
I stumbled upon the 'Large Model and AI System Training Camp' hosted by Tsinghua University on Bilibili and signed up immediately. I planned to use the Spring Festival holiday to consolidate my theoretical knowledge of LLM Inference through practice. Coincidentally, the school VPN was down, preventing me from doing research, so it was the perfect time to organize my study notes.
Implementing Simple LLM Inference in Rust
I stumbled upon the Large Model and AI System Training Camp hosted by Tsinghua University on Bilibili and signed up immediately. I planned to use the Spring Festival holiday to consolidate my theoretical knowledge of LLM Inference through practice. Coincidentally, the school VPN was down, preventing me from doing research, so it was the perfect time to organize my study notes.
Regarding the Rust language, I tried to get started twice during my junior year (warned off by some “bible” textbook). This time, I changed my strategy and adopted a dual-track learning approach using rustlings + official documentation, and finally broke through the entry barrier (though only just).
Llama Architecture Analysis
Starting with the core component breakdown, revisiting the classic Transformer architecture design:

RMS Norm
Llama uses a Pre-Norm architecture, performing normalization before the input of each layer. Compared to traditional Layer Norm:
RMSNorm achieves computational optimization by removing mean centering:
where is the learnable scaling parameter gamma, and prevents division by zero errors.
Note: All operators initially only need to implement FP32 support. Later, generics and macros can be used to support inference in other formats.
pub fn rms_norm(y: &mut Tensor<f32>, x: &Tensor<f32>, w: &Tensor<f32>, epsilon: f32) {
let shape = x.shape();
assert!(shape == y.shape());
let feature_dim = shape[shape.len() - 1]; // d in mathematical notation
// Calculate number of feature vectors to process
let num_features = shape[0..shape.len()-1].iter().product();
let _y = unsafe { y.data_mut() };
let _x = x.data();
let _w = w.data();
// Process each feature vector independently
for i in 0..num_features {
let offset = i * feature_dim;
// 1. Calculate Σ(x_i²)
let sum_squares: f32 = (0..feature_dim)
.map(|j| {
let x_ij = _x[offset + j];
x_ij * x_ij
})
.sum();
// 2. Calculate RMS(x) = sqrt(1/d * Σ(x_i²) + ε)
let rms = f32::sqrt(sum_squares / feature_dim as f32 + epsilon);
// 3. Apply normalization and scaling: y_i = (w_i * x_i) / RMS(x)
for j in 0..feature_dim {
let idx = offset + j;
_y[idx] = (_w[j] * _x[idx]) / rms;
}
}
}Rotary Positional Embedding (RoPE)
- Absolute Positional Encoding: Typically constructed via learnable embedding vectors affecting max_length or trigonometric functions, added directly to word vectors. Each position encoding is generally independent.
- Relative Positional Encoding: Learns the distance between a pair of tokens, requiring modifications to attention calculation (e.g., T5 uses a bias embedding matrix to represent relative distance, added to the Q, K matrices of self-attention). It can extend to arbitrary sequence lengths, but inference speed is slower and difficult to utilize KV-Cache.
- Rotary Positional Embedding (RoPE) combines the advantages of absolute and relative positional encoding. The 2D case formula is as follows:
Before the rotation matrix is applied, a linear transformation is applied to obtain Query & Key to maintain rotation invariance. Then, passing through the rotation matrix rotates the word vector by degrees ( is the absolute position of the token in the sentence):
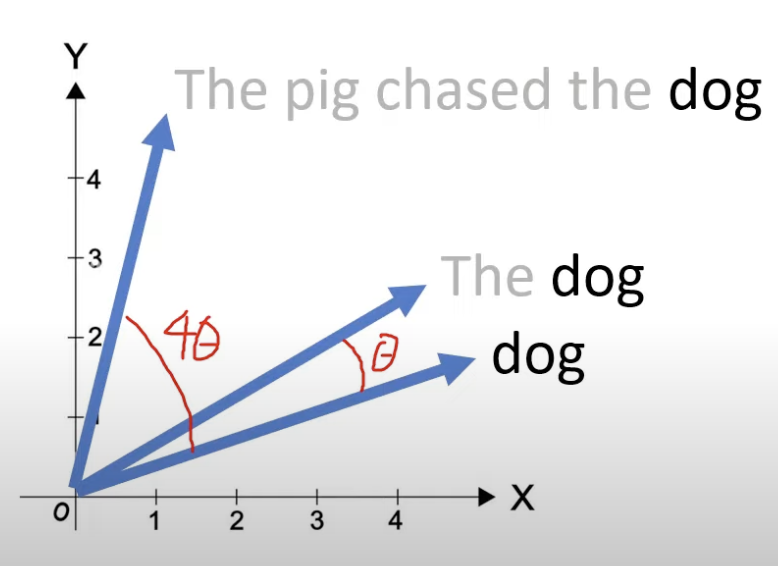
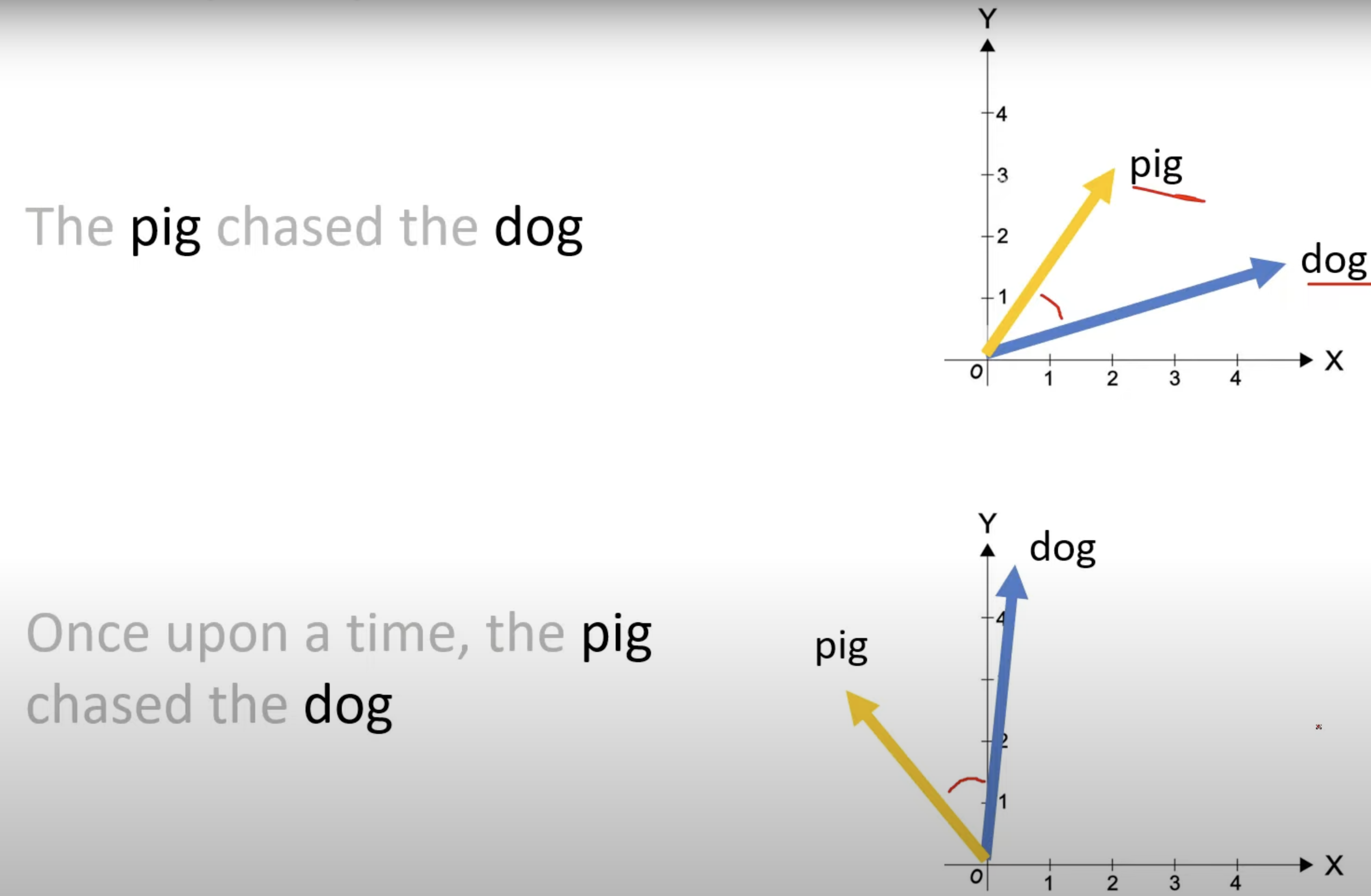
A more general form is as follows, splitting the vector into multiple groups of 2D chunks (assuming the vector dimension is even by default), and then applying different rotation angles to each pair of dimensions in groups:
To optimize computational efficiency, the above calculation is equivalent to:

The implementation here is given in the repository:
// RoPE: Rotary Positional Embedding
pub fn rope(y: &mut Tensor<f32>, start_pos: usize, theta: f32) {
let shape = y.shape();
assert!(shape.len() == 3);
let seq_len = shape[0];
let n_heads = shape[1];
let d = shape[2];
let data = unsafe { y.data_mut() };
for tok in 0..seq_len {
let pos = start_pos + tok;
for head in 0..n_heads {
// Traverse dimension pairs
for i in 0..d / 2 {
let a = data[tok * n_heads * d + head * d + i];
let b = data[tok * n_heads * d + head * d + i + d / 2];
let freq = pos as f32 / theta.powf((i * 2) as f32 / d as f32);
let (sin, cos) = freq.sin_cos();
// Apply rotation matrix
data[tok * n_heads * d + head * d + i] = a * cos - b * sin;
data[tok * n_heads * d + head * d + i + d / 2] = b * cos + a * sin;
}
}
}
}FFN (MLP)
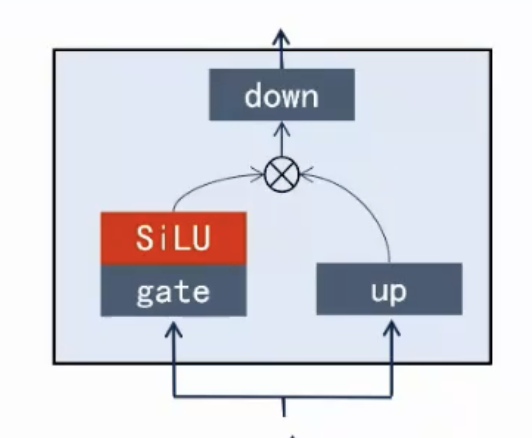
MLP Structure (src/model.rs):
fn mlp(
residual: &mut Tensor<f32>,
hidden_states: &mut Tensor<f32>,
gate: &mut Tensor<f32>,
up: &mut Tensor<f32>,
w_up: &Tensor<f32>,
w_down: &Tensor<f32>,
w_gate: &Tensor<f32>,
rms_w: &Tensor<f32>,
eps: f32,
) {
// 1. hidden = rms_norm(residual)
OP::rms_norm(hidden_states, residual, rms_w, eps);
// 2. gate = hidden @ gate_weight.T
OP::matmul_transb(gate, 0., hidden_states, w_gate, 1.0);
// 3. up = hidden @ up_weight.T
OP::matmul_transb(up, 0., hidden_states, w_up, 1.0);
// 4. act = gate * sigmoid(gate) * up (SwiGLU)
OP::swiglu(up, gate);
// 5. residual = residual + up @ down_weight.T
OP::matmul_transb(residual, 1.0, up, w_down, 1.0);
}Operators
The basic computational operations involved in the entire process are shown in the figure:

MatMul (scr/operators.rs):
// C = beta * C + alpha * A @ B^T
// hint: You don't need to do an explicit transpose of B
pub fn matmul_transb(c: &mut Tensor<f32>, beta: f32, a: &Tensor<f32>, b: &Tensor<f32>, alpha: f32) {
// C_xy = beta * C_xy + alpha * Σ(A_xk * B_yk) k=1..inner_dim
let shape_a = a.shape();
let shape_b = b.shape();
let (a_rows, b_rows) = (shape_a[0], shape_b[0]);
let inner = shape_a[1];
let _c = unsafe { c.data_mut() };
let _a = a.data();
let _b = b.data();
// 1. using slice to scale C
_c.iter_mut().for_each(|val| *val *= beta);
// 2. using slice to matmul
for x in 0..a_rows {
// get current row of A
let a_row = &_a[x * inner..(x + 1) * inner];
for y in 0..b_rows {
// get current row of B (equivalent to column of B^T)
let b_row = &_b[y * inner..(y + 1) * inner];
let sum: f32 = a_row.iter()
.zip(b_row.iter())
.map(|(&a, &b)| a * b)
.sum();
_c[x * b_rows + y] += alpha * sum;
}
}
}SwiGLU (scr/operators.rs)
, where
// hint: this is an element-wise operation
pub fn swiglu(y: &mut Tensor<f32>, x: &Tensor<f32>) {
let len = y.size();
assert!(len == x.size());
let _y = unsafe { y.data_mut() };
let _x = x.data();
for i in 0..len {
_y[i] = _y[i] * _x[i] / (1. + f32::exp(-_x[i]));
}
}Reading from safetensor
(src/params.rs)
use crate::config::LlamaConfigJson;
use crate::tensor::Tensor;
use num_traits::Num;
use safetensors::SafeTensors;
pub struct LLamaParams<T: Num> {
// token_id to embedding lookup table
pub embedding_table: Tensor<T>, // (vocab_size, dim)
// decoder layer
pub rms_att_w: Vec<Tensor<T>>, // (hidden_size, ) x layers
pub wq: Vec<Tensor<T>>, // (n_heads * head_size, hidden_size) x layers
pub wk: Vec<Tensor<T>>, // (n_kv_heads * head_size, hidden_size) x layers
pub wv: Vec<Tensor<T>>, // (n_kv_heads * head_size, hidden_size) x layers
pub wo: Vec<Tensor<T>>, // (hidden_size, n_heads * head_size) x layers
// ffn layer
pub rms_ffn_w: Vec<Tensor<T>>, // (hidden_size, ) x layers
pub w_up: Vec<Tensor<T>>, // (intermediate_size, hidden_size) x layers
pub w_gate: Vec<Tensor<T>>, // (intermediate_size, hidden_size) x layers
pub w_down: Vec<Tensor<T>>, // (hidden_size, intermediate_size) x layers
// output
pub rms_out_w: Tensor<T>, // (hidden_size, )
pub lm_head: Tensor<T>, // (vocab_size, dim)
}
trait GetTensorFromSafeTensors<P: Num> {
fn get_tensor_from(tensors: &SafeTensors, name: &str) -> Result<Tensor<P>, &'static str>;
}
impl GetTensorFromSafeTensors<f32> for f32 {
fn get_tensor_from(tensors: &SafeTensors, name: &str) -> Result<Tensor<f32>, &'static str> {
let tensor_view = tensors.tensor(name).map_err(|e| {
assert!(matches!(e, safetensors::SafeTensorError::TensorNotFound(_)));
"Tensor not found"
})?;
let data = match tensor_view.dtype() {
safetensors::Dtype::F32 => tensor_view.data()
.chunks_exact(4)
.map(|b| f32::from_le_bytes([b[0], b[1], b[2], b[3]]))
.collect(),
_ => return Err("Unsupported data type"),
};
Ok(Tensor::new(data, &tensor_view.shape().to_vec()))
}
}
macro_rules! get_tensor_vec {
($tensors:expr, $pattern:literal, $layers:expr) => {{
(0..$layers)
.map(|i| {
let name = format!($pattern, i);
f32::get_tensor_from($tensors, &name).unwrap()
})
.collect::<Vec<_>>()
}};
}
impl LLamaParams<f32> {
pub fn from_safetensors(safetensor: &SafeTensors, config: &LlamaConfigJson) -> Self {
let embedding_table = if config.tie_word_embeddings {
f32::get_tensor_from(safetensor, "lm_head.weight").unwrap()
} else {
f32::get_tensor_from(safetensor, "model.embed_tokens.weight").unwrap()
};
let n_layers = config.num_hidden_layers;
Self {
embedding_table,
rms_att_w: get_tensor_vec!(safetensor, "model.layers.{}.input_layernorm.weight", n_layers),
wq: get_tensor_vec!(safetensor, "model.layers.{}.self_attn.q_proj.weight", n_layers),
wk: get_tensor_vec!(safetensor, "model.layers.{}.self_attn.k_proj.weight", n_layers),
wv: get_tensor_vec!(safetensor, "model.layers.{}.self_attn.v_proj.weight", n_layers),
wo: get_tensor_vec!(safetensor, "model.layers.{}.self_attn.o_proj.weight", n_layers),
rms_ffn_w: get_tensor_vec!(safetensor, "model.layers.{}.post_attention_layernorm.weight", n_layers),
w_up: get_tensor_vec!(safetensor, "model.layers.{}.mlp.up_proj.weight", n_layers),
w_gate: get_tensor_vec!(safetensor, "model.layers.{}.mlp.gate_proj.weight", n_layers),
w_down: get_tensor_vec!(safetensor, "model.layers.{}.mlp.down_proj.weight", n_layers),
rms_out_w: f32::get_tensor_from(safetensor, "model.norm.weight").unwrap(),
lm_head: f32::get_tensor_from(safetensor, "lm_head.weight").unwrap(),
}
}
}KV-Cache Mechanism
KV cache usage calculation during fp16 (parameter takes 2 bytes) inference:
As the sequence length increases, performance declines exponentially (note the incremental calculation for the latest token generation):

Corresponding parameters use_cache: true and max_position_embeddings: 4096, the latter determining the model’s maximum context window.
Inference Optimization Schemes
Grouped Query Attention (GQA)
Memory optimization achieved by sharing a single group of KV across multiple groups of Q (requires head count divisibility relation):
Batching techniques, session management, dialog rollback, etc., are not implemented due to lack of energy for now, and will only be summarized for educational purposes later.
Mixed Precision Inference
Commonly used are FP16 and BF16. The former has the same precision as TF32, while the latter has the same range as FP32 but lower precision. TF32 combines the range of FP32 and the precision of FP16, but requires tensor core hardware support.

Note that the following precision-sensitive operations typically need to retain FP32:
- Trigonometric calculations in RoPE
- Exponential operations in RMS Norm
- Softmax numerical stability
Quantized Inference
Achieved through data type mapping:
- Computation acceleration (requires hardware support for low-precision instructions)
- VRAM optimization (fp16 requires only 50% of fp32 space, or even int8, int4…)

Advanced Optimization Directions
- MoE Architecture: Dynamic routing MLP optimization
- Distributed Inference:
- Data Parallelism: Full parameter copy, increasing throughput
- Pipeline Parallelism: Inter-layer splitting, sensitive to communication overhead
- Tensor Parallelism: Distributed parameter storage, requires AllGather/AllReduce synchronization

Summary
This training camp used hard-core practice to connect the technical context of LLM inference optimization. It is very worthwhile to continue advancing the implementation when I have time later. Recently, there have been too many things to do, so I will just wrap it up hastily here 🥲