
学习知识蒸馏的基本原理,了解如何将大模型(教师)的知识传递给小模型(学生),实现模型压缩和加速。
知识蒸馏入门学习
本文将尝试结合:
- 入门 Demo:Knowledge Distillation Tutorial — PyTorch Tutorials
- 进阶学习:MIT 6.5940 Fall 2024 TinyML and Efficient Deep Learning Computing的第九章
知识蒸馏是一种技术,它使得从大型、计算成本高的模型向较小模型转移知识成为可能,而不会失去有效性。这使得可以在性能较低的硬件上部署,从而使评估更快、更高效。预仅集中在其权重上,而不是其前向传播。

定义模型 class 和 utils
使用两种不同的架构,在实验中保持 filters 的数量不变,以确保公平比较。这两种架构都是 CNN,具有不同数量的卷积层作为特征提取器,后面跟着一个具有 10 个类别的分类器(CIFAR10)。学生的 filters 和参数量较少。
教师网络
Deeper neural network class
class DeepNN(nn.Module):
def __init__(self, num_classes=10):
super(DeepNN, self).__init__()
# 4 层卷积层,卷积核 128、64、64、32
self.features = nn.Sequential(
nn.Conv2d(3, 128, kernel_size=3, padding=1),
nn.ReLU(), # 3 × 3 × 3 × 128 + 128 = 3584
nn.Conv2d(128, 64, kernel_size=3, padding=1),
nn.ReLU(), # 3 × 3 × 128 × 64 + 64 = 73792
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.ReLU(), # 3 × 3 × 64 × 64 + 64 = 36928
nn.Conv2d(64, 32, kernel_size=3, padding=1),
nn.ReLU(), # 3 × 3 × 64 × 32 + 32 = 18464
nn.MaxPool2d(kernel_size=2, stride=2),
)
# 输出的特征图尺寸:2048,全连接层有 512 个神经元
self.classifier = nn.Sequential(
nn.Linear(2048, 512),
nn.ReLU(), # 2048 × 512 + 512 = 1049088
nn.Dropout(0.1),
nn.Linear(512, num_classes) # 512 × 10 + 10 = 5130
)
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x总参数量:1,177,986
学生网络
Lightweight neural network class
class LightNN(nn.Module):
def __init__(self, num_classes=10):
super(LightNN, self).__init__()
# 2 层卷积层,卷积核:16、16
self.features = nn.Sequential(
nn.Conv2d(3, 16, kernel_size=3, padding=1),
nn.ReLU(), # 3 × 3 × 3 × 16 + 16 = 448
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(16, 16, kernel_size=3, padding=1),
nn.ReLU(), # 3 × 3 × 16 × 16 + 16 = 2320
nn.MaxPool2d(kernel_size=2, stride=2),
)
# 输出的特征图尺寸:1024,全连接层有 256 个神经元
self.classifier = nn.Sequential(
nn.Linear(1024, 256),
nn.ReLU(), # 1024 × 256 + 256 = 262400
nn.Dropout(0.1),
nn.Linear(256, num_classes) # 256 × 10 + 10 = 2570
)
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x总参数量:267,738,比教师网络约少 4.4 倍

使用交叉熵训练两个网络。学生将作为基准使用:
def train(model, train_loader, epochs, learning_rate, device):
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
model.train()
for epoch in range(epochs):
running_loss = 0.0
for inputs, labels in train_loader:
# inputs:一批 batch_size 张图像的集合
# lables:一个维度为 batch_size 的向量,其中的整数表示每张图像所属的类别
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
# outputs:网络对这批图像的输出。一个维度为 batch_size x num_classes 的张量
# labels:图像的实际标签。一个维度为 batch_size 的向量
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f"Epoch {epoch+1}/{epochs}, Loss: {running_loss / len(train_loader)}")
def test(model, test_loader, device):
model.to(device)
model.eval()
correct = 0
total = 0
with torch.no_grad():
for inputs, labels in test_loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = 100 * correct / total
print(f"Test Accuracy: {accuracy:.2f}%")
return accuracy运行交叉熵
torch.manual_seed(42)
nn_deep = DeepNN(num_classes=10).to(device)
train(nn_deep, train_loader, epochs=10, learning_rate=0.001, device=device)
test_accuracy_deep = test(nn_deep, test_loader, device)
# 实例化学生网络
torch.manual_seed(42)
nn_light = LightNN(num_classes=10).to(device)教师网络的性能:Test Accuracy: 75.01%
反向传播对权重初始化敏感,因此我们需要确保这两个网络具有完全相同的初始化。
torch.manual_seed(42)
new_nn_light = LightNN(num_classes=10).to(device)为了确保我们已经创建了第一个网络的副本,我们检查其第一层的 norm。如匹配则两个网络确实是相同的。
# 打印初始轻量级模型第一层的 norm
print("Norm of 1st layer of nn_light:", torch.norm(nn_light.features[0].weight).item())
# 打印新的轻量级模型第一层的 norm
print("Norm of 1st layer of new_nn_light:", torch.norm(new_nn_light.features[0].weight).item())输出结果:
Norm of 1st layer of nn_light: 2.327361822128296 Norm of 1st layer of new_nn_light: 2.327361822128296
total_params_deep = "{:,}".format(sum(p.numel() for p in nn_deep.parameters()))
print(f"DeepNN parameters: {total_params_deep}")
total_params_light = "{:,}".format(sum(p.numel() for p in nn_light.parameters()))
print(f"LightNN parameters: {total_params_light}")DeepNN parameters: 1,186,986 LightNN parameters: 267,738
和我们前面手算的结果一致。
用交叉熵损失训练和测试学生网络
train(nn_light, train_loader, epochs=10, learning_rate=0.001, device=device)
test_accuracy_light_ce = test(nn_light, test_loader, device)学生网络的性能(没受到教师干预):Test Accuracy: 70.58%
知识蒸馏(软目标)
目标是 matching output logits
尝试通过引入教师来提高学生网络的测试准确性。
[! 术语介绍] 知识蒸馏是一种技术,最基本的方式是通过将教师网络的 softmax 输出作为额外损失,与传统的交叉熵损失一起用于训练学生网络。假设是教师网络的输出激活携带了额外信息,可以帮助学生网络更好地学习数据的相似性结构。交叉熵仅关注最高预测(未预测类别的激活值往往很小),而知识蒸馏利用整个输出分布的信息,包括较小概率的类别,从而更有效地构建理想的向量空间。
这里给上面提到的相似性结构举另一个例子:在 CIFAR-10 中,如果卡车的轮子存在,它可能会被误认为是汽车或飞机,但不太可能被误认为是狗

可以看到小模型的 logits 不够自信,我们的动机就是增大其对 cat 的预测。

模型模式设置
蒸馏损失是从网络的 logits 中计算得出的,它只返回对学生的梯度,教师模型的权重在蒸馏过程中不会更新。我们只使用它的输出作为指导信息。
def train_knowledge_distillation(teacher, student, train_loader, epochs, learning_rate, T, soft_target_loss_weight, ce_loss_weight, device):
ce_loss = nn.CrossEntropyLoss()
optimizer = optim.Adam(student.parameters(), lr=learning_rate)
teacher.eval() # 将教师模型设置为评估模式
student.train() # 将学生模型设置为训练模式
for epoch in range(epochs):
running_loss = 0.0
for inputs, labels in train_loader:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()前向传播与教师输出
通过 with torch.no_grad() 确保教师模型的前向传播不计算梯度。节省内存和计算资源,因为教师模型的权重不需要更新。
# 使用教师模型进行前向传播
with torch.no_grad():
teacher_logits = teacher(inputs)学生模型前向传播
学生模型对相同的输入进行前向传播,生成它的预测值 student_logits。这些 logits 将用于计算两种损失:软目标损失(蒸馏损失) 和 真实标签的交叉熵损失。
# 使用学生模型进行前向传播
student_logits = student(inputs)软目标损失
- 软目标(soft targets) 是通过将教师的 logits 除以温度参数
T然后应用softmax得到的。这使得教师模型的输出分布更加平滑。 - 学生模型的软概率(soft prob) 是通过对学生 logits 除以
T并应用log_softmax计算的。

温度 T > 1 则教师输出概率分布更平滑,学生能够学到更多类别之间的相似性。
# 通过先应用 softmax 再应用 log() 来软化学生模型的 logits
soft_targets = nn.functional.softmax(teacher_logits / T, dim=-1)
soft_prob = nn.functional.log_softmax(student_logits / T, dim=-1)使用 KL 散度来计算教师和学生的输出分布之间的差异。T**2 是《Distilling the knowledge in a neural network》论文中提到的缩放因子,用于平衡软目标的影响。
该损失衡量学生模型的预测与教师模型的预测之间的差异,通过最小化这个损失,推动学生模型更好地模仿教师模型的表示。
# 计算软目标损失。
soft_targets_loss = torch.sum(soft_targets * (soft_targets.log() - soft_prob)) / soft_prob.size()[0] * (T**2)真实标签损失(交叉熵损失)
# 计算真实标签损失
label_loss = ce_loss(student_logits, labels)- 这里计算的是传统的 交叉熵损失,它根据真实标签(labels)来评估学生模型的输出。
- 这个损失推动学生模型正确地分类数据。
加权总损失
总损失是 软目标损失 和 真实标签损失 的加权和。这里的 soft_target_loss_weight 和 ce_loss_weight 分别控制两种损失的权重。
# 两个损失的加权和
loss = soft_target_loss_weight * soft_targets_loss + ce_loss_weight * label_loss在这里 soft_target_loss_weight 是 0.25,ce_loss_weight 是 0.75,意味着真实标签的交叉熵损失在总损失中占据更大的权重。
反向传播和权重更新
通过反向传播,计算损失相对于学生模型权重的梯度,然后使用 Adam 优化器来更新学生模型的权重。这个过程通过不断最小化损失,逐渐优化学生模型的性能。
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f"Epoch {epoch+1}/{epochs}, Loss: {running_loss / len(train_loader)}")
在训练结束后,通过测试不同条件下学生模型的准确性来评估知识蒸馏的效果。
# 设置温度 T=2, CE 损失权重为 0.75,蒸馏损失权重为 0.25。
train_knowledge_distillation(teacher=nn_deep, student=new_nn_light, train_loader=train_loader, epochs=10, learning_rate=0.001, T=2, soft_target_loss_weight=0.25, ce_loss_weight=0.75, device=device)
test_accuracy_light_ce_and_kd = test(new_nn_light, test_loader, device)
# 比较学生在有无教师指导下的测试准确率
print(f"Teacher accuracy: {test_accuracy_deep:.2f}%")
print(f"Student accuracy without teacher: {test_accuracy_light_ce:.2f}%")
print(f"Student accuracy with CE + KD: {test_accuracy_light_ce_and_kd:.2f}%")知识蒸镏(隐藏层特征图)
目标是 matching intermediate features
知识蒸馏不再仅仅局限于对输出层的软目标进行蒸馏,还可以对某一特征提取层的隐藏表示进行蒸馏。我们的目标是利用一个简单的损失函数将教师的表示信息传递给学生,该损失函数最小化意味着传递给分类器的扁平化向量在损失减少时变得更加相似。教师不会更新其权重,因此最小化仅依赖于学生的权重。

基本原理是,假设教师模型具有更好的内部表示,而学生在没有外部干预的情况下不太可能实现,因此我们推动学生模仿教师的内部表示。然而,这并不保证对学生有益,因为轻量级网络可能难以达到教师的表示,且不同架构的网络学习能力不同。换句话说,学生的向量与教师的向量按组件匹配并无必然理由,学生可能达到教师内部表示的排列。尽管如此,我们仍可进行快速实验以评估此方法的影响。我们将使用 CosineEmbeddingLoss,其公式如下:
隐藏层表示不匹配的问题
- 教师模型通常比学生模型更复杂,有更多的神经元和更高维度的表示。因此,经过卷积层后的 flattened(扁平化)隐藏表示在维度上往往不一致。
- 问题:为了将教师模型的隐藏层输出用于蒸馏损失计算(如 CosineEmbeddingLoss),我们需要确保学生模型和教师模型的输出维度一致。
解决方法:应用池化层
- 教师网络的隐藏层表示在卷积层之后被扁平化后,维度通常比学生的高。因此,使用了 average pooling(平均池化) 来降低教师网络的输出维度,使其与学生网络一致。
- 具体地,代码中
avg_pool1d函数将教师网络的隐藏层表示通过池化减少为学生网络的相同维度。
def forward(self, x):
x = self.features(x)
flattened_conv_output = torch.flatten(x, 1)
x = self.classifier(flattened_conv_output)
# 对齐两个网络的特征表示
flattened_conv_output_after_pooling = torch.nn.functional.avg_pool1d(flattened_conv_output, 2)
return x, flattened_conv_output_after_pooling新增了余弦相似度的损失计算。通过计算教师和学生的中间特征表示的余弦相似度损失,目标是让学生的特征表示更加接近教师的特征表示。
cosine_loss = nn.CosineEmbeddingLoss()
hidden_rep_loss = cosine_loss(student_hidden_representation, teacher_hidden_representation, target=torch.ones(inputs.size(0)).to(device))由于 ModifiedDeepNNCosine 和 ModifiedLightNNCosine 网络返回的是两个值,即网络输出 logits 和中间特征表示 hidden_representation,因此在训练时,既需要提取这两个值,也需要分别处理它们。
with torch.no_grad():
_, teacher_hidden_representation = teacher(inputs)
student_logits, student_hidden_representation = student(inputs)将计算的余弦损失和分类的交叉熵损失进行加权求和,分别用 hidden_rep_loss_weight 和 ce_loss_weight 来控制它们的权重。最终的总损失由两部分组成:一部分是学生网络的分类误差(交叉熵),另一部分是中间特征层与教师的特征表示的相似度(余弦损失)。
loss = hidden_rep_loss_weight * hidden_rep_loss + ce_loss_weight * label_loss回归器网络
简单的最小化方法并不能保证更好的结果,原因包括向量维度高,提取有意义的相似性困难,且无理论支持教师和学生隐藏表示的匹配。我们将引入回归器网络,提取教师和学生在卷积层后的特征图,并通过回归器匹配这些特征图。回归器可训练,旨在优化匹配过程,定义教师和学生间的损失函数,提供反向传播梯度的教学路径,改变学生权重。

特征图提取
在 ModifiedDeepNNRegressor 中,网络前向传播过程不仅返回分类器的输出 logits,还返回特征提取器的中间特征图 conv_feature_map。这允许我们在训练过程中使用这些特征图进行蒸馏,将学生网络的特征图与教师网络的特征图进行比较,从而提升学生网络的表现。
conv_feature_map = x
return x, conv_feature_map通过这些特征图,教师和学生网络的蒸馏不再局限于最终的 logits 输出,而是利用网络内部的中间特征表示进行蒸馏。预计最终的方法将比 CosineLoss 效果更好,因为我们现在在教师和学生之间引入了一个可训练的层,为学生在学习时提供了灵活性,而不是强迫学生复制教师的表示。包含额外的网络是基于提示的蒸馏背后的理念。
知识蒸镏(拓展)

还可以 match 权重,如:
- 梯度(Gradients): 如注意力图 (Attention Maps),在 Transformer 模型中,注意力图表示模型关注的输入部分。匹配注意力图可以帮助学生模型学习到教师模型的注意力机
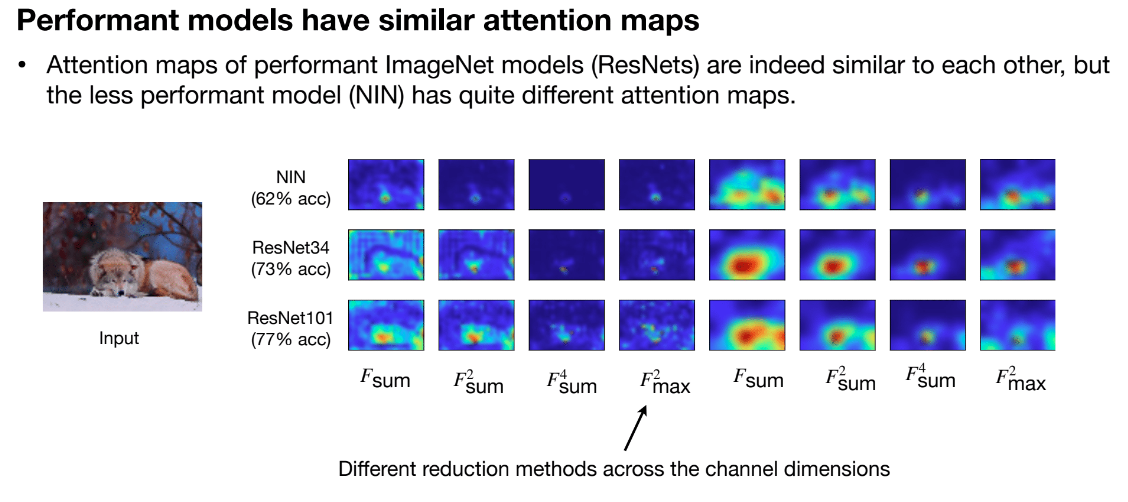


- 稀疏性模式 (Sparsity Patterns): 教师网络和学生网络在 ReLU 激活之后应该具有相似的稀疏性模式。如果某个神经元在 ReLU 激活函数后其值大于 0,则该神经元被视为激活。使用指示函数 来表示神经元的激活状态:。通过匹配这些稀疏性模式,学生模型可以学习到教师模型的权重或激活值的稀疏结构,从而提高模型的效率和泛化能力。

- 关系信息 (Relational Information):
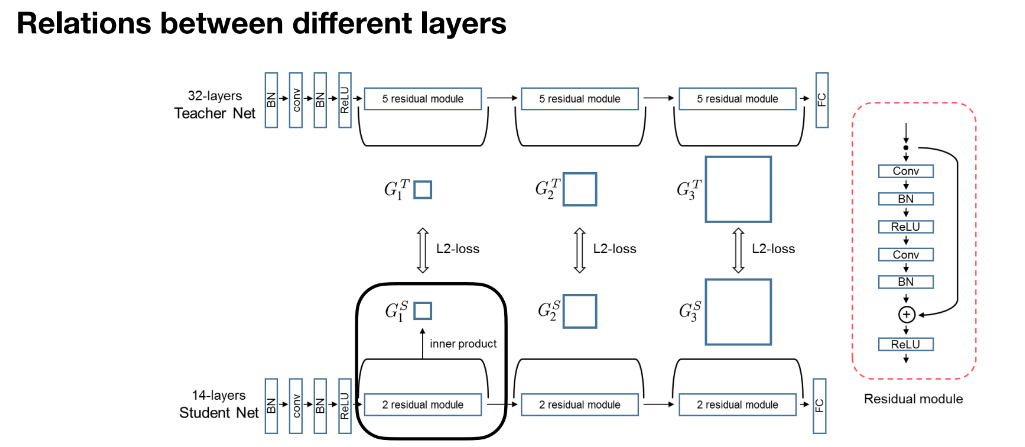
通过内积计算教师网络和学生网络不同层之间的关系。每层的输出用矩阵表示,通过匹配教师和学生网络的层间关系来进行蒸馏。使用 L2 损失,将教师和学生在各层之间的关系进行对齐,使得网络层的特征分布相匹配。


传统的知识蒸馏仅针对一个输入样本进行特征或 logits 的匹配,而 Relational Knowledge Distillation 关注多个样本之间的关系。通过比较教师网络和学生网络中不同样本的特征之间的关系,构建样本之间的结构。这种方法关注多个输入样本之间的关联,而不仅是单个样本的点对点匹配。

方法进一步扩展,计算学生和教师网络在不同样本集上的成对距离,利用这些关系信息来进行蒸馏。通过构建样本集的特征向量间距矩阵,将样本之间的结构信息传递给学生网络。与个体知识蒸馏不同,此方法在多个样本之间传递结构关系。