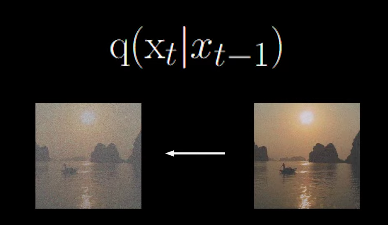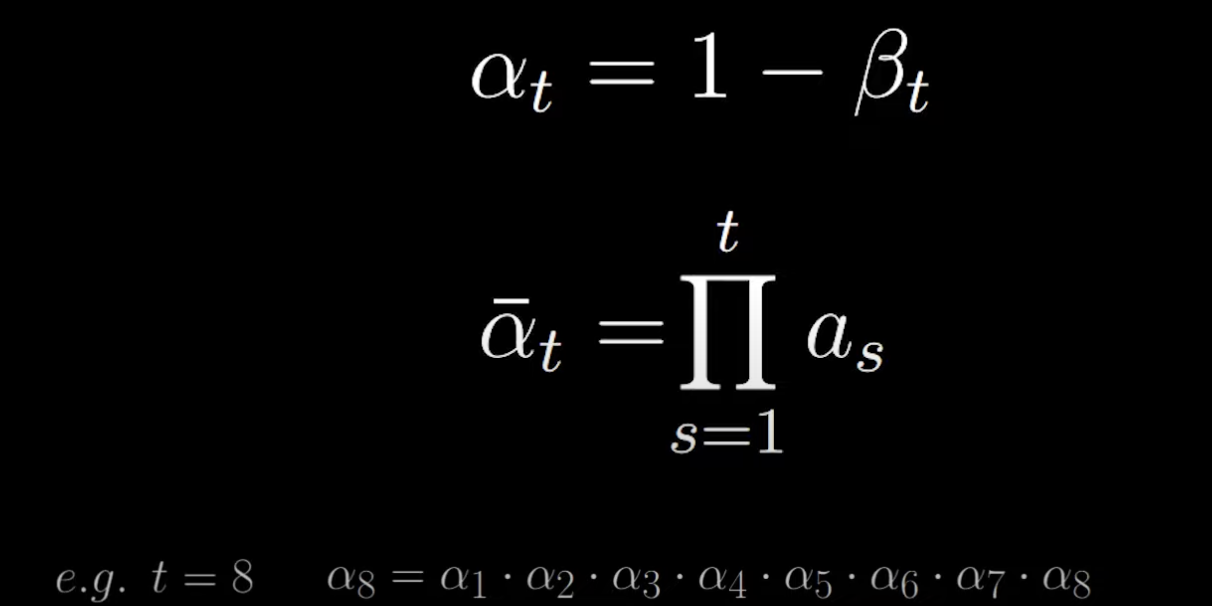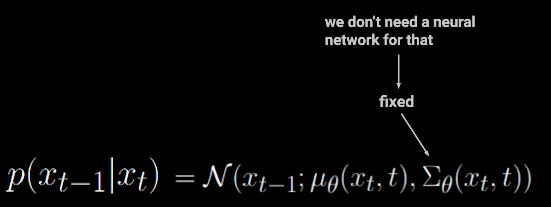Deeply understand the intuitive principles and mathematical derivations of diffusion models, from the forward process to the reverse process, mastering the core ideas and implementation details of DDPM.
40 min read
Deep LearningDiffusion
Human-Crafted
Written directly by the author with no AI-generated sections.
This article primarily follows the teaching logic of this video, organized and elaborated with explanations. If there are any errors, feel free to correct them in the comments!
This paper laid the theoretical foundation for diffusion models. The authors proposed a generative model based on non-equilibrium thermodynamics that achieves data generation by step-wise adding and removing noise. This provided crucial theoretical support for subsequent research in diffusion models.
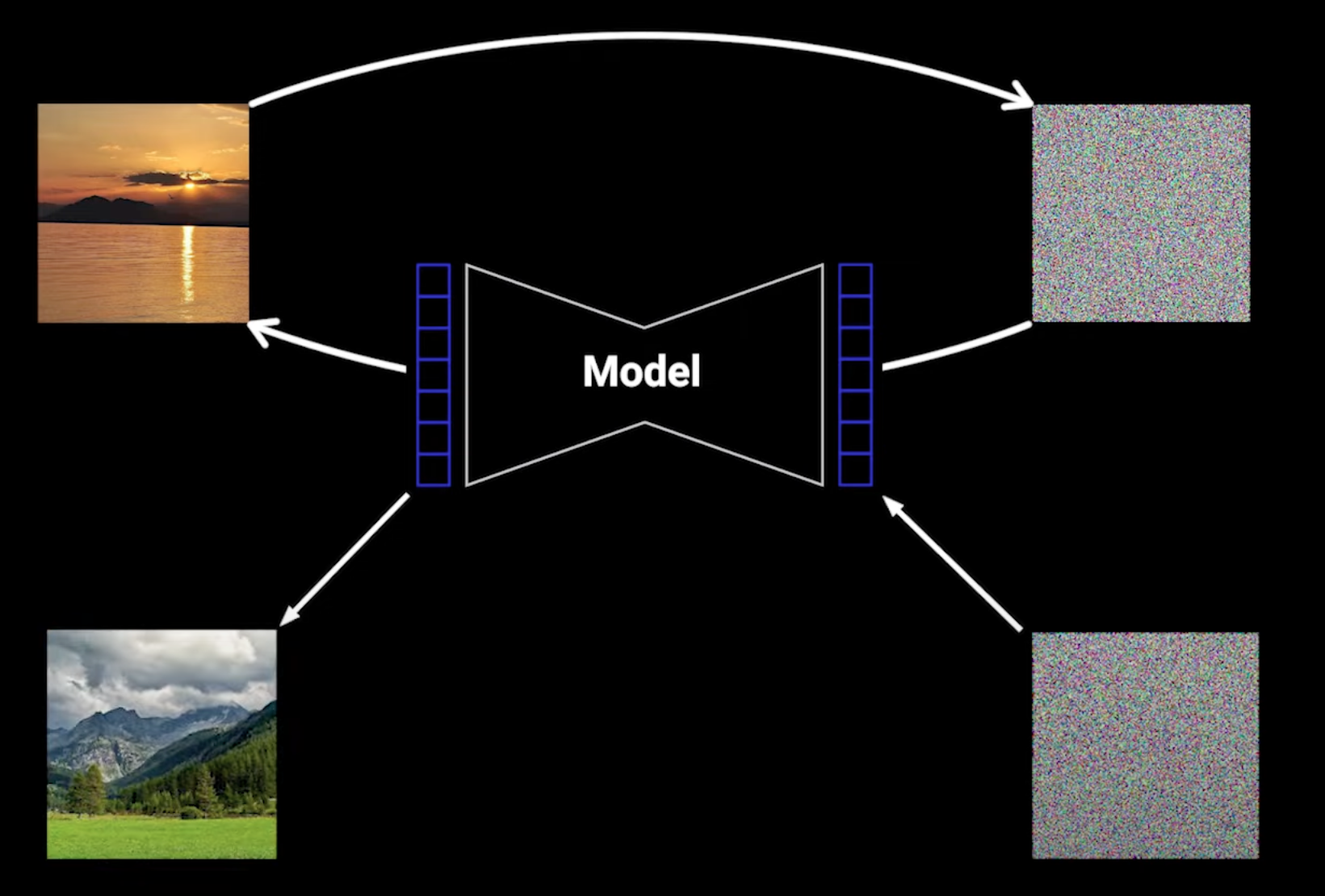
We apply a large amount of noise to images and then use a neural network to denoise them. If this neural network learns well, it can start from completely random noise and eventually obtain an image from our training data.
This paper proposed Denoising Diffusion Probabilistic Models (DDPM), significantly improving the generation quality and efficiency of diffusion models. By introducing a simple denoising network and optimized training strategies, DDPM became an important milestone in the field.
The authors discussed three possible targets for the neural network to predict:
Predict the mean of the noise at each timestep (predict the mean of the noise at each timestep)
Predicting the mean of the conditional distribution p(xt−1∣xt)
Variance is fixed and non-learnable
Predict x0 directly (predict x0 directly)
Directly predicting the original, uncorrupted image
Experiments showed this method performs poorly
Predict the added noise (predict the added noise)
Predicting the noise ε added during the forward process
Mathematically equivalent to the first method (predicting the noise mean), just a different parameterization; they can be transformed into each other through simple operations
The paper ultimately chose predicting noise (the third way) as the primary method because it is more stable to train and yields better results.
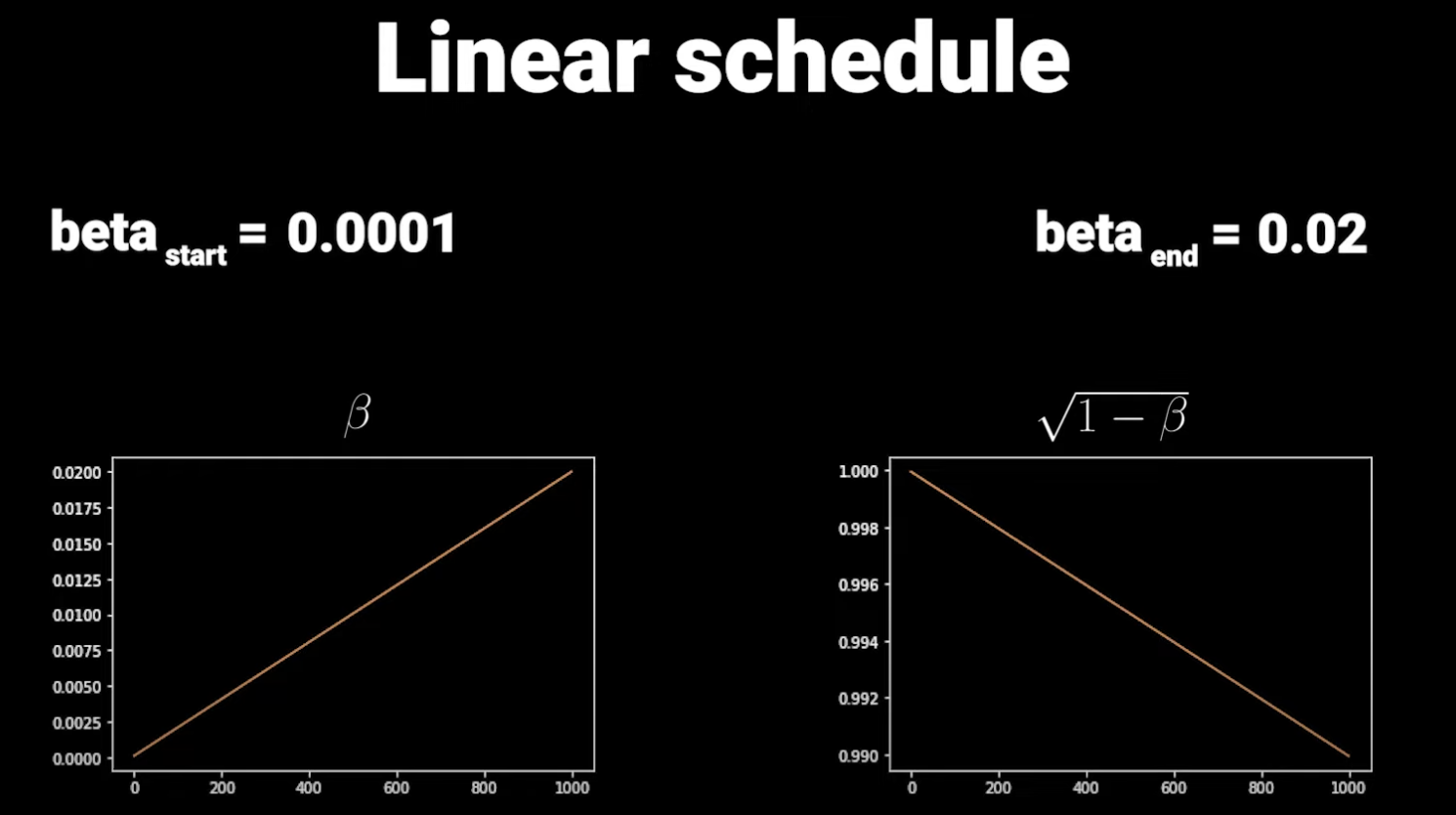
The amount of noise added at each step is not constant; it’s controlled by a Linear Schedule to prevent training instability.
It looks something like this:
As seen, the last few timesteps are close to complete noise with very little information. Furthermore, looking at the whole process, information is destroyed too quickly. OpenAI solved these two problems using a Cosine Schedule:
Published alongside this paper was a model architecture called U-Net:
This model features a Bottleneck in the middle (layers with fewer parameters). It uses Downsample-Blocks and Resnet-Blocks to project the input image to a lower resolution, and Upsample-Blocks to project it back to its original size.
At certain resolutions, the authors added Attention-Blocks and used Skip-Connections between layers in the same resolution space. The model is designed to target each timestep, implemented through sinusoidal positional encoding embeddings from Transformers, which are projected into each Residual-Block. The model can also combine schedules to remove different amounts of noise at different timesteps to improve generation.
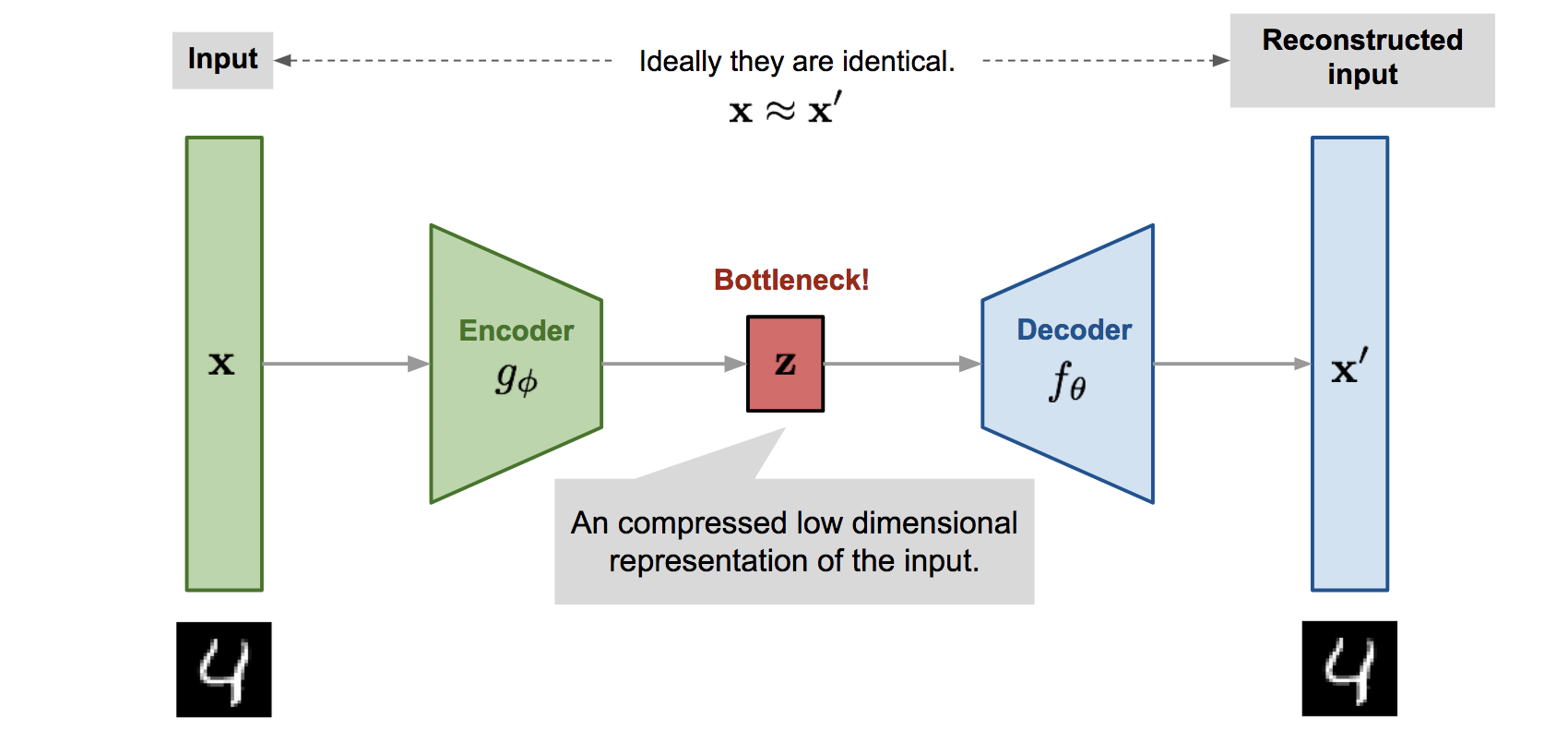
The concept of a Bottleneck was originally proposed and widely used in the unsupervised learning method “Autoencoder.” As the lowest-dimensional hidden layer in an Autoencoder architecture, it sits between the encoder and decoder, forming the narrowest part of the network. This forces the network to learn a compressed representation of data, minimizing reconstruction error and acting as regularization: Lreconstruction=∥X−Decoder(Encoder(X))∥2
Xt represents the image at timestep t, where X0 is the original image. Note that smaller t means less noise:
The final noisy image is an isotropic (same in all directions) total noise, denoted as XT. In initial research T=1000, but later work reduced this significantly:
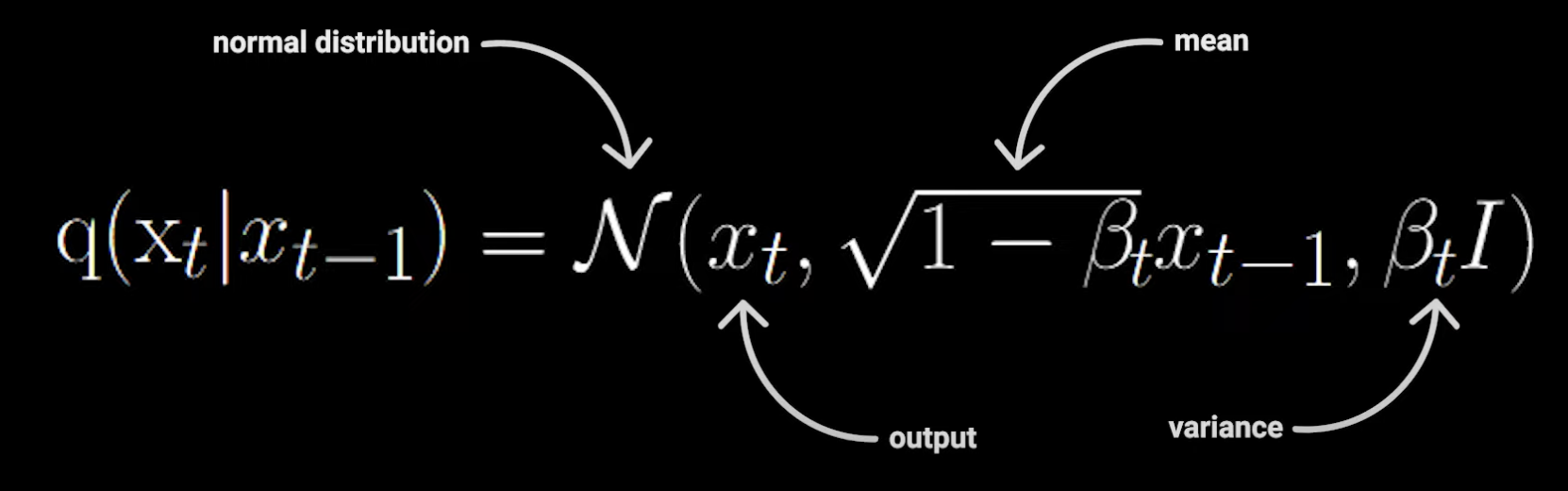
Forward Process: q(xt∣xt−1), taking xt−1 and outputting a noisier image Xt:
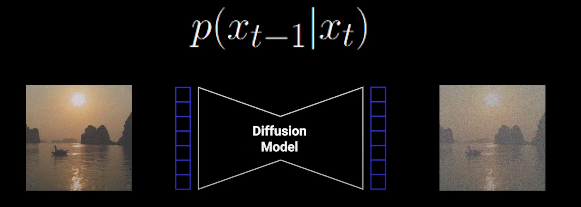
Backward Process: p(xt−1∣xt), taking xt and using a neural network to output a denoised image xt−1:
1−βtxt−1 is the mean of the distribution; βt is the noise schedule parameter, ranging from 0 to 1. Combined with 1−βt, it scales the noise. It decreases as the timestep increases, representing the retained part of the original signal.
βtI is the covariance matrix of the distribution. I is the identity matrix, indicating the covariance matrix is diagonal with independent dimensions. As the timestep increases, the amount of added noise grows.
Now we just need to iteratively execute this step to get the result after 1000 steps, but it can actually be done in one go.
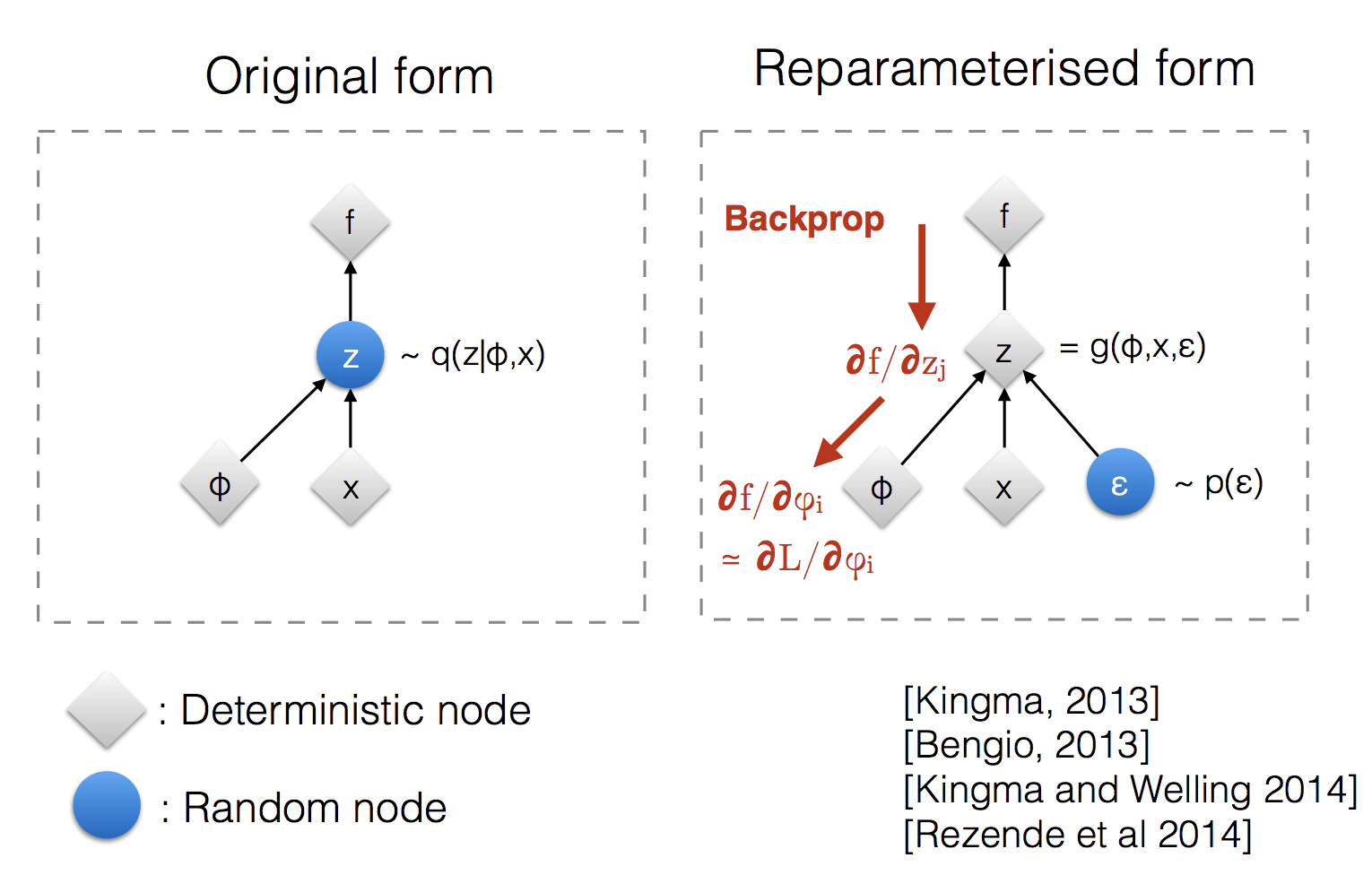
The reparameterization trick is very important in diffusion models and other generative models (like Variational Autoencoders, VAE). Its core idea is transforming the sampling process of a random variable into a deterministic function plus a standardized random variable. This transformation allows the model to be optimized through gradient descent because it eliminates the impact of randomness in the sampling process on gradient calculation.
Here’s a simple example to explain its significance:
There are two ways to implement rolling a die.
The first has randomness inside the function:
# 1. Direct die roll (random sampling)def roll_dice(): return random.randint(1, 6)result = roll_dice()
The second separates randomness outside, keeping the function deterministic:
# 2. Separating randomnessrandom_number = random.random() # Generate random number between 0 and 1def transformed_dice(random_number): # Map 0-1 random number to 1-6 return math.floor(random_number * 6) + 1result = transformed_dice(random_number)
In probability theory, we learn: if X is a random variable and X∼N(0,1), then aX+b∼N(b,a2).
Therefore, for a normal distribution N(μ,σ2), samples can be generated as:
x=μ+σ⋅ϵ
where ϵ∼N(0,1) is the standard normal distribution.
Similarly, for normal distributions:
Without Reparameterization:
# Sample directly from the target normal distributionx = np.random.normal(mu, sigma)
With Reparameterization:
# Sample from standard normal distribution firstepsilon = np.random.normal(0, 1)# Then get the target distribution via deterministic transformationx = mu + sigma * epsilon
When it comes to gradient calculation in model training:
Without Reparameterization:
def sample_direct(mu, sigma): return np.random.normal(mu, sigma)# In this case, it's hard to calculate gradients w.r.t. mu and sigma# because random sampling blocks gradient propagation
With Reparameterization:
def sample_reparameterized(mu, sigma): epsilon = np.random.normal(0, 1) # Gradient doesn't flow through here return mu + sigma * epsilon # Easy to calculate gradients for mu and sigma
Taking VAE as an example:
class VAE(nn.Module): def __init__(self): super(VAE, self).__init__() self.encoder = Encoder() # Outputs mu and sigma self.decoder = Decoder() def reparameterize(self, mu, sigma): # Reparameterization trick epsilon = torch.randn_like(mu) # Sample from standard normal distribution z = mu + sigma * epsilon # Deterministic transformation return z def forward(self, x): # Encoder outputs mu and sigma mu, sigma = self.encoder(x) # Use reparameterization to sample z = self.reparameterize(mu, sigma) # Decoder reconstructs input reconstruction = self.decoder(z) return reconstruction
Applying the reparameterization trick to q(xt∣xt−1)=N(xt;1−βtxt−1,βtI),
∵Σ∴σ=βtI,σ2=βt=βt
We can express xt as a deterministic transformation of xt−1 plus a noise term:
xt=1−βtxt−1+βtϵ
Here, 1−βtxt−1 is the mean part, and βtϵ is the noise part. Since ϵ is a sample from a standard normal distribution and independent of model parameters, gradients only need to consider the parameters corresponding to 1−βt and βt during backpropagation. This allows the model to be effectively optimized via gradient descent.
We use αt to simplify notation and record the cumulative product:
Resulting in:
q(xt∣xt−1)=αtxt−1+1−αtϵ
Calculating a two-step transition: from xt−2 to xt:
Since variance is fixed and doesn’t need learning (see section 1.3), we only need the neural network to predict the mean:
Our ultimate goal is to predict the noise between two timesteps. Let’s start analyzing from the loss function:
−log(pθ(x0))
However, in this negative log-likelihood, the probability of x0 depends on all other preceding timesteps. We can learn a model that approximates these conditional probabilities as a solution. Here we need the Variational Lower Bound to get a more computable formula.
Suppose we have an uncomputable function f(x)—in our case, the negative log-likelihood. We can find a computable function g(x) that always satisfies g(x)≤f(x): Optimizing g(x) will also increase f(x):
We ensure this by subtracting the KL Divergence, a metric that measures the similarity between two distributions, which is always non-negative:
DKL(p∥q)=∫xp(x)logq(x)p(x)dx
Subtracting an always non-negative term ensures the result is always less than the original function. We use ”+” here because we want to minimize the loss, so adding it ensures it’s always greater than or equal to the original negative log-likelihood:
In this form, since the negative log-likelihood is still present, the lower bound remains uncomputable. We need a better expression. First, rewrite the KL divergence as a log ratio of two terms:
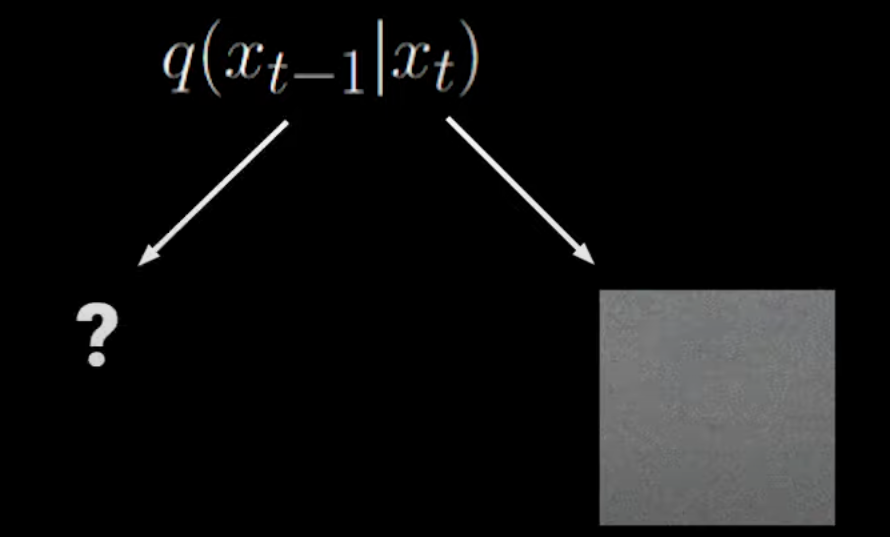
Rewrite the numerator of the sum term using Bayes’ rule: q(xt∣xt−1)=q(xt−1)q(xt−1∣xt)q(xt)
But this goes back to before, where these terms require estimating all samples, leading to high variance. As shown in the image below, given xt, it’s hard to determine what the previous state looked like:
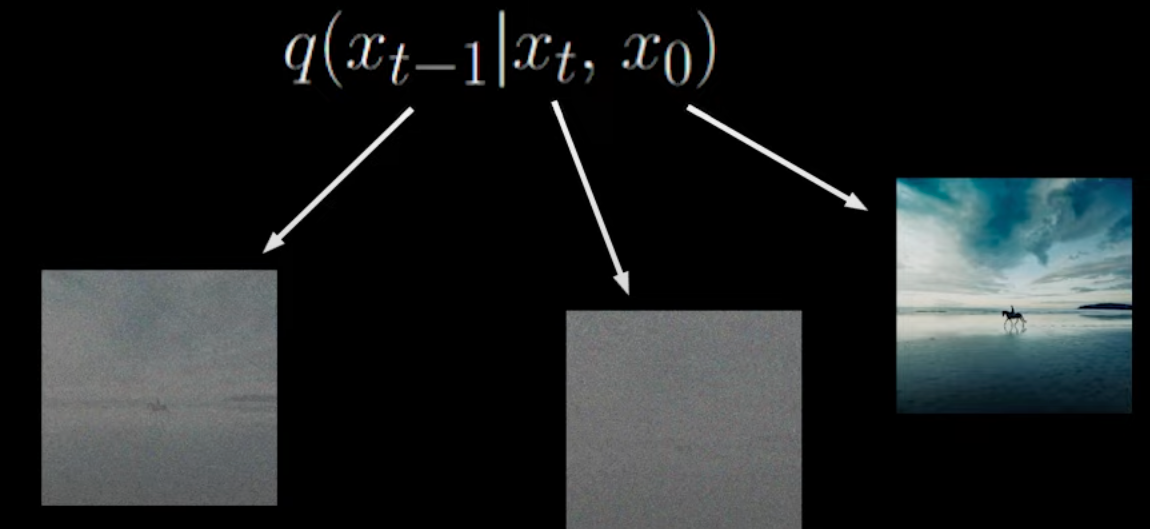
The improvement strategy is to condition directly on the original data x0:
⟹q(xt−1∣x0)q(xt−1∣xt,x0)q(xt∣x0)
By providing the noiseless image simultaneously, there are fewer candidate xt−1 states, reducing variance:
The first term can be ignored because q has no learnable parameters—it’s just the noise-adding forward process that converges to a normal distribution. p(xT) is just noise sampled from a Gaussian distribution, so the KL divergence will be very small.
The derivation of the remaining two terms is as follows (process omitted, see Lilian’s blog for details):
The final form is the mean squared error between the actual noise at timestep t and the noise predicted by the neural network. Researchers found that ignoring the preceding scaling term results in better sampling quality and is easier to implement.
Et,x0,ϵ denotes the expectation over timestep t, original data x0, and noise ϵ.
ϵ is the actual random noise added.
ϵθ is the noise predicted by the neural network.
αˉtx0+1−αˉtϵ is the closed-form solution of the forward process, representing noisy data at timestep t, thus simplifying to:
xt directly represents noisy data at timestep t.
The entire loss function essentially measures the mean squared error between predicted and actual noise.
Timestep t is usually sampled from a uniform distribution (t∼Uniform(1,T)). This choice ensures that during training, every timestep has an equal probability of being selected, allowing the model to effectively learn the denoising process across all timesteps.
First, sample xt from a normal distribution, then sample xt−1 via reparameterization using the formula shown earlier.
Note that no noise is added when t=1. According to the formula:
x0=αt1(x1−1−αˉtβtϵθ(x1,1))
At t=1, the formula is used to recover x0 from x1, the final step of the denoising process. At this point, we want to reconstruct the original image as accurately as possible. Not adding noise at the last step (i.e., no βtϵ term) avoids introducing unnecessary randomness into the final generated image, maintaining clarity and detail.