1 post
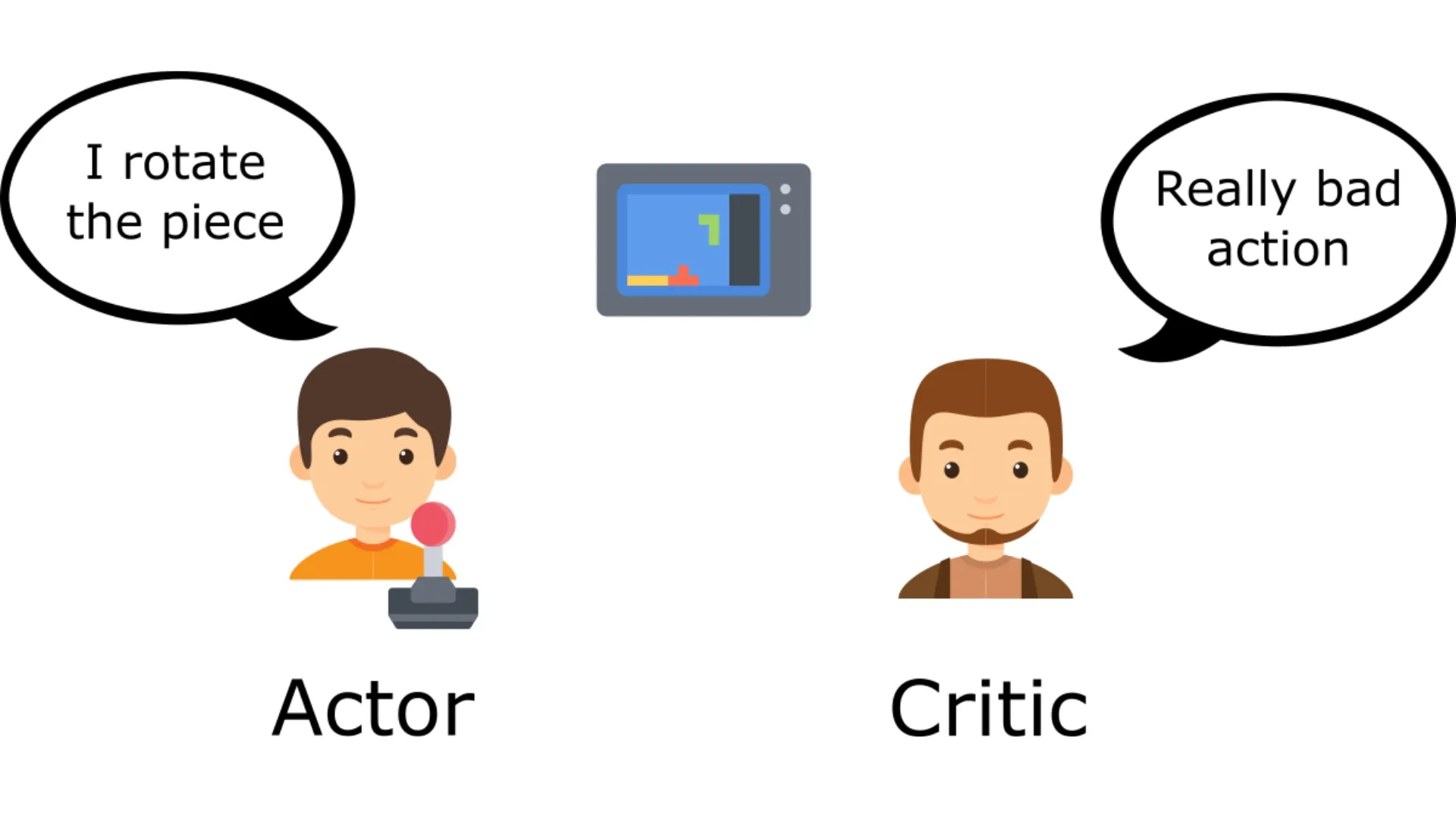
Exploring the Actor-Critic method, which combines the strengths of policy gradients (Actor) and value functions (Critic) for more efficient reinforcement learning.