
2024 marked my first encounter with deep learning and my entry into the field of large models. Perhaps looking back someday, this year will stand out as one of many pivotal choices.
2024 Year in Review
2024 marked my first encounter with deep learning and my entry into the field of large models. Perhaps looking back someday, this year will stand out as one of many pivotal choices.
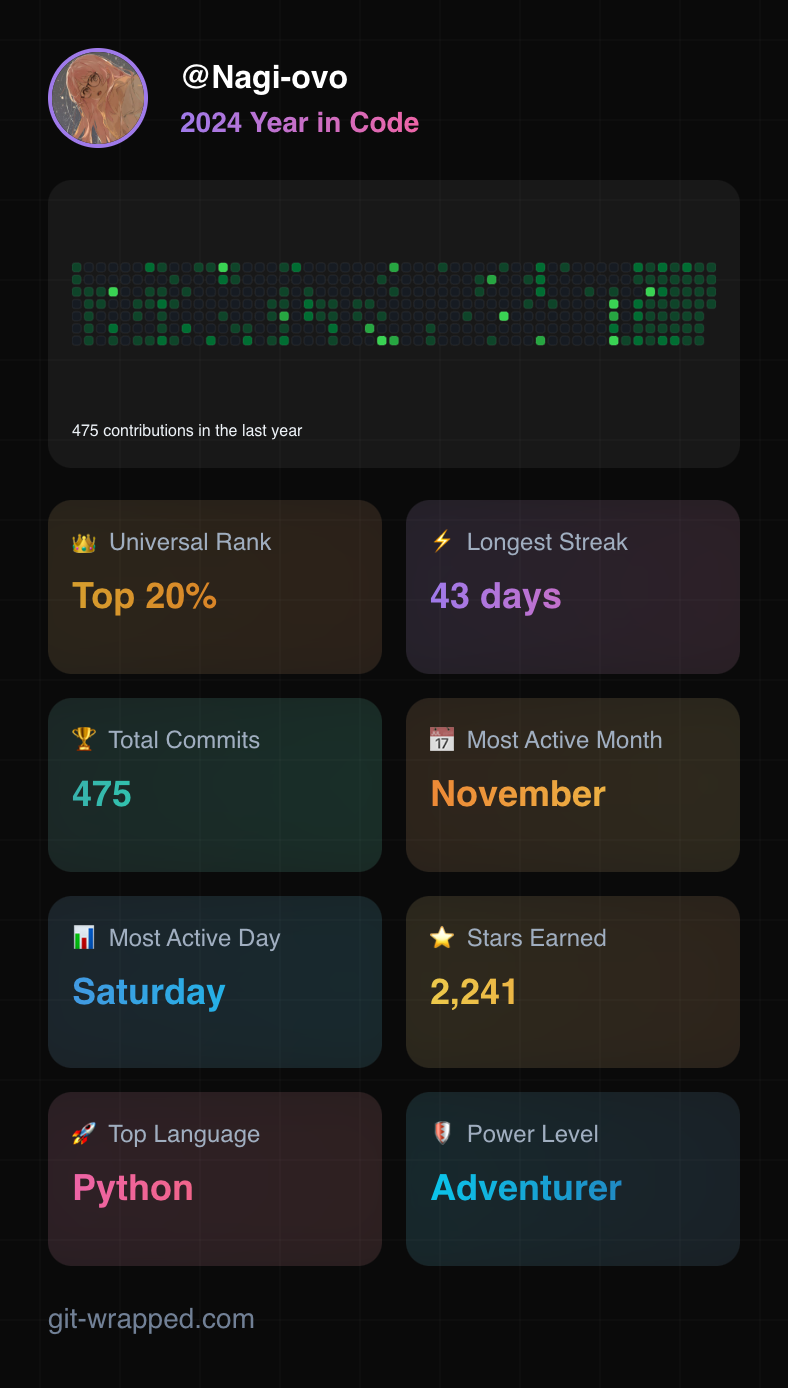
First, here is my Coding Annual Summary:
I am based in Beijing, majoring in Artificial Intelligence at a standard Project 211 university. For the first two years, I focused mainly on climbing the ranks in FPS games. Later, I developed a strong interest in frontend development, learning everything from JS to React. My interest in CS and subsequent dive into open courseware is a story for later. I plan to write a memoir of my four college years, but to ensure I can speak freely, I’ll save that for six months from now. For now, I’ll just record 2024. In short, before this year, my goal was to improve my development skills and work as an SDE after a bachelor’s or a one-year master’s abroad. Influenced somewhat by my curriculum, I viewed AI and academia as chaotic fields. Apart from using GPT-4 to help write code, I didn’t intend to have any contact with AI.
Winter Break: Encountering Deep Learning
Since my school was offering a Deep Learning course in the second semester of my junior year, I decided to learn a bit ahead during winter break. Having previously found the “Watermelon Book” (Zhou Zhihua’s Machine Learning) confusing, and discovering that foreign open courses like CS229 or YouTube tutorials suited me better, I Googled around and found Andrej Karpathy’s “nn-zero-to-hero” tutorial. IT was a delightful surprise! In the very first lesson, he helped me understand the core concepts of deep learning by implementing automatic differentiation. I highly recommend it as an introductory course. There’s also a translated version on Bilibili:
Guided by him, I went from n-grams and word2vec all the way to CNNs in one go. I had heard the term Convolutional Neural Network repeatedly in research group meetings I randomly joined as a freshman, but no one could explain what these models were doing in plain language to a first-year student. Finally, the moment I implemented the GPT-2 model with my own hands, the door to a dazzling world slowly opened before my eyes. My attitude towards AI shifted to genuine fascination: “Oh, so I can actually peek into a corner of the underlying mechanics of ChatGPT, the Killer App.”
A direct realization here was that the toolchains and mindset I picked up while learning frontend and backend development were helpful for learning DL. The most basic benefit was having a rough concept when configuring environments and migrating intuition from other fields. Therefore, when junior students ask me for learning roadmaps, I usually tell them to start by learning a bit of frontend/backend development to make up for the lack of practical training in school education and to broaden their horizons.
At this time, I also encountered @DIYgod’s blog platform, xLog. After trying it, I resolutely moved my personal blog from Hexo+gh-page to xLog. Beyond being beautiful, user-friendly, and fully customizable, the most important feature was the community traffic, which provided better positive feedback 🥹.
Welcome to visit! After catching up on MyGo this year, both my avatar and website icon feature Anon Tokyo 🥰.
Internship: Viewing the LLM Landscape as an Outsider
This year saw numerous LLM-related competitions on Kaggle. I chose the Google-sponsored LLM Prompt Recovery competition as my main focus. This was purely a gamble on “miracles through brute force,” seeing that everyone else was generally confused about it. Later, I put some effort into the data, and with a bit of luck, I reached second place on the public leaderboard. Under the double pressure of my internship and daily life, my time investment decreased, but I barely managed to secure my first silver medal in a competition.
By March, the pressure shifted to securing internship credits for the summer. Based on past experience, I deduced that the positions arranged by the school would likely be of lower quality (which turned out to be true—hard to describe in a word). So, I started sending resumes on BOSS in late March. I didn’t consider small to medium-sized companies that offered interviews if they had nothing to do with large models. Back then, I naively thought that finishing Karpathy’s course and hand-coding Transformer and GPT-2 was enough to find an LLM internship. I didn’t expect that my school credentials weren’t strong enough, and without other highlights or connections, I fell into a painful spiral, feeling that the path of large models was a dead end for me.
Just then, a team at Pony.ai (Lou Tiancheng’s company) wanted to recruit an intern with knowledge in the field. The work involved fully following up on an internal project. I felt this might be my best opportunity at this stage, and pragmatically speaking, it would enrich my resume, so I accepted the offer. The courses in the second semester of my junior year were still not worth studying, but fortunately, the teachers generally had low attendance requirements. After some friendly communication, I went all-in on the internship, attending 4-5 days a week with nearly 3 hours of daily commute. Looking back, it was a painful but happy time. My colleagues and mentor were very nice. Plus, using my professional knowledge to earn my first 10,000 RMB gave me back some confidence in my future.
My work mainly involved researching the workflow of large models in internal data annotation tasks. Essentially, I was calling massive amounts of APIs to experiment. Besides improving the workflow, the most important task was finding the best model. During this time, APIs from various companies were readily available. With the company covering expenses, I could make painless multi-threaded calls. Impressions included but were not limited to: ByteDance’s Skylark & Doubao, Kimi, Alibaba’s open-source and closed-source Qwen models, Baidu’s Ernie, and Tencent’s Hunyuan. The baseline was GPT-3.5 (data couldn’t leave the country, requiring domestic models or private deployment). The only model among these with task performance close to OpenAI was Kimi, but the cost was high, so I started researching other models. Around this time, I had a great experience using DeepSeek-7B-Math in a Kaggle AI math competition, which led me to DeepSeek. They had just released DeepSeek V2, and the pricing of 1 RMB per million tokens for input/output instantly attracted me. In my benchmark tests, I found its performance far exceeded GPT-3.5, and except for slightly weaker instruction following occasionally, it was perfect. Thus, the model running in the business pipeline during that period became DeepSeek.
This section is titled “Viewing the LLM Landscape as an Outsider” precisely because of this: my work didn’t touch the core algorithms of LLMs but rather researched their specific applications. However, my experimental results allowed me to see the true capabilities of various models and my own real strength (this business task really tested the model’s instruction following, information extraction, and reasoning abilities, and the ranking was pretty consistent with LMSYS). This completely desensitized me to the marketing of various vendors, to the point where I could dismiss some companies’ future high-scoring models based on stereotypes alone.
As for later, domestic large model vendors started a price war following DeepSeek, which was super beneficial for the company’s current business. Of course, I didn’t care about Doubao or Ernie’s price cuts, but after Qwen dropped its price, it also made it onto the consideration list. In June, Alibaba released the Qwen 2.0 open-source model. After testing, I started wondering why Alibaba’s open-source models were far better than their closed-source series (like qwen-plus; qwen 2.0 was even better than the expensive qwen-max. I recall this inversion only disappeared after August). From then on, I had the most favorable impression of these two domestic companies’ models, and DeepSeek became my “dream company” (it’s also very close to my high school—I could visit often 🥹). Facts proved that these two continued to maintain excellent momentum, generating high discussion in the foreign open-source community as well. Led by Qwen 2.5/QwQ and the recent DeepSeek V3, the fact that many people accept putting these two models into Cursor for use speaks for itself.
During this period, I met up with @JerryYin777, who had returned to China for an internship. Chatting with him was extremely informative; I learned a lot about the LLM field, learning paths, and interesting anecdotes. We must grab a meal again sometime!
I had originally planned to find a summer research position, but for various reasons, it didn’t happen, so I continued my internship until August.

A photo from my last day. The company environment and atmosphere were great. I’ll be back :)
Knowledge Catch-up and Research
During the internship, besides Python backend, LLM application implementation, and performance evaluation, I was also learning about model architecture, training processes, and other knowledge. Looking back, these are all basic interview questions, satisfied by running an unsloth-implemented LoRA fine-tuning 7B script. Aside from that, because the company needed to research private deployment for a while, I started researching vLLM and similar tools. Forcing myself to learn by outputting, I got involved with DataWhale’s llm-deploy project, responsible for the concurrency part of the tutorial, which helped me fill a large gap in my knowledge of the mlsys field.
However, I was still very confused about my learning and development path. Fortunately, I saw this article on Zhihu:
Quokka: I have no large model experience, can you give me a chance?
Coincidentally, the author works at my dream company, DeepSeek. So, I took the advice he mentioned at the end of the article as a “The Bitter Lesson” of sorts, reading it daily to spur myself on. Let’s check my progress against it now:
- A. Implemented and compared the performance of different pipeline algorithms on two 2080Ti cards: After learning the principles of DeepSpeed and Megatron, I plan to produce some related content soon.
- B. Implemented some operators using Triton: Including but not limited to Nagi ovo: Triton First Taste: Implementing Softmax Forward Kernel. I plan to organize this into a GitHub repo after deeper study recently.
- C. Able to explain the differences in tokenizers used by different large models: Karpathy’s course blog record LLM Evolution (6): Unveiling the Mystery of Tokenizers, implemented BPE and understood some features in tiktoken.
- D. Good development skills in languages other than Python (e.g., endorsed by some open-source projects): Maybe? I’ve gone through Modern C++ and have some frontend/backend development skills, mainly a willingness to learn by doing 🥹.
- E. Implemented a highly effective Gomoku AI (preferably RL algorithm): Nagi ovo: From MCTS to AlphaZero
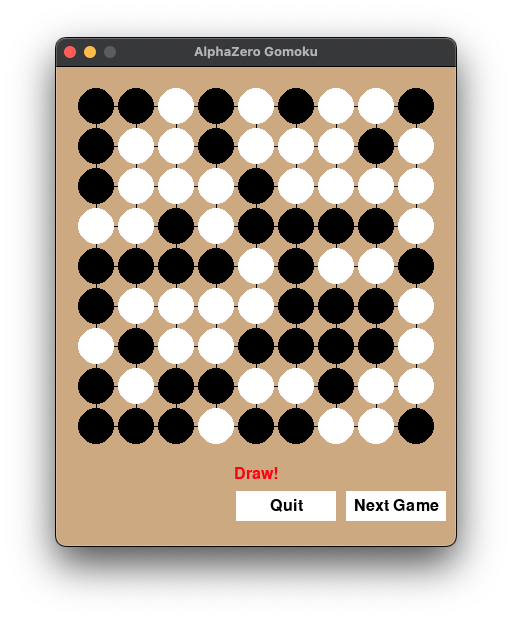
My roommate became a great helper for testing the AI’s chess strength.
I reproduced AlphaZero, and the training results were quite good. This was mainly following the trend of O1 Reasoning, and I already had a strong interest in RL (when I chose the AI major, I thought Artificial Intelligence meant Reinforcement Learning like game AI).
Also fully studied the basics of reinforcement learning to prepare for RLHF, etc.
Having experienced the industry, I wanted a formal research experience. A new AP teacher at my school gave me an opportunity in the CV field (also serving as my graduation project). I’ve been working on it to this day, and I’ll definitely write about this experience specifically after graduation and help promote this super nice teacher 🥳.
After the start of my senior year, I found that my symptoms matched ADHD very well. After basically getting a diagnosis at the hospital, I felt much more at ease, as if I finally had a manual for my body. On the bright side, this is also an advantage that allows me to maintain hyperfocus in fields that interest me.
At the same time, regarding further education, I shifted from doing a one-year master’s to considering a PhD. However, I’m not sure if this choice will provide enough motivation, so I plan to take a gap year for an internship/RA to see slowly (then again, my publications aren’t enough, so maybe I need to settle down for a bit). Of course, knowing myself, whether it’s research or an industry internship, I only want to do valuable work. So if there’s an internship opportunity at my dream company, I might just go all in (one must have dreams, after all, this remains one of my driving forces).
Outlook for 2025
I’ve set this year’s goal as tempering my character. After seeing so many peers and big shots in the same field, it’s hard not to feel anxious. But based on my personal experience, comparing myself only to who I was yesterday makes it easy to fall into a local minimum. Therefore, I need to make a good trade-off between chasing role models and self-improvement.
For Agents, there’s a similar trade-off between long-term planning and local fixed workflows. I hope that while looking as far ahead as possible, I can take every step well, doing even small tasks quickly and well.
As for other things, while outputting blogs, I’ll also manage my Zhihu, Xiaohongshu, and X accounts. Maintaining the ability to express oneself in the GenAI era is also a challenge; after all, daily life can’t be completely handed over to LLMs 🥰.
Solidify foundations, stay curious.
This concludes the annual recollection. Thanks for reading, and I wish everyone a Happy 2025!