Quests
#RL
5 posts

"速通" PPO
快速理解 PPO(Proximal Policy Optimization)算法的核心思想和实现细节,掌握现代强化学习的重要方法。
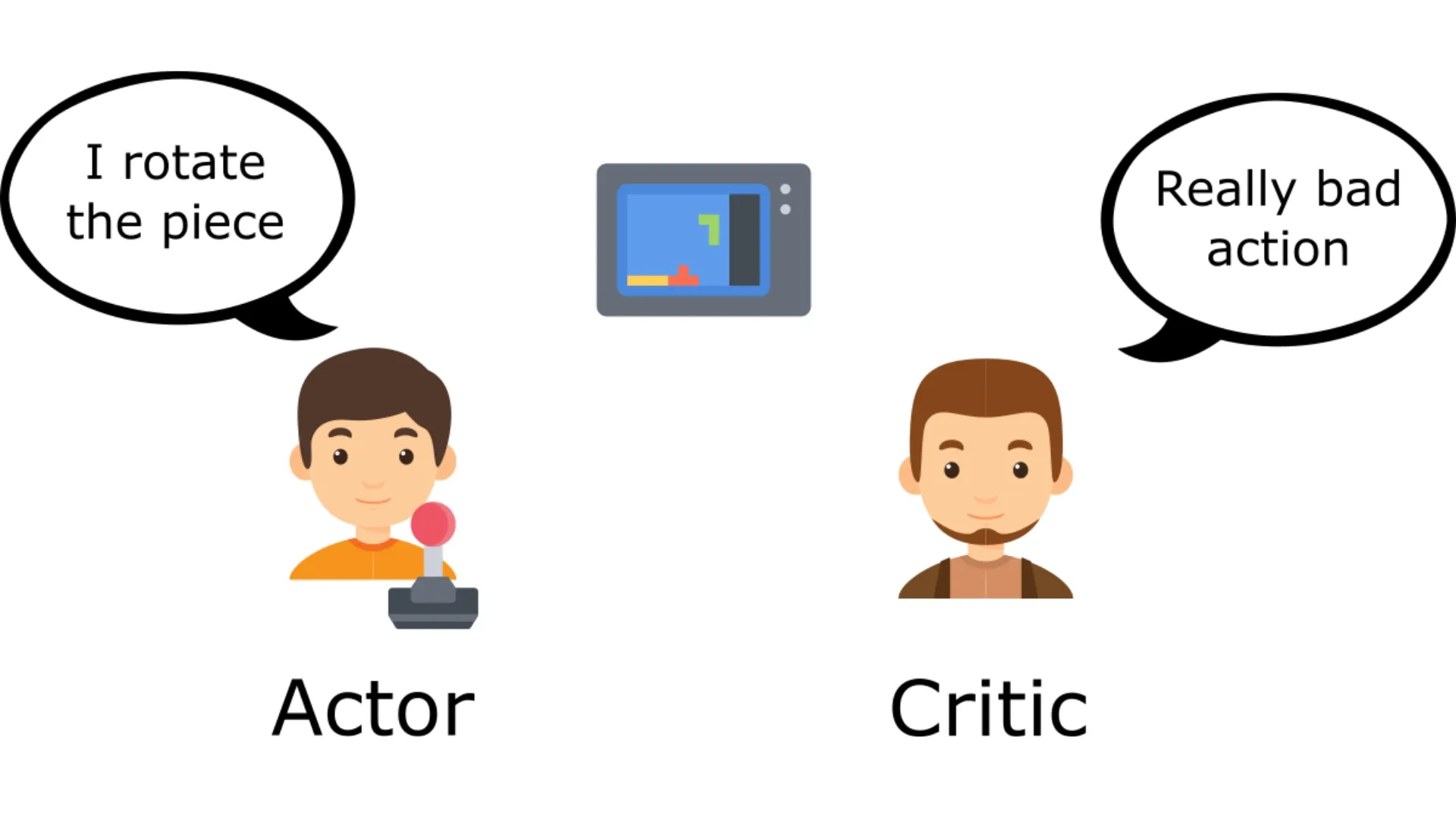
Actor Critic 方法初探
学习 Actor-Critic 方法,结合策略梯度(Actor)和价值函数(Critic)的优势,实现更高效的强化学习。

从 DQN 到 Policy Gradient
探索从基于值的方法(DQN)到基于策略的方法(Policy Gradient)的演进,理解两种方法的区别和联系。
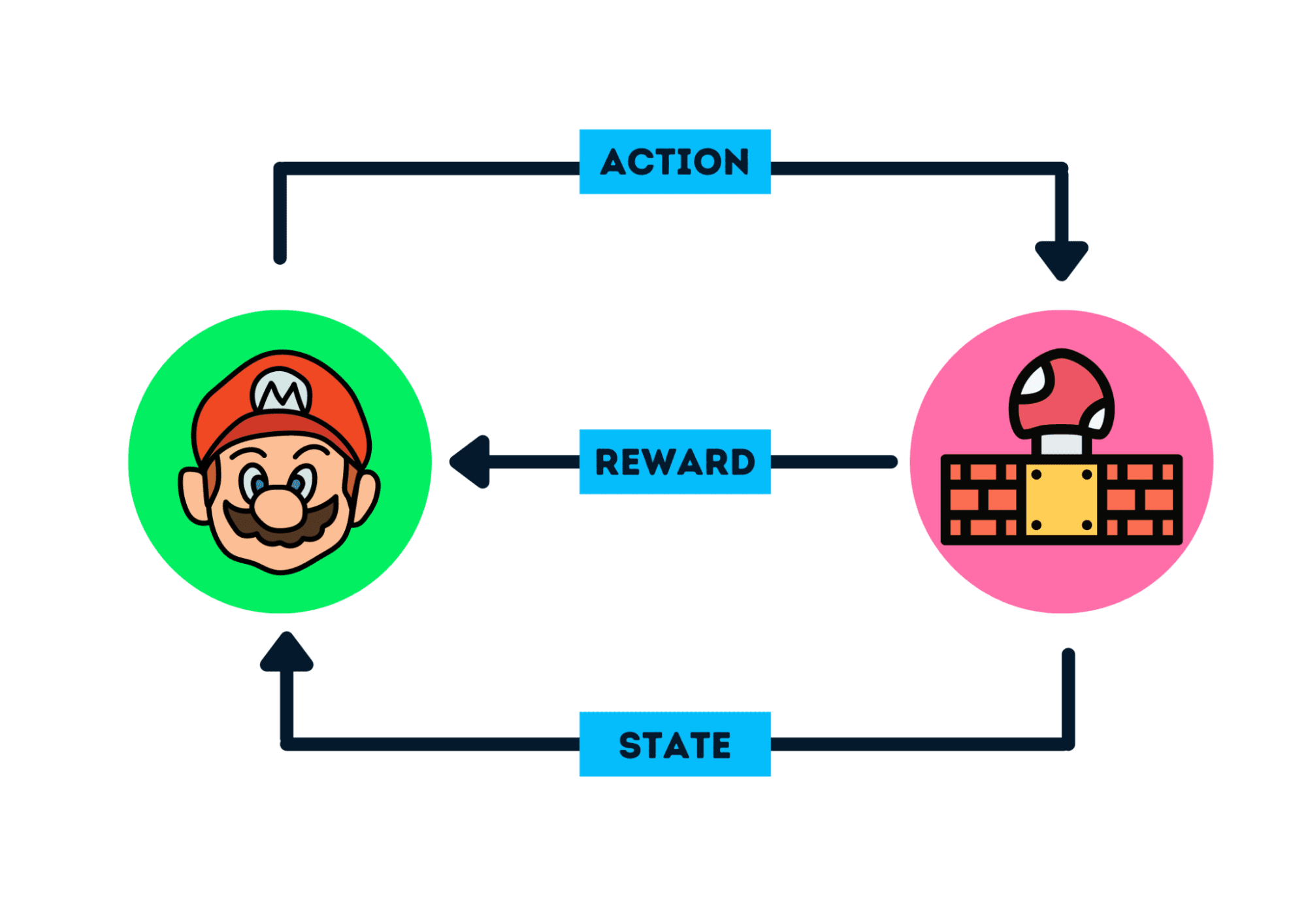
强化学习基础与 Q-Learning
从零开始学习强化学习的基础概念,深入理解 Q-Learning 算法及其在离散动作空间中的应用。
Policy Gradient 入门学习
学习策略梯度方法的基本原理和实现,了解如何通过直接优化策略来训练强化学习智能体。