Quests
#LLM
9 posts
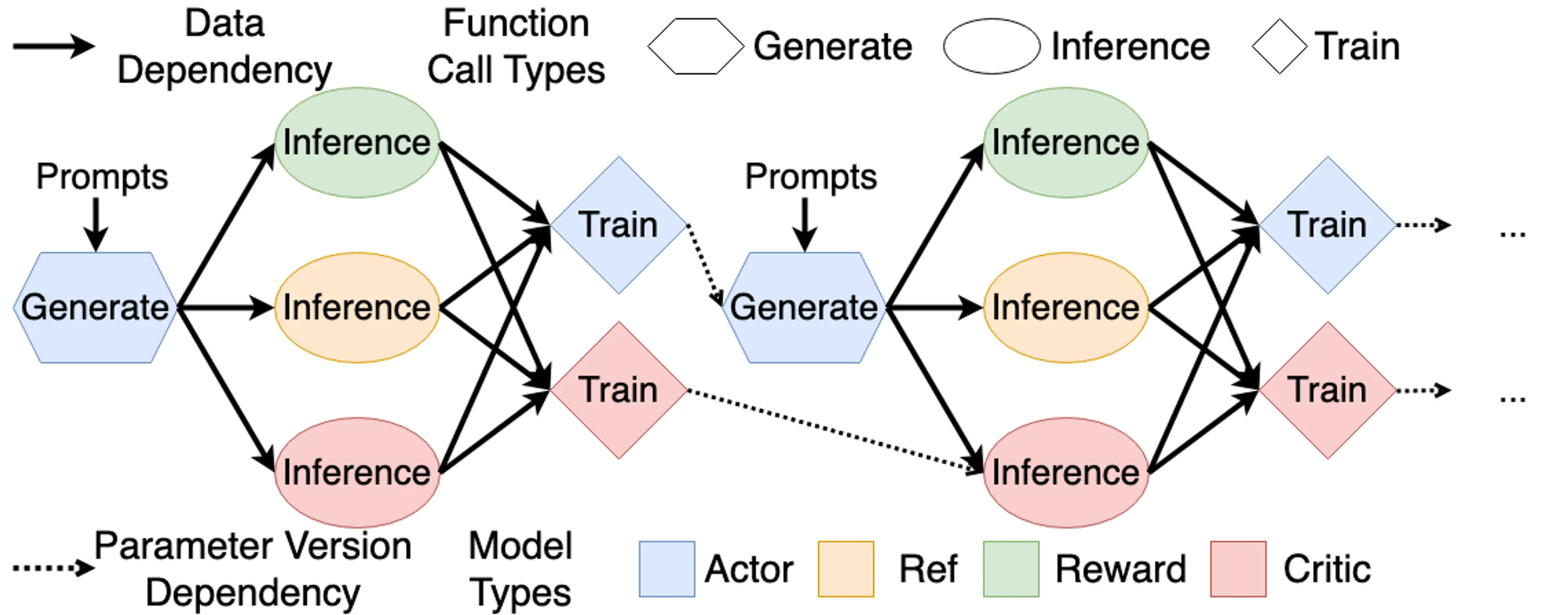
从 RL 来,到 RLHF 去
本文主要基于 Umar Jamil 的课程进行学习和记录。我们的目标是让 LLM 的行为与我们的期望的输出相一致,RLHF 则是最著名的技术之一。

用 Rust 实现简单 LLM 推理
在 B 站偶然刷到清华大学主办的大模型与人工智能系统训练营,果断报名参加。计划利用春节返乡时间通过实践巩固 LLM Inference 的理论知识,恰逢学校 VPN 故障无法科研,正好整理学习笔记。
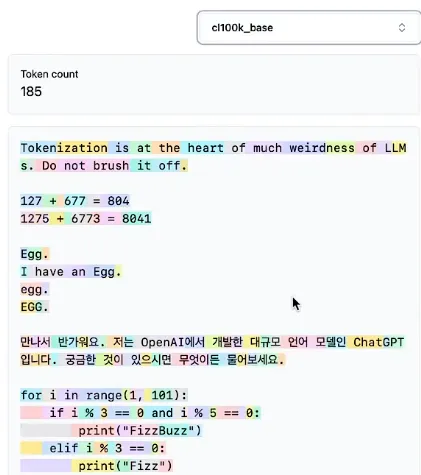
LLM 演进史 (六):揭开 Tokenizer 的神秘面纱
深入理解 Tokenizer 的工作原理,学习 BPE 算法、GPT 系列的分词策略以及 SentencePiece 的实现细节。

LLM 演进史 (五):构筑自注意力之路——从 Transformer 到 GPT 的语言模型未来
从零开始构建 Transformer 架构,深入理解自注意力机制、多头注意力、残差连接和层归一化等核心组件。
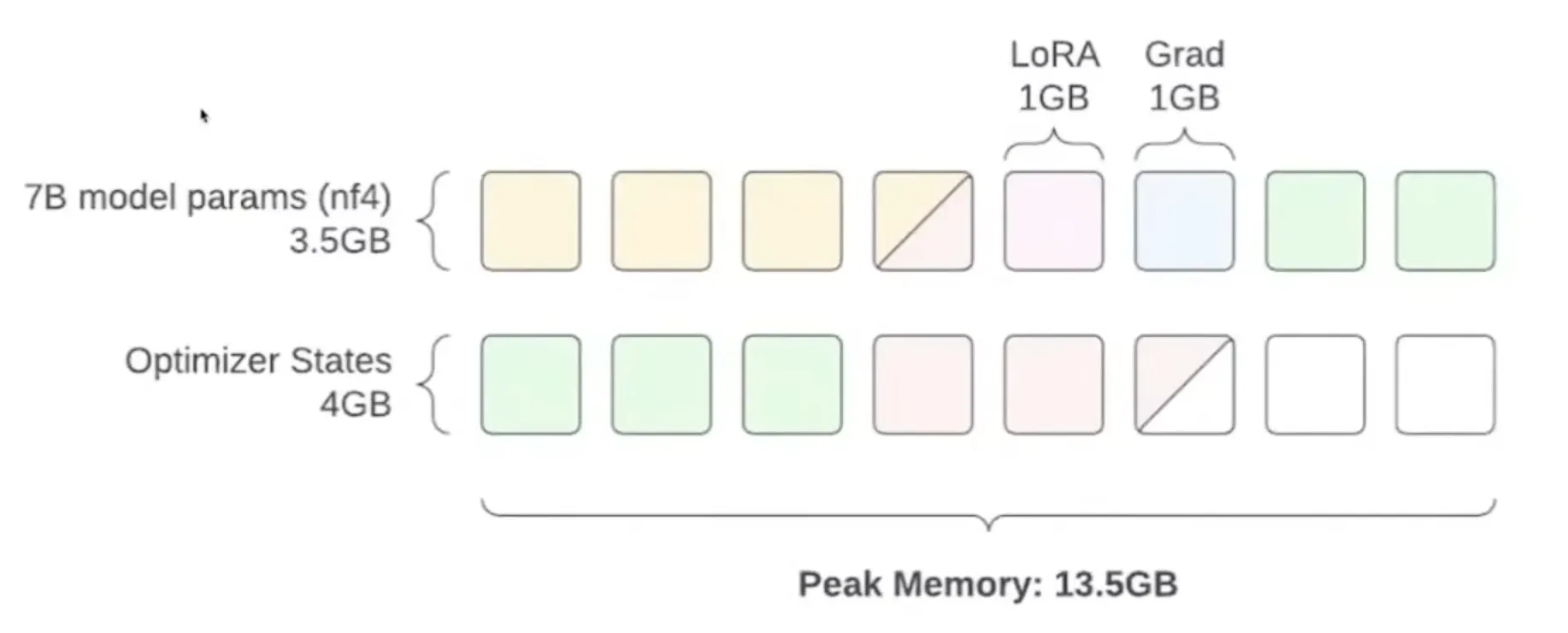
微调之道
学习如何在有限的显存条件下微调大语言模型,掌握半精度、量化、LoRA 和 QLoRA 等关键技术。
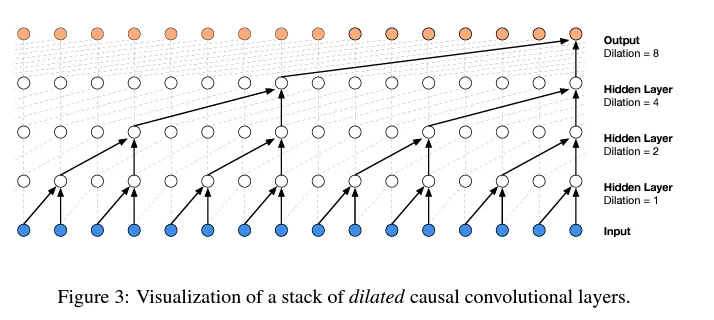
LLM 演进史 (四):WaveNet——序列模型的卷积革新
学习 WaveNet 的渐进式融合思想,实现树状分层结构来构建更深的语言模型。

GPT 的现状
整理 Andrej Karpathy 在 Microsoft Build 2023 的演讲,深入理解 GPT 的训练过程、发展现状、当前 LLM 生态以及未来展望。
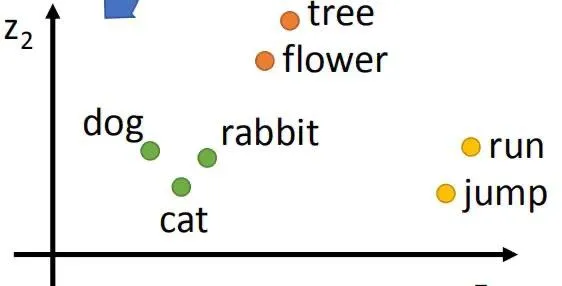
LLM 演进史 (二):词嵌入——多层感知器与语言的深层连接
探索 Bengio 的经典论文,了解如何通过神经网络学习词的分布式表示,以及如何构建一个神经概率语言模型 (NPLM)。

LLM 演进史 (一):Bigram 的简洁之道
从最简单的 Bigram 模型开始,探索语言模型的基础。了解如何通过计数和概率分布来预测下一个字符,以及如何用神经网络框架实现相同的效果。