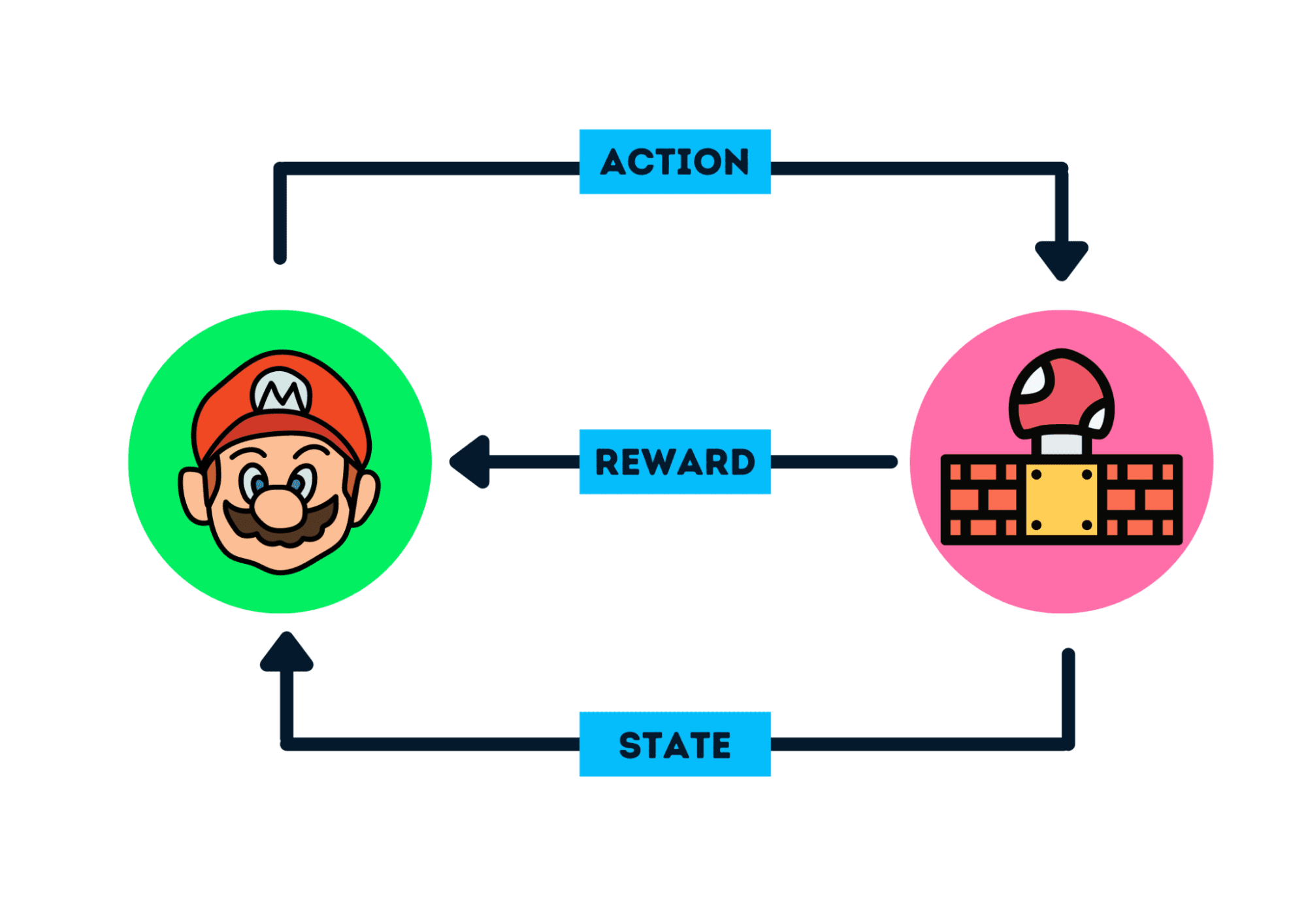
Reinforcement Learning Basics and Q-Learning
Learning the fundamental concepts of Reinforcement Learning from scratch, and deeply understanding the Q-Learning algorithm and its application in discrete action spaces.

Vector Add in Triton
Starting from simple vector addition, learn how to write Triton kernels and explore performance tuning techniques.
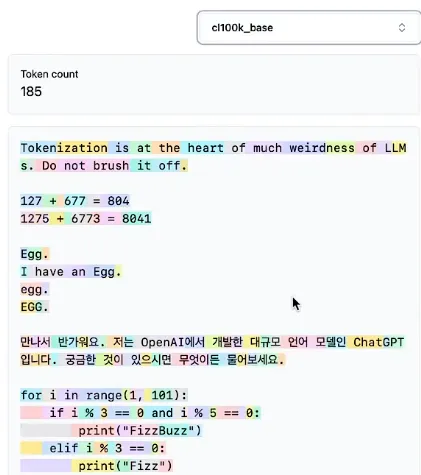
History of LLM Evolution (6): Unveiling the Mystery of Tokenizers
Deeply understand how tokenizers work, learning about the BPE algorithm, the tokenization strategies of the GPT series, and implementation details of SentencePiece.
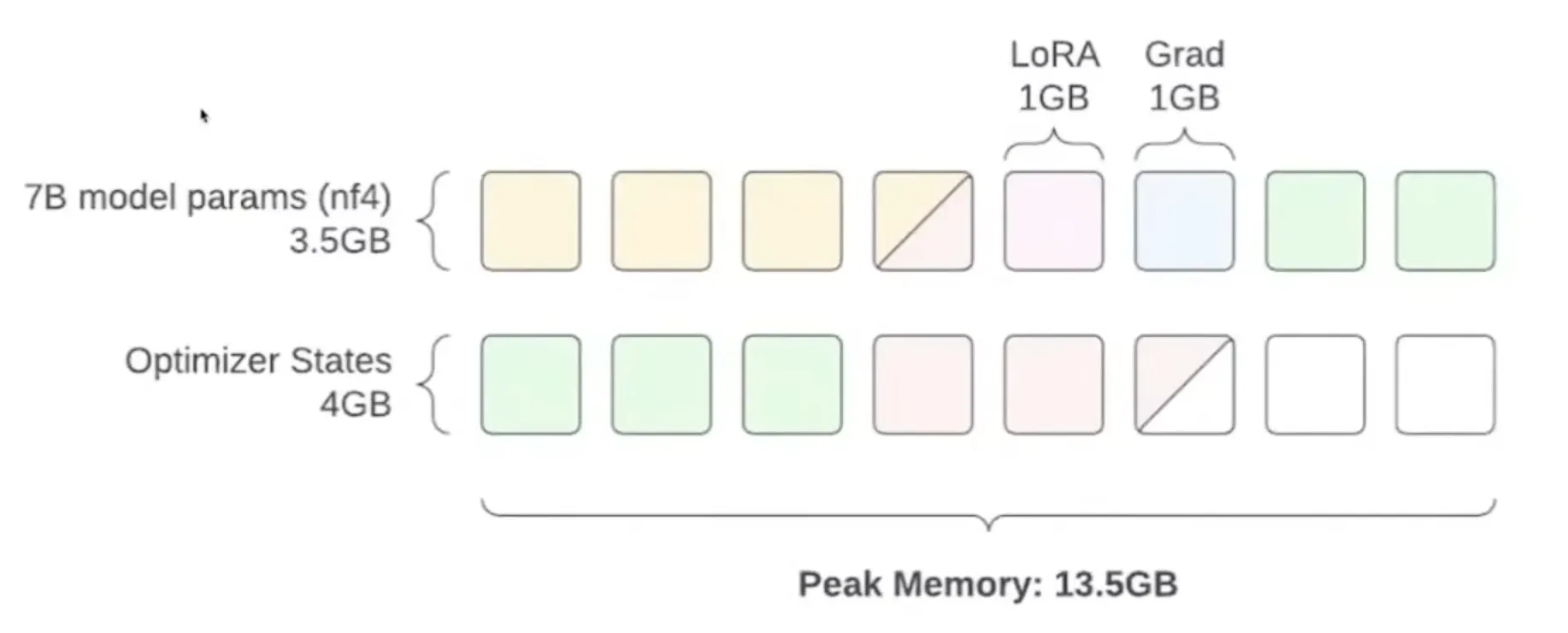
The Way of Fine-Tuning
Learn how to fine-tune large language models under limited VRAM conditions, mastering key techniques like half-precision, quantization, LoRA, and QLoRA.
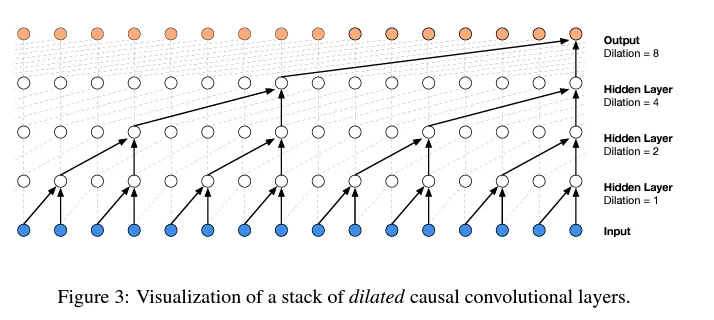
History of LLM Evolution (4): WaveNet — Convolutional Innovation in Sequence Models
Learn the progressive fusion concept of WaveNet and implement a hierarchical tree structure to build deeper language models.
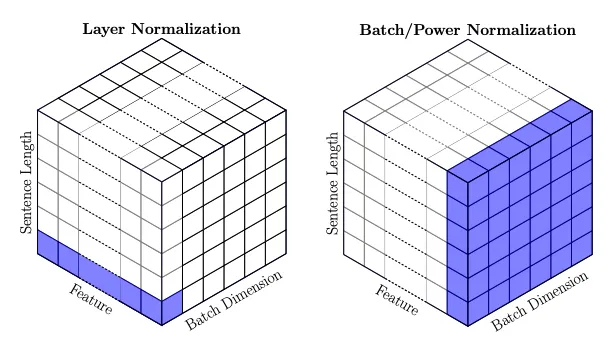
History of LLM Evolution (3): Batch Normalization — Statistical Harmony of Activations and Gradients
Deeply understand the activation and gradient issues in neural network training, and learn how batch normalization solves the training challenges of deep networks.

The State of GPT
A structured overview of Andrej Karpathy's Microsoft Build 2023 talk, deeply understanding GPT's training process, development status, the current LLM ecosystem, and future outlook.
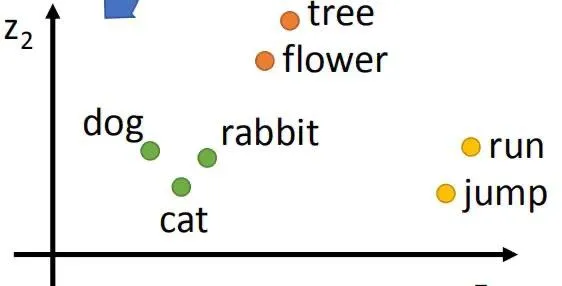
History of LLM Evolution (2): Embeddings — MLPs and Deep Language Connections
Exploring Bengio's classic paper to understand how neural networks learn distributed representations of words and how to build a Neural Probabilistic Language Model (NPLM).

History of LLM Evolution (1): The Simplicity of Bigram
Starting with the simplest Bigram model to explore the foundations of language modeling. Learn how to predict the next character through counting and probability distributions, and how to achieve the same effect using a neural network framework.

Building a Minimal Autograd Framework from Scratch
Learning from Andrej Karpathy's micrograd project, we build an automatic differentiation framework from scratch to deeply understand the core principles of backpropagation and the chain rule.